python+selenium excel中文读取填充到网页
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python+selenium excel中文读取填充到网页相关的知识,希望对你有一定的参考价值。
由于我技术水平,磨磨唧唧很长时间终于弄出来了,在整理的时候思考了下,可能是我当时太关注打印出来的list了 ,list里不能显示中文,我就初以为我总是错了。
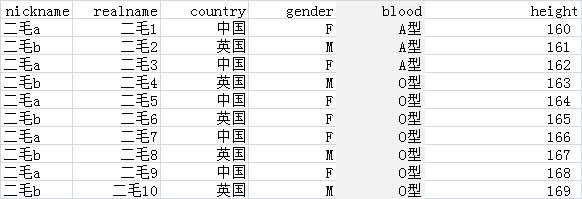
附上表格一部分
#coding:utf-8 import xlrd def open_excel(file): try: data = xlrd.open_workbook(file) return data except Exception as e: print (str(e)) def excel_table_byindex(file,colnameindex = 0,by_index= 0): data = open_excel(file) table = data.sheets()[by_index] nrows = table.nrows #行 colnames = table.row_values(colnameindex) #列内容 list=[] for rownum in range(1, nrows): row = table.row_values(rownum) if row: app = {} for i in range(len(colnames)): s = row[i]
# if isinstance(s, unicode): # s = row[i].encode("utf-8") print "每一个", s app[colnames[i]] = s list.append(app) print row print list return list listdata=excel_table_byindex("E:\\py\\\\alwaystry\\sign_up.xlsx",0)
在开头加了#coding:utf-8 ,就已经是utf-8格式的了,所以能处理中文。
打印print "每一个", s 的时候,打印出来是 每一个 二毛a
print row 打印出来是[u‘\\u4e8c\\u6bdba‘,...
print list 打印出来就是[{u‘nickname‘: u‘\\u4e8c\\u6bdba‘..., 所有的行数据。
当初的我只看到了Unicode编码就以为他是打印不了中文了,其实是list不能显示。现在想来,还是太嫩
在漫长的探索中,我知道了str和Unicode
(我看着觉得不错的网址http://wklken.me/posts/2013/08/31/python-extra-coding-intro.html)
反正就是
str -> decode(‘str的编码格式‘) -> unicode
unicode -> encode(‘你要的格式‘) -> str
要查看编码格式,就print chardet.detect(listdata[i][‘nickname‘]),判断字符编码格式当然还是要import chardet的
他有时候会报ValueError: Expected a bytes object, not a unicode object错,那也就知道他是什么编码格式了。
还是这样吧,直接打印格式:print type(listdata[i][‘realname‘])打印输出<type ‘unicode‘>,说明人家已经是unicode,那你就把chardet.detect()删掉就好。
UTF-8是Unicode的实现方式之一/utf8是对unicode字符集进行编码的一种编码方式。(当时做笔记记下来的,我觉得这两句话还是蛮好理解的)
如果,很不慎,你走到了和我当初一样的境地,早早的把encode,就是注释掉的那两句。
提示UnicodeDecodeError: ‘utf8‘ codec can‘t decode byte 0xe4 in position 0: unexpected end of data等等,不妨尝试一下decode。如果是下拉框匹配的情况,可以先decode再encode试试,下面代码最后一行。
整体大概代码如下
#输入网址 address = raw_input(‘Enter location: ‘) if len(address) < 1: print "error" url = address #放你的配置文件 profile_dir = r"C:\\Users\\Administrator\\AppData\\Roaming\\Mozilla\\Firefox\\Profiles\\5cmfbcqp.default" profile = webdriver.FirefoxProfile(profile_dir) driver = webdriver.Firefox(profile) #打开excel def open_excel(): try: data = xlrd.open_workbook(file) return data except Exception as e: print (str(e)) def excel_table_byindex(file,colnameindex = 0,by_index= 0): data = open_excel(file) table = data.sheets()[by_index] nrows = table.nrows #行 colnames = table.row_values(colnameindex) #列内容 list=[] for rownum in range(1, nrows): row = table.row_values(rownum) if row: app = {} for i in range(len(colnames)): s = row[i] if isinstance(s, unicode): s = row[i].encode("utf-8") print s app[colnames[i]] = s list.append(app) print (list) return list #通过css判断是否存在,你也可以用if else def judgewithcss(css): try: driver.find_element_by_css_selector(css) except: return False return True listdata=excel_table_byindex("E:\\sign_up.xlsx",0) if(len(listdata)<0): assert 0,u"数据异常" for i in range(0, len(listdata)): driver.get(url) #昵称,这是个input if judgewithcss("#nickname") == True: nickname = driver.find_element_by_id("nickname") nickname.clear() print chardet.detect(listdata[i][‘nickname‘]) nickname.send_keys(listdata[i][‘nickname‘].decode("utf-8")) #血型,这是个select if judgewithcss("#blood") == True: blood = driver.find_element_by_id("blood") # 以下3种也能判断出格式 # print isinstance(listdata[i][‘blood‘], unicode) # print isinstance(listdata[i][‘blood‘], str) # print type(listdata[i][‘blood‘]) print chardet.detect(listdata[i][‘blood‘]) Select(blood).select_by_value(listdata[i][‘blood‘].decode("windows-1252").encode("windows-1252"))
以上是关于python+selenium excel中文读取填充到网页的主要内容,如果未能解决你的问题,请参考以下文章
Selenium2+python自动化58-读取Excel数据(xlrd)
Selenium2+python自动化58-读取Excel数据(xlrd)
selenium+python自动化测试--读取excel数据
Selenium2+python自动化58-读取Excel数据(xlrd)转载