python爬虫模拟登录是啥意思
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫模拟登录是啥意思相关的知识,希望对你有一定的参考价值。
参考技术A 那么你在用爬虫爬取的时候获得的页面究竟是哪个呢?肯定是第二个,不可能说你不用登录就可以访问到一个用户自己的主页信息,那么是什么让同一个URL在爬虫访问时出现不同内容的情况呢?
在第一篇中我们提到了一个概念,cookie,因为HTTP是无状态的,所以对方服务器并不知道这次请求到底来自于谁,就好像突然你收到了一封信,上面让你给他寄一些东西,但是信上却没有他的联系方式。
在HTTP中也是如此,我们普通的请求都类似于匿名信,而cookie的出现,就是让这封信上盖上了你自己的名字。
在请求时附带上你的cookie,服务器放就会知道这次请求来自于谁,然后你点击个人信息页,服务器就知道是要返回这个cookie对应的用户的信息页了。
在谷歌浏览器中,你可以在控制台Application里面找到当前网站的所有cookie键值对。一般来说用于确认你个人信息的只有一个键值对,但是你也可以把所有的都用上,并不能保证对方服务器是不是对某些键值对也进行检查了。
很多网站在你没有登录的情况下并不会给过多的数据让你看,所以你的爬虫需要进行一次模拟登录。
模拟登录需要从一个网站的登录界面开始,因为我们要在这里用爬虫发送post请求附带账号密码来登录对方网站。
python爬虫(下)--模拟登录与Captcha识别
前言
之前在 python爬虫(上)–请求——关于模拟浏览器方法,中我挖了一个坑,时隔一个多月,趁着最近有点空,我想是时候填填坑了,总结总结了,不然真的就忘了
验证码
虽然之前挖坑的那篇已经说了一些,现在还是稍微说一说.
在模拟登录中,其实让写爬虫的人疼头就是验证码,只要能破掉验证码,那么登录不是问题.
验证码(Chaptcha)内容从英文字符和数字识别,到数字加减乘除,再到汉字的出现,后面还有12306的看图识别,到现在的新型的基于人的行为的谷歌的reCaptcha,验证码也是经历了很长时间的演变。
对于很多人而言,对验证码的印象仅仅停留在网站登陆注册时候除了必要的用户名和密码以外还需要麻烦填的一个东西,而站在网站的角度,的确,验证码的应用对用户登陆没有什么作用,但是主要是防止机器人(包括爬虫)。服务器很怕大规模的请求,被百度或者谷歌这些大型搜索引擎收录当然是不错的,但是网上除了这两大搜索引擎以外还有许许多多爬虫,做的好的爬虫对服务器没有这么大的负担是极好的,关键是有很多其他的各种各样的爬虫,甚至会出现暴走的爬虫,这些爬虫都会对服务器造成很大的负担,而且并不会给网站带来受益.
不过讲真,验证码其实更重要的作用,并不是反爬虫的存在,尽管反爬虫场景中会经常见到验证码,但是Captcha应该属于人工智能范畴,是一种区别人和机器的存在,而由于这是计算机考察人类,所以有时候被称为’反向图灵测试’
对付验证码如果还是在cookie时代做用户登陆验证来说,分析验证码只要研究怎么从网页交互中找到从服务器发到终端的验证码字符串生成方式然后直接把这串字符串组合再发往服务器就可以了,没有必要对生成的验证码图片进行处理和识别,但是后面变成了Session 验证,所有的验证过程都发生在服务器,在终端只能拿到验证码图片,而没有验证码的字符串的存在,所以验证码图片的识别是避不开的坎,因为我们除非黑掉服务器,否则我们能利用的就只有验证码的图片了.
