python网络爬虫怎么学习
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python网络爬虫怎么学习相关的知识,希望对你有一定的参考价值。
链接:https://pan.baidu.com/s/1wMgTx-M-Ea9y1IYn-UTZaA
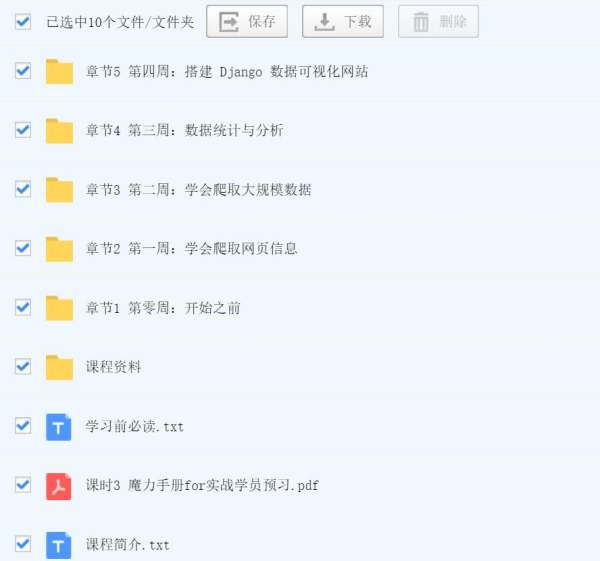
课程简介
毕业不知如何就业?工作效率低经常挨骂?很多次想学编程都没有学会?
Python 实战:四周实现爬虫系统,无需编程基础,二十八天掌握一项谋生技能。
带你学到如何从网上批量获得几十万数据,如何处理海量大数据,数据可视化及网站制作。
课程目录
开始之前,魔力手册 for 实战学员预习
第一周:学会爬取网页信息
第二周:学会爬取大规模数据
第三周:数据统计与分析
第四周:搭建 Django 数据可视化网站
......
参考技术A 现行环境下,大数据与人工智能的重要依托还是庞大的数据和分析采集,类似于淘宝 京东 百度 腾讯级别的企业 能够通过数据可观的用户群体获取需要的数据,而一般企业可能就没有这种通过产品获取数据的能力和条件,想从事这方面的工作,需掌握以下知识:1. 学习Python基础知识并实现基本的爬虫过程
一般获取数据的过程都是按照 发送请求-获得页面反馈-解析并且存储数据 这三个流程来实现的。这个过程其实就是模拟了一个人工浏览网页的过程。
Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,我们可以按照requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。
2.了解非结构化数据的存储
爬虫抓取的数据结构复杂 传统的结构化数据库可能并不是特别适合我们使用。我们前期推荐使用MongoDB 就可以。
3. 掌握一些常用的反爬虫技巧
使用代理IP池、抓包、验证码的OCR处理等处理方式即可以解决大部分网站的反爬虫策略。
4.了解分布式存储
分布式这个东西,听起来很恐怖,但其实就是利用多线程的原理让多个爬虫同时工作,需要你掌握 Scrapy + MongoDB + Redis 这三种工具就可以了。 参考技术B 你好,学习Python编程语言,是大家走入编程世界的最理想选择。Python比其它编程语言更适合人工智能这个领域,在人工智能上使用Python比其它编程有更大优势。无论是学习任何一门语言,基础知识,就是基础功非常的重要,找一个有丰富编程经验的老师或者师兄带着你会少走很多弯路, 你的进步速度也会快很多,无论我们学习的目的是什么,不得不说Python真的是一门值得你付出时间去学习的优秀编程语言。在选择培训时一定要多方面对比教学,师资,项目,就业等,慎重选择。 参考技术C

