Python-模块
Posted JerryZao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python-模块相关的知识,希望对你有一定的参考价值。
一、模块:
Python中的模块,就是一个保存了Python代码的文件。模块能定义函数,类和变量。模块里也能包好可执行的代码。
文件名就是模块名加上后缀.py,在模块内部,模块名存储在全局变量__name__中,是一个string,可以直接在模块中通过__name__引用到模块名。
模块分为三类:
-- 自定义模块
-- 内置模块
-- 第三方模块
导入模块:
-- import:使导入者以一个整体获取一个模块
-- from:使导入者从一个模块文件中获取特定的变量名
-- reload:在不终止Python程序的情况下,提供了一个重新载入模块文件代码的方法
导入模块的方法:
1 import module # 会先把module执行一遍(如果里边有可执行程序) 2 from module.xxx.xxx import xx 3 from module.xxx.xxx import xx as rename 4 from module.xxx.xxx import * # 不推荐使用,因为里边可能有一些代码,跟执行文件里自定义的可执行代码重复,导致覆盖 5 6 7 正确的调用方式: 8 9 import cal #当前目录直接调用模块 10 11 from my_module import cal # 二层目录调用 12 13 from web1.web2.web3 import cal # 多层目录调用 14 15 from web1.web2.web3.cal import add # 只调用某个方法 16 17 18 19 注意:不支持的调用方式 (调用包就是执行包下的__init__.py文件) 20 from web1.web2 import web3 #这样是执行web3的__init__文件,唯一不支持的调用方式 21 print(web3.cal.add(2,6))
获取模块的路径:
1 import sys 2 print(sys.path) 3 4 添加路径: 5 6 import sys 7 import os 8 # project_path=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 9 # sys.path.append(project_path) 10 print(os.path.abspath(__file__)) # 是获取的文件名,路径是pycharm加上的 11 print(os.path.dirname(os.path.abspath(__file__))) # 获取文件的路径 12 print(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) #获取上一层目录
第三方模块:


1 #先安装 gcc 编译和 python 开发环境 2 yum install gcc 3 yum install python-devel 4 或 5 apt-get python-dev 6 7 #安装方式(安装成功后,模块会自动安装到 sys.path 中的某个目录中) 8 yum 9 pip 10 apt-get 11 ... 12 #进入python环境,导入模块检查是否安装成功
二、包(package)
如果不同的人编写的代码模块名相同怎么办?为了避免冲突,Python引入了按目录来组织模块的方法,称为包。

如图所示,两个cal.py冲突了,但是功能不同,所以给两个模块选择一个顶层包(不能重名),在调用就不会冲突了。
--注--:
请注意:每个包目录下来都会有一个__init__.py的文件,这个文件必须是存在的,否则,Python就不把这个目录当成普通目录,而不是一个包,__init__.py可以是空文件,也可以有python代码,__init__.py本身就是一个文件,它的模块名就是对应的包名,它一般由于做接口文件。
调用包就是执行包下的__init__.py文件
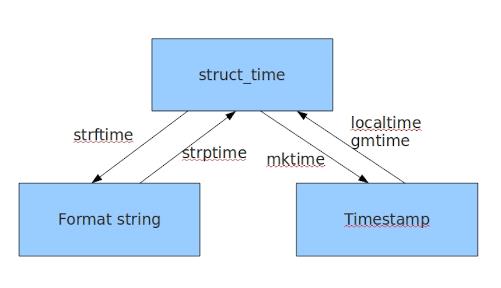
三、time模块
1 时间有三种表达方式:
2
3 时间戳: unix元年到现在------>time.time()
4 格式化的字符串:如:2016-12-12 10:10------->time.strftime(\'%Y-%m-%d\')
5 结构化时间:元组 ------>time.struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时) 即:time.localtime()
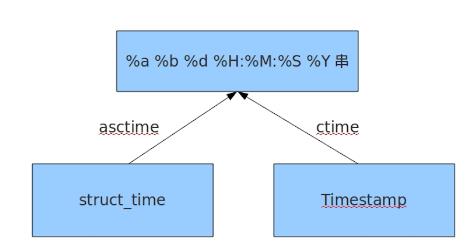
1 import time 2 3 # 1、时间戳 4 print(time.time()) 5 6 # 2、localtime() 7 print(time.localtime()) # 空参 8 ##time.struct_time(tm_year=2016, tm_mon=9, tm_mday=11, tm_hour=0, tm_min=38, tm_sec=39, tm_wday=6, tm_yday=255, tm_isdst=0) 9 10 print(time.localtime(1422222222)) # 指定时间戳 11 12 # 3、gmtime() 13 print(time.gmtime()) # gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 14 15 16 # 4、mktime() 17 print(time.mktime(time.loacltime())) #将结构化时间转换为时间戳 18 19 # 5、asctime() 20 print(time.asctime()) # 将结构化时间转变为:\'Sun Jun 20 23:21:05 1993\' 21 默认参数是time.localtime() 22 23 # 6、ctime() 24 print(timectime()) #将时间戳转化为:\'Sun Jun 20 23:21:05 1993\' 25 默认参数是time.time() 26 27 # 7、strftime() 28 print(time.strftime(format[,t])) #结构化时间转化为 字符串时间 29 默认参数time.localtime() 30 print(time.strftime(\'%Y-%m-%d %X\',time.localtime())) # 2018-03-26 19:11:36 31 32 # 8、strptime() 33 print(time.strptime())# 字符串时间转化为结构化时间 34 print(time.strptime(\'2016:12:23:17:20:20\',\'%Y:%m:%d:%X\')) # time.struct_time(tm_year=2016, tm_mon=12, tm_mday=23, tm_hour=17, tm_min=20, tm_sec=20, tm_wday=4, tm_yday=358, tm_isdst=-1) 35 36 # 9、sleep() 37 38 # 10、clock() 39 这个需要注意,在不同的系统上含义不同。 40 在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。 41 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行时间,即两次时间差
