python内置string模块
Posted MyRecords
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python内置string模块相关的知识,希望对你有一定的参考价值。
1 内置string长量
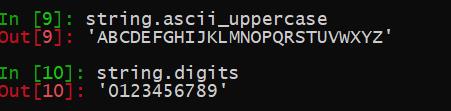
所有的ASCII字母
string.ascii_letters
所有的ASCII小写字母
string.ascii_lowercase
所有的ASCII大写字母
string.ascii_uppercase
数字0-9
string.digits
上面的常量输出都是str类型

2 str.maketrans(x[, y[, z]]) 和str.translate()
maketrans()和translate()原来是属于内置的string模块,后来maketrans变为字符串的静态方法,translate为字符串方法
maketrans返回一个可供 str.translate() 使用的转换对照表
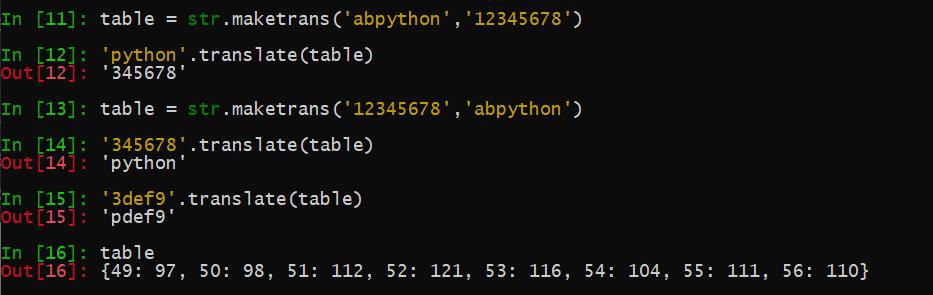
如上,maketrans中的两个参数都是字符串且长度相等,前字符串的每个字符对应到后字符串对应位置上的字符
也就是说该方法返回一个密码本,\'1\'对应\'a\',\'2\'对应\'b\',以此类推。 这时如果截获了敌人的一段电报,内容是"345678",如果我们知道该电报采用的加密方法即密码本table,就可以用translate来解密成原文

如上没有在转换对照表的字符不会被转换
maketrans,如果有两个参数,则它们必须是两个长度相等的字符串,前面参数是待转换字符串,后面参数是目标字符串
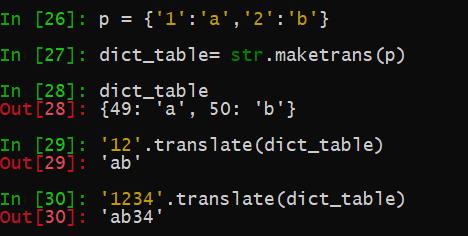
如果只有一个参数,则它必须是一个将 Unicode 码位序号(整数)或字符(长度为 1 的字符串)映射到 Unicode 码位序号、(任意长度的)字符串或 None 的字典。 字符键将会被转换为码位序号
如果有第三个参数,它必须是一个字符串,其中的字符将在结果中被映射到 None
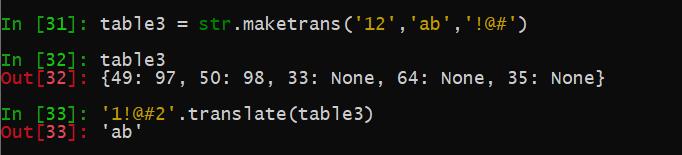
如上,maketrans第三个参数的字符在translate时被转换成None,前面两个参数和传递2个参数的情况是相同的
3 string.punctuation
ASCII 字符中一些常见的标点符号
结合translate()可以从字符串中删除标点符号

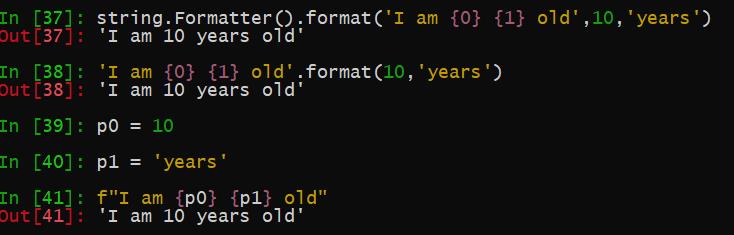
4 Formatter类的format方法

这和直接在字符串采用format方法或者采用f开头的字符串是一样的,
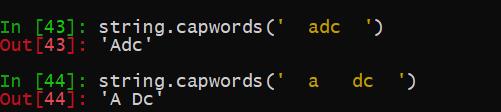
5 其他常量等