至于爬虫怎么拿到验证码图片,模拟浏览器的办法就是,selenium的截图功能,可以这么写:
browser.save_screenshot('整个页面截图.png')
element=browser.find_element_by_xpath('你的验证码的Xpath')
#location办法可能会有偏移,但是每次都会锁定了了验证码的位置,所以稍微修正一下location的定位,后面都管用
left = element.location['x']#验证码图片左上角横坐标
top = element.location['y']#验证码图片左上角纵坐标
right = left + element.size['width']#验证码图片右下角横坐标
bottom = top + element.size['height']#验证码图片右下角纵坐标
#rangle=(806,382,913,415)#手工方法有时候可以,但是有时候也会出现第一次可以,但是后面各种偏移定位不准的奇葩现象
im=Image.open('整个页面截图.png')
im_crop=im.crop((left,top,right,bottom))#这个im_crop就是从整个页面截图中再截出来的验证码的图片
怎么分析交互过程来获得此时登陆所需要的那张二维码图片,我还没有实验过,你可以试试,有点麻烦就是了,所以请容许我在这里再留个坑
既然拿到了验证码,那么接下来我要做的就是一些识别验证码的实验,友情提醒本文不涉及打码平台的操作,因为我觉得打码平台不是技术,而是商业行为,对商业我不太感冒,所以本文仅仅谈论解决问题的计算机的方法,所以想要借道打码平台来迅速花钱解决问题,请绕道谷歌/百度,或者参考“打码平台”那点事儿,我觉得写的挺全面的,挖坑的上一篇应该也提到了这篇文章
<1>英文字符+数字
先举个栗子:
对于这种我们采用的是图片预处理和OCR识别技术
预处理:因为验证码的图片经常会有噪点,干扰线(像上面这种),还有最麻烦的字符本身的扭曲/拉伸/旋转等变形和字符之间的粘连和重叠等,这里我们可以用python自家的PIL做简单的处理,如果再高级的就是OpenCV,本来有打算要不要使用OpenCV的,不过最后PIL就搞定了,没用到OpenCV.
OCR识别:可以用自己建立特征库的办法,或者是机器学习(神经网络)的办法,既然已经有现成的开源OCR工具==>TesseractOCR :D
①首先我们先做了灰度化和二值化
im_grey=im.convert('L')#灰度化
im_peak=im_grey.convert('1')#二值化灰度化以后长这样: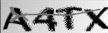
二值化以后长这样: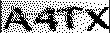
②可以看到二值化后的图片,出现和很多原图和灰度化后所看不见的离散黑点,这些黑点都可以用中值滤波器滤除,一遍的效果不好,就循环几遍就好了,而令我惊奇的是,干扰线也变成了离散的点.
那么二话不说先做它个10+次中值滤波:
from PIL import ImageFilter,ImageEnhance
im_filter=im_peak.filter(ImageFilter.MedianFilter)
for j in range(15):
im_filter=im_filter.filter(ImageFilter.MedianFilter)横向对比滤波次数效果:
1次:
=====>1次的话还是有一点在字符的周围
2次:
=====>2次的话比上一次的干净很多
3次:
=====>3次的话基本上就很干净了
….
15次:
为什么需要10+次,因为我们测试了很多情况,发现有些情况必须10+次才获得比较干净的图
不知道你们有没有发现,随着我中值滤波去掉离散的噪点,干扰线也一并去掉了,这也是我当时最惊喜的地方
③然后丢给了TesseractOCR做识别,一开始我是用Kali源里面的Tesseract直接用apt-get直接装的,不过后面会发现出现一些奇奇怪怪的问题,所以还是推荐用github里面Tesseract项目的源码安装比较好,而且源码安装后不要把源码安装包给删除了,因为源码安装目录内一般安装成功后都会生成一个卸载的脚本,万一遇到Tesseract出问题需要卸载重装的情况(尽管这种情况在源码安装的情况下发生不多,但还是有可能有发生,(我就遇到一次在用unicharset_extractor这一Tesseract训练工具之一生成.tr文件的时候,死活生成的是.txt不是.tr的文件),虽然说自己慢慢找到来删除是可以,可是这样并不干净,而且非常劳累,所以还是别在装软件上折腾太多时间,这并不是我们的关注点.