记住如下图即可:
---注---
1 import datetime 2 print(datetime.datetime.now()) 3 ##2018-03-27 17:47:07.211182
四、random模块
随机数模块:
1 import random 2 3 print(random.random()) #用于生成一个0到1的随机符点数: 0 <= n < 1.0 4 print(random.randint(1,2)) #用于生成一个指定范围内的整数 [1,2] 5 print(random.randrange(1,10)) #从指定范围内,按指定基数递增的集合中获取一个随机数 [1,10) 6 print(random.uniform(1,10)) #用于生成一个指定范围内的随机符点数 9.49909962942907
7 print(random.choice(\'nick\')) #从序列中获取一个随机元素 c 8 li = [\'nick\',\'jenny\',\'car\',] 9 random.shuffle(li) #用于将一个列表中的元素打乱 10 print(li) 11 li_new = random.sample(li,2) #从指定序列中随机获取指定长度的片断(从li中随机获取2个元素,作为一个片断返回) 12 print(li_new)
示例:验证码 查看:http://www.cnblogs.com/JerryZao/p/8659024.html
五、os模块:
os模块是与操作系统交互的一个接口
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: (\'.\') 4 os.pardir 获取当前目录的父目录字符串名:(\'..\') 5 os.makedirs(\'dirname1/dirname2\') 可生成多层递归目录 6 os.removedirs(\'dirname1\') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir(\'dirname\') 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir(\'dirname\') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.listdir(\'dirname\') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 os.remove() 删除一个文件 11 os.rename("oldname","newname") 重命名文件/目录 12 os.stat(\'path/filename\') 获取文件/目录信息 13 os.sep 输出操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/" 14 os.linesep 输出当前平台使用的行终止符,win下为"\\r\\n",Linux下为"\\n" 15 os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: 16 os.name 输出字符串指示当前使用平台。win->\'nt\'; Linux->\'posix\' 17 os.system("bash command") 运行shell命令,直接显示 18 os.environ 获取系统环境变量 19 os.path.abspath(path) 返回path规范化的绝对路径 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如何path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
ps1、os.stat()
1 stat 结构: 2 3 st_mode: inode 保护模式 4 st_ino: inode节点号。 5 st_dev: inode驻留的设备。 6 st_nlink: inode 的链接数。 7 st_uid: 所有者的用户ID。 8 st_gid: 所有者的组ID。 9 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 10 st_atime: 上次访问的时间。 11 st_mtime: 最后一次修改的时间。 12 st_ctime: 创建时间,由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
六、sys模块
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称
1 import time sys 2 3 for i in range(100): 4 sys.stdout.write("*") 5 time.sleep(1) 6 sys.stdout.flush()
七、json 和 pickle模块
用于序列化的两个模块;
json:用于字符串和Python数据类型间的进行转换
pickle:用于Python特有的类型 和P一条红的数据类型间的转换
之前学过eval内置方法,可以将字符串转换为python对象,但是局限性很大,一般eval只用于字符串表达式。
什么是序列化:
我们把对象(变量)从内存中变为可存储或可传输的过程称之为序列化。
序列化之后,就可以吧序列化后的内容写入磁盘,或者通过网络传输到别的机器上
json模块 提供了四个功能:dumps dump loads load
pickle模块也是一样的四个功能。
dump() 函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存到给定的文件中,当我们使用load()函数从文件中读取已保存的对象时,picle知道如何恢复这些对象到他们本来的格式
dumps() 函数执行和dump() 函数相同的序列化,取代接受流对象并将序列化后的数据保存到磁盘文件,这个函数简单的返回序列化的数据
loads() 函数执行和load() 函数一样的反序列化,取代接受一个流对象并去文件都序列化后的数据,它就收包含序列化后的数据的str对象,直接返回的对象
eval()方法:
1、
1 import json 2 3 dic = \'{"jakc":12}\' 4 f = open(\'c.txt\',\'w\') 5 f.write(dic)
2、
1 f = open(\'c.txt\',\'r\') 2 data = f.read() 3 print(type(data)) 4 data1 = eval(data) 5 print(data1[\'jakc\'])
json模块:
1、把字典转换成json形式的字符串写入文件中 (两种方法效果一样,只是写法不同而已)