python内置方法
目录
内置对象方法汇总
- 字符串String
- list(可变序列)
- 元组Tuple(不可变序列)
4.字典和集合 - Set(无序不重复)
内置对象方法汇总
常用内置对象的方法
String
定义,切片,长度,替换,编列.....
列表/元组
定义,使用,循环遍历......
字典
定义,使用,循环遍历.......
集合Set
连接数据库!
各种内置模块
os,file,re,time,json.......
- 字符串String
定义: 一串字符! 用 ""或‘‘ 引起来! 字符串是字符串列表,索引从0开始!
字符串是字符串的列表! 可以通过索引访问,索引从0开始,-1表示最后一个
索引不能操作范围!
字符串不可变!
编列
+表示连接: 控制台input()方法输入的内容都是字符串!
切片 [开始:结束:步长] [::-1]倒序
格式化字符串
name = tom
age = 20
方法1.使用占位符格式化
print("名字:%s,年龄:%d"%(name,age))
方法2:格式化
print(f"名字:{name},年龄:{age}")
方法3:格式化
print("名字:{0}年龄{1}".format(name,age))
转义
‘ 转义
制表符等于4个空格(Tab)
换行
linux换行
续行(该行还未结束,下一样继续)
chr()
内置方法
len(字符串) # 长度
chr() 转化为字符 chr(97)--a chr(65)--A
ord(字符)转化为对应ASCII编码 ord(‘A‘)-->65
find(字符) 找不到返回-1
index(字符)找不到报错
replace(‘老字符串‘,‘新字符串‘) 替换
splite(‘字符‘) 拆分 返回列表!
lower(字符串) 转为小写
upper(字符) 转为大写
strip(字符串) 去掉两遍空格 rstrip(字符串) 去掉右边空格 lstrip(字符串)去左边
not in ‘hello‘ 判断是否存在!
赋值
s = ‘hello‘
s[0] --->第一个
s[-1] --->最后一个
字符串不可变
s = ‘helloWorld‘
s[5] =‘w‘ #报错 str not support item assignment
遍历
str01=‘hello‘
for i in hello:
print(i)
编列索引和值
for i,v in enumerate(str01):
print(f‘第{i},个值:{v}‘)
生成a-z
print(chr(random.choice(range(97,123))))
A-Z
print(chr(random.choice(range(65,91))))
image-20201030155819095
- list(可变序列)
有序的元素集合! 可以通过索引访问元素! 正向第1个索引为0,反向第1个是-1
常见的序列类型
列表 list. 可变
元组 tuple
范围 range
image-20201031142639473
方法介绍
方法 说明
len(列表) 列表长度
列表名[i] 根据索引找 list01[-1] 最后一个
列表名[开始,介绍,步长] 切片
- 列表相加,创建新列表! [1,2]+[4,5]=[1,2,4,5]
max(列表) 返回最大 max([1,2,3])
min(列表) 返回最小
列表.index(元素) 返回元素第一次出现位置 找不到报错!
列表.count(元素) 统计出现总次数
[表达式 for x in 列表] 列表推倒式,返回新列表
列表[i] 根据索引找值
列表[:]
原列表[::]=新列表 替换原列表中所有值
in 和 not in 判断是否包含,返回True或False
[1,2,3]*3 重复3遍 [1,2,3,1,2,3,1,2,3]
list(带转化的序列) 转化为列表 list(‘hello‘)
list.append(元素) 追加1个值
list.extend(列表) 合并另一个列表,扩充原列表 和+结果一样!原理不同
list.insert(i,元素) 指定位置插入
list.pop() 删除并返回最后一个!
list.remove(元素) 移除第一次出现的
list.reverse() 翻转
list.sort(reverse=True) 排序,默认正序从小到大!reverse参数倒序
1. 定义
list01 = ‘hello‘
2. 取第一个
print(list01[0])
2. 取最后一个
print(list01[-1])
print(list01[len(list01)-1])
3. 长度
print(len(list01))
4. 切片
print(list01[0,3]) #前2个!
list01= [1,2,3,4,5]
print(list01[2,4]) # 结果3,4
print(list01[-4,-1]) # 不包含-1位置的! 从-4位置开始,2往后取 -->2,3,4
5. 列表相加
list01= [‘A‘,‘B‘]
list02= [1,2]