这里提一句TesseractOCR的源码安装:
TesseractOCR的github项目地址在这里,其实它的安装就是平时安装源码的那一套,不过首先你得先源码安装好Leptonica,因为Tesseract是依赖于这个库的,Leptonica的官网在这里,解压并进入Leptonica源码目录,./configure==>make==>sudo make install==>make check,就安装完毕,然后配置好环境变量[我这里以linux为例子,修改~/.bashrc或者/etc/environment,增加$PATH环境变量内容/usr/local/lib/(不然Tesseract编译的时候就找不到Leptonica了)],接下来请按照TesseractOCR官方源码安装教程安装,链接点这里,这个页面还包含Tesseract训练工具的安装,这个训练工具是为了方便我们可以用足够多的样本形成一个针对性的专用训练集(fonttype.traineddata)存在的,这个训练集是提高识别率重要的一环,安装方法也是依照刚才的官方教程就好了,顺便提一句,我墙裂推荐调整box的工具用jTessBoxEditor,图形化界面,而且启动方便简单,我现在总算是看破了,要集中注意力在你想要实现的东西上,而不要被其他事情分散注意力,尽管它们都是一些很有趣的事情
最后安装完Tesseract以后,别忘记新建一个环境变量$TESSDATA_PREFIX=/usr/local/share/tessdata/或者其他Tesseract放置语言包的地方,然后把你训练好的训练集(fonttype.traineddata)放进这个目录,其实Tesseract也有自己的已经做好的语言训练集(Language Data),你可以到这里下载全部语言的.traineddata,不过这个包不具备针对性就是了,要想识别率进一步提高,还是得对症下药,取足够多的样本然后自己弄成一个训练集
再简要说明一下我生成100.traineddata的过程:
以下的langtype,fonttype和num都可以自己指定,我的100.traineddata的100就是fonttype,num我用了0
1.首先我假设你已经有了一个合并的.tif文件和经过调整的.box文件,没有的话:
先用jTessBoxEditor将所有的你的验证码图片merge到一起成为一个tif,建议验证码图片保存的时候用tif格式,当然不用tif格式也可以,只是png和tif信息量比jpg打,毕竟jpg是有损压缩
然后生成.box文件
tesseract langtype.fonttype.exp[num].tif langtyep.fonttype.exp[num] -l eng batch.nochop makebox
接着用jTessBoxEditor打开,调整即可(你直接打开langtype.fonttype.exp[num].tif就好了,jTessBoxEditor会自己载入相应的.box文件,你就不用怀疑没有是不是自己的jTessBoxEditor出问题了,怎么找不到刚刚用命令生成的.box文件)
2.生成font_properties字符配置文件
echo fonttype 0 0 0 0 0>font_properties
p.s. 上面的"fonttype 0 0 0 0 0"对应的是"fontname italic bold fixed serif fraktur" 我的100.traineddata的100就是我的fonttype,即fontname
3.生成.tr文件
tesseract langtype.fonttype.exp[num].tif langtype.fonttype.exp[num] -l eng -psm 7 box.train
4.生成.unicharset文件
unicharset_extractor langtype.fonttype.exp[num].box
5.聚类生成shapetable文件
shapeclustering -F font_properties -U unicharset -O langtype.unicharset langtype.fonttype.exp0.tr
6.生成聚集字符特征文件(unicharset,inttemp,pffmtable)
mftraining -F font_properties -U unicharset -O langtype.unicharset langtype.fonttype.exp[num].tr
7.字符正常化特征文件normproto
cntraining langtype.fonttype.exp0.tr
8.更名(normproto,inttemp,pffmtable,unicharset,shapetable前面加上你的fonttype)
mv normproto fonttype.normproto
mv inttemp fonttype.inttemp
mv pffmtable fonttype.pffmtable
mv unicharset fonttype.unicharset
mv shapetable fonttype.shapetable
9.合并前面的训练文件,并生成.traineddata
combine_tessdata fonttype .