1 #-----------方法一--------推荐使用 2 3 dic = {\'age\':12} 4 dic = json.dumps(dic) 5 print(dic) # {"age": 12} 内部都是用双引号,json格式 6 f = open(\'c.txt\',\'w\') 7 f.write(dic) 8 f.close() 9 10 #-----------方法二 11 12 dic = {\'age\':13} 13 f = open(\'d.txt\',\'w\') 14 json.dump(dic,f)
2、json反序列化
1 把文件中json类型的字符串读取出来转换成字典 2 3 #------------------方法一---推荐 4 f = open(\'d.txt\',\'r\') 5 a = json.loads(f.read()) 6 print(a) 7 print(type(a)) 8 9 #------------------方法二 10 f = open(\'c.txt\',\'r\') 11 b = json.load(f) 12 print(b) 13 print(type(b))
--注---
1 import json 2 #dct="{\'1\':111}"#json 不认单引号 3 #dct=str({"1":111})#报错,因为生成的数据还是单引号:{\'one\': 1} 4 5 dct=\'{"1":"111"}\' 6 print(json.loads(dct)) 7 8 #conclusion: 9 # 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
json的dumps,loads,dump,load功能总结:
json.dumps(x) 把python的(x)原对象转换成json字符串的对象,主要用来写入文件。
json.loads(f) 把json字符串(f)对象转换成python原对象,主要用来读取文件和json字符串
json.dump(x,f) 把python的(x)原对象,f是文件对象,写入到f文件里面,主要用来写入文件的
json.load(file) 把json字符串的文件对象,转换成python的原对象,只是读文件
pickle模块
pickle转换后的结果是bytes
1 pickle序列化: 2 3 dic = {\'name\':\'jakc\',\'age\':12} 4 j = pickle.dumps(dic) 5 f = open(\'e.txt\',\'wb\') 6 f.write(j) # 等价pickle.dump(fic,f) 7 f.close()
1 pickle反序列化: 2 3 f = open(\'e.txt\',\'rb\') 4 data = pickle.loads(f.read()) # 等价 data = pickle.load(f) 5 print(data)
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
八、shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写,key必须是字符串
# 添加键值对到文件中,会生成三个文件,并写入字典内容 import shelve f = shelve.open(r\'sssss\') # 目的:将一个字典写入文本 f={} print(f) f[\'a1\']= {\'name\':\'alex\',\'age\':12} f[\'a2\']= {\'name\':\'jakc\',\'age\':12} f[\'b1\']= {\'a\':\'aa\',\'b\':\'bb\'} f.close() ----------------------------------------------------------------------------- 会生成三个文件:sssss.dat,sssss.dir,sssss.bak,其中sssss.bak中内容如下: \'a1\', (0, 42) \'a2\', (512, 42) \'b1\', (1024, 42)
1 # 取值: 2 3 f = shelve.open(r\'sssss\') 4 print(f.get(\'a1\')[\'name\'])
九、xml模块
xml 是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但是json简单。
xml的格式如下:
1 <?xml version="1.0"?> 2 <data> #根 3 <country name="Liechtenstein"> #节点 4 <rank updated="yes">2</rank> 5 <year>2008</year> 6 <gdppc>141100</gdppc> 7 <neighbor name="Austria" direction="E"/> 8 <neighbor name="Switzerland" direction="W"/> 9 </country> 10 <country name="Singapore"> #节点 11 <rank updated="yes">5</rank> 12 <year>2011</year> 13 <gdppc>59900</gdppc> 14 <neighbor name="Malaysia" direction="N"/> 15 </country> 16 <country name="Panama"> #节点 17 <rank updated="yes">69</rank> 18 <year>2011</year> 19 <gdppc>13600</gdppc> 20 <neighbor name="Costa Rica" direction="W"/> 21 <neighbor name="Colombia" direction="E"/> 22 </country> 23 </data> 24 25 xml数据
xml在各个语言里都是支持的,在python中可以使用xml模块操作xml文件 。
1 # 基本操作1: 2 3 import xml.etree.ElementTree as ET 4 5 tree = ET.parse("test.xml") # 获取一个xml文件对象 6 root = tree.getroot() 7 print(root.tag) # 获取跟节点的标签 data 8 9 遍历xml文档 10 for i in root: 11 print(i.tag,i.attrib) # 根节点下的标签,一级属性名,属性值 12 for j in i: 13 print(j.tag,j.attrib) # 在往下一层的节点,和属性 14 15 只遍历year节点 16 for i in root.iter(\'year\'): 17 print(i.tag,i.text) 18 19 -----> 20 year 2008 21 year 2011 22 year 2011
1 # 基本操作2: 2 3 import xml.etree.ElementTree as ET 4 5 tree = ET.parse("test.xml") # 获取一个xml文件对象 6 root = tree.getroot() 7 8 # 修改 9 for i in root.iter(\'year\'): 10