print(list01+list02)# ===>[‘A‘,‘B‘,1,2] 必须都是列表!
6,列表推倒式
list01= [1,2,3]
list02 = [i+3 for i in list01]
print(list01) # 4,5,6
7. 替换
list01= [1,3,5]
list01[0]= 10 #替换一个
list01[::] = [4,6,9] # 替换
print(list01)# 4,6,9
8.追加
list01=[1,2,3]
list02=[4,5.6]
list01.extend(list02) #===> [1,2,3,4,5,6] 扩充原列表!
- 元组Tuple(不可变序列)
元组合列表一样都是内存中一段连续的存储空间! 有顺序的!
元组不能修改!
创建
t1 = (1,2,3) # 语法1 常用!
t2 = tuple(1,2,3) # 语法2
t2 = tuple([1,2,3,3]) # 语法3
不能重新赋值
t1 = (12,13,35)
t1[0]=3
TypeError: ‘tuple‘ object does not support item assignment # 元组项不支持重新赋值!
不能删除元素!
字符串,列表,元祖转化
str() # 字符串可转化为列表和元祖!
list()/tuple() 相互转化!
range(开始,结束,步长
for i in range(0,10): # range 返回的数据类型
print(i) #0到9
4.字典和集合
字典存储成对存在数据! {key1:value1, k2:v2,.....}
集合: 无序,不重复!
基本语法: {key1:value,key2:value,....}
列表和字典区别
1. 列表时有序的! 字典无序!
2. 检索方式不同: 列表查找通过索引,字典通过key ! key格式是字符串!
key是字符串或数值! key是不可变类型!
key不能重复! 重复会自动覆盖!
增加/修改
d1 = {}
d1[‘name‘]=‘张三‘ #增加
d1[‘age‘]=20 # 增加
d1[‘name‘]=‘小A‘ # 修改!
字典推倒式/列表推倒式
d1 = {x:x**2 for i in (1,2,3)}
结果: {1:1,2:4,3:9}
取值: 字典[‘key‘] 或 字典.get(key)
判断key是否存在!! ‘python2.x中 has_key(key)‘
d2= {‘name‘: ‘AA‘, ‘age‘:20}
if ‘sex‘ in d2:
print(‘存在‘)
for...in 遍历
d1 ={‘name‘:‘张三‘,‘age‘:20,‘sex‘:‘男‘}
# keys()获取所有键 values()所有值
for k in d1.keys():
print(f‘名字{k},值:{d1[k]}‘)
print(d1.values())
print(d1.items())
# 同时编列key,value
for k,v in d1.items():
print(f‘名字{k},值:{v}‘)
删除: del 字典/字典[key]
清空 保留存储空间,clear()
删除pop(key)
更新一项update({key:value})
- Set(无序不重复)
集合Set中存储的数据是无序的,而且不能重复!
题目list排重!: 删除某个list中的重复项? [1,20,22,31,423,1,......]
image-20201102163134289
li = [1,1,5,5,8,8]
set(li)===>搞定!
作业: 测试两个方法效率? 数据量大时排重效率高的方法!
Set: 可变集合
frozenset : 不可变集合
创建
创建(常用)
s1 = {1,2,3,3} # 结果 (1,2,3)
关键字创建
s2= set([1,2,3])
s3= frozenset([1,2,3])
编列
s1 ={‘a‘,‘b‘,‘c‘}
for i in s1:
....
是否存在: in/not in
增加集合.add(元素)
删除集合.remove(元素) 集合.clear()清空 集合.pop()
删除 -=
s1 = {5,‘h‘,‘a‘}
s2 = set(‘hai‘) # {"h","a","i"}
s1 -= s2 # s1 = s1-s2 #只减去共有的!
print(s1) # 结果 5
知识竞赛结果 (10道题目)
zhangsan = {1,2,3,5,7,8} # 答对6道
lisi = {5,7,8,9,10} # 答对5道
求: 张三答对,李四未答对!
zhagnsan -=lisi
求: 李四答对,张高三未答对!
lisi -=zhangsan
求:都答对?
删除所有del 集合名
集合运算
和 < 判断范围!
s1 = set(‘What‘)
s2 = set(‘hat‘)
print(s1>s2) #成立!True
以上是关于python内置string模块的主要内容,如果未能解决你的问题,请参考以下文章