1、设置cookies,事实上,cookie是一些存储在用户终端中的加密数据。
一些网站通过cookies识别用户身份。如果一个访问者总是频繁地发送请求,它可能会被网站注意到并被怀疑是爬虫类。此时,网站可以通过cookie找到访问者并拒绝访问。
有两种方法可以解决这个问题。一是定制cookie策略,防止cookierejected问题,二是禁止cookies。
2、修改IP。事实上,微博识别的是IP,而非帐号。
也就是说,当需要连续获取大量数据时,模拟登录是没有意义的。只要是同一个IP,怎么换账号都没用。关键在于IP地址。
网站应对爬虫的策略之一是直接关闭IP或整个IP段,禁止访问。关闭IP后,转换到其他IP继续访问,需要使用代理IP。
获得IP地址的方法有很多种,最常用的方法是从代理IP网站获得大量的优质IP。如太阳HTTP此类应用IDC五星级运营标准,SLA99.99%,AES加密在线数据技术,自营服务器遍布全国,是一个不错的选择。
3、修改User-Agent。
User-Agent是指包含浏览器信息、操作系统信息等的字符串,
也称为特殊的网络协议。服务器判断当前的访问对象是浏览器、邮件客户端还是网络爬虫类。
具体的方法是将User-Agent的值改为浏览器,甚至可以设置一个User-Agent池(list,数组,字典都可以),存储多个浏览器,每次爬取一个User-Agent设置request,使User-Agent不断变化,防止被屏蔽。
参考技术D 确保自己有一定 Python 基础后,可以适当了解 http 协议,推荐<图解HTTP>,然后就是多看多练善于使用工具爬网页数据的时候,一定要熟练使用开发者工具,一个 f12 就可以打开浏览器的开发者工具,这一步就是你爬虫的第一步,上来就去教你爬数据的,基本上都是坑,都没有分析一下目标网页,拿什么去爬.学习《从零开始学Python网络爬虫》PDF+源代码+《精通Scrapy网络爬虫》PDF
学习网络爬虫,基于python3处理数据,推荐学习《从零开始学Python网络爬虫》和《精通Scrapy网络爬虫》。
《从零开始学Python网络爬虫》是基于Python 3的图书,代码挺多,如果是想快速实现功能,这本书是一个蛮好的选择。
《精通Scrapy网络爬虫》基于Python3,深入系统地介绍了Python流行框架Scrapy的相关技术及使用技巧。
学习参考:
《从零开始学Python网络爬虫》PDF,279页,带目录,文字可复制;
配套源代码,教学PPT。作者: 罗攀 / 蒋仟
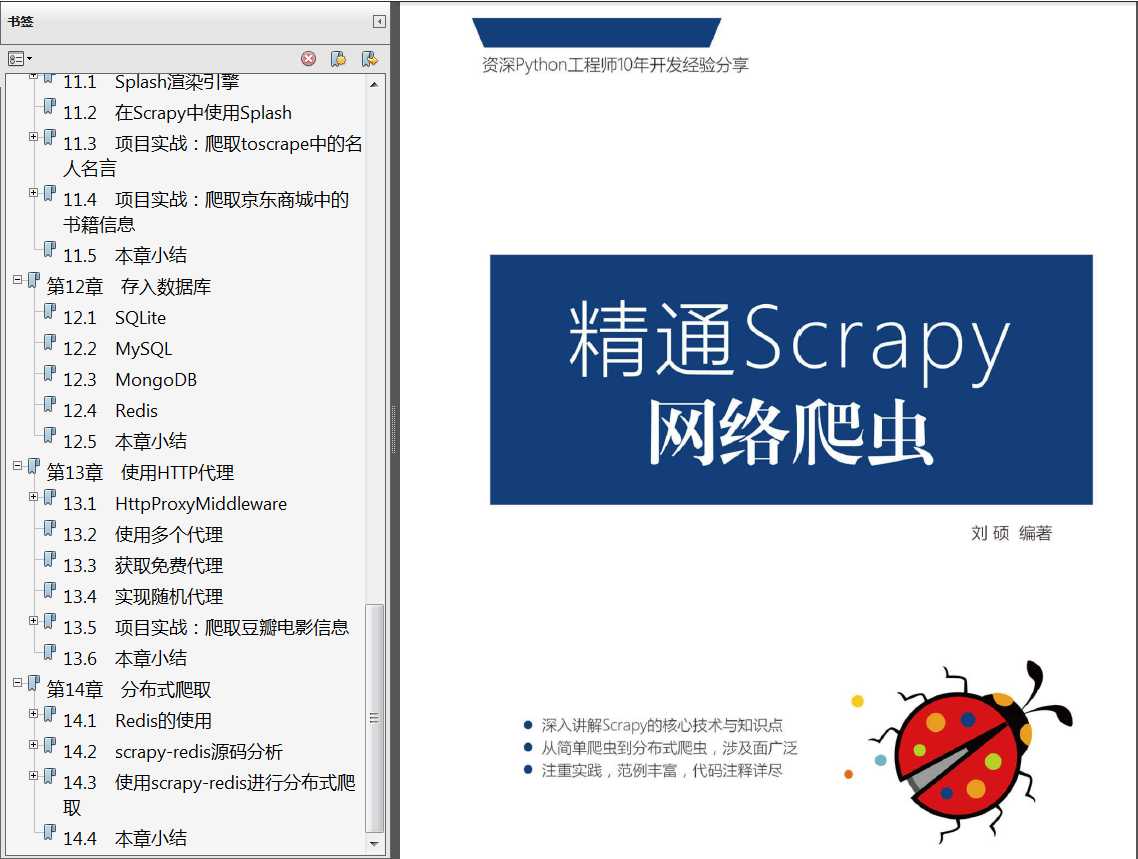
《精通Scrapy网络爬虫》PDF,254页,带目录,文字可复制。作者: 刘硕
下载:https://pan.baidu.com/s/1NWd6w8pCHORBx4BFsw7cnQ
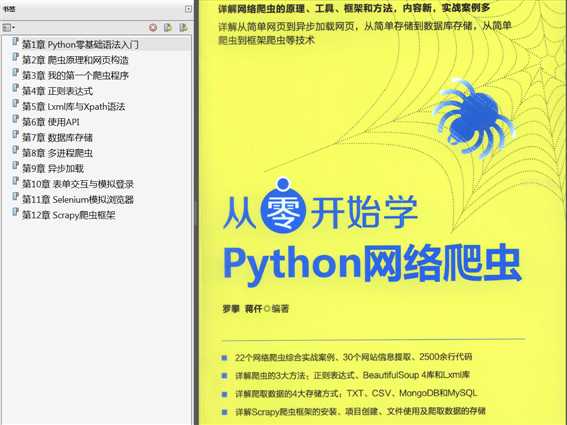
《从零开始学Python网络爬虫》是一本教初学者学习如何爬取网络数据和信息的入门读物。书中不仅有Python的相关内容,
而且还有数据处理和数据挖掘等方面的内容。内容非常实用,讲解时穿插了22个爬虫实战案例,可以大大提高读者的实际动
手能力。共分12章,核心主题包括Python零基础语法入门、爬虫原理和网页构造、第壹个爬虫程序、正则表达式、Lxml库与
Xpath语法、使用API、数据库存储、多进程爬虫、异步加载、表单交互与模拟登录、Selenium模拟浏览器、Scrapy爬虫框架。

此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制作方法,让读者体验数据背后的乐趣。
全书共14章,从逻 辑上可分为基础篇和高级篇两部分,基础篇重点介绍Scrapy的核心元素,如spider、selector、item、link等;高级篇讲解爬虫 的高级话题,如登录认证、文件下载、执行JavaScript、动态网页爬取、使用HTTP代理、分布式爬虫的编写等,并配合项目案 例讲解,包括供练习使用的网站,以及知乎、豆瓣、360爬虫案例等。 案例丰富,注重实践,代码注释详尽,适合有一 定Python语言基础,想学习编写复杂网络爬虫的读者使用。
配合这本书学习,效果会更好。
《Python网络数据采集》高清中文PDF英文PDF源代码:https://pan.baidu.com/s/1DLOCZm8MnGALfXF7g_KtQw
以上是关于python网络爬虫怎么学习的主要内容,如果未能解决你的问题,请参考以下文章
个人怎么利用爬虫技术赚钱-Java网络爬虫系统性学习与实战系列