附上一段我的链接TesseractOCR的链接代码作为参考,github的Tesseract项目那里也有相关代码示范
[不得不说python的粘合能力,一个ctypes模块就可以调用C/C++的函数库存,这大大扩展了python解决问题的能力和效率]
#! /usr/bin/env python
#encoding:utf-8
import os
import ctypes
from ctypes import *
class TessBaseAPI(Structure):
pass
class TessResultRenderer(Structure):
pass
def Tess():
im_pre_path='./picCache/captcha.tif'
#载入tesseract函数库,windows和linux不一样,请注意!!
libname='/usr/local/lib/libtesseract.so.3.0.4'
tesseract = ctypes.cdll.LoadLibrary(libname)
print libname,'载入成功'
#配置
tesseract.TessVersion.restype=ctypes.c_char_p
tesseract.TessBaseAPICreate.restype=POINTER(TessBaseAPI)
tesseract.TessBaseAPIInit3.argtypes=[POINTER(TessBaseAPI), c_char_p, c_char_p]
tesseract.TessBaseAPIInit3.restype=c_bool
tesseract.TessBaseAPIProcessPages.argtypes=[POINTER(TessBaseAPI), c_char_p, c_char_p, c_int, POINTER(TessResultRenderer)]
tesseract.TessBaseAPIProcessPages.restype=c_bool
tesseract.TessBaseAPIGetUTF8Text.argtypes=[POINTER(TessBaseAPI)]
tesseract.TessBaseAPIGetUTF8Text.restype=c_char_p
#创建一个Handler--api
api=tesseract.TessBaseAPICreate()
TESSDATA_PREFIX=os.environ.get("TESSDATA_PREFIX")
lang='100'#这是我们训练出来的100.traineddata
#初始化
rc = tesseract.TessBaseAPIInit3(api,TESSDATA_PREFIX,lang)
if (rc):
tesseract.TessBaseAPIDelete(api)
print("Could not initialize tesseract.\\n")
exit(3)
success=tesseract.TessBaseAPIProcessPages(api,im_pre_path,None,0,None)
if success:
text=tesseract.TessBaseAPIGetUTF8Text(api)
text=text.decode("utf-8").strip()
if text=='':
return '读取失败'
return text结果识别并不是特别理想,用100张验证码样本(已经经过灰度二值和中值滤波15次)得出的100.traineddata,只有25%左右的识别率,而且更坏的是,我们以为的会随着增加到200张,甚至300张,识别率应该有所上升,可是识别率不升反降,甚至最后400张的时候比原生的eng.traineddata还不如,这时候我瞬间被泼了盆冷水,我以为只要增加样本就可以不断提高识别率,可是现在看来问题并不是出在验证码样本的数量不够上,而且光是通过数量增大来获得验证码的识别率升高也不是一个好办法,只是通过机械劳作达到的效果的方法都是烂方法,然后我陷入僵局.
④引入改进型滴水算法解决字符粘连问题
一番谷歌后,经过我对比多篇文章,都在说字符粘连的切割是解决图片字符识别的关键,我发现我所要识别的验证码也存在着字符粘连问题,尽管Tesseract自己会粗略分割,可是会不会提前做好分割会有更高的识别率呢?我也不清楚,但是实验会告诉我们一切.
我们采取的是这篇论文[1]的办法——改进型滴水算法,算法详细思路以及优点在论文里面已经讲了,大概来讲主要依赖三种算法:一种是CFS算法,一种是竖直投影统计算法,还有一种是经典滴水算法
运用CFS算法和垂直投影统计算法得出最佳的滴水算法起点,然后再用经典滴水算法的方式来切割.
===>CFS算法:全称是Color Filling Segmentation,为什么叫这个名字可以参考论文[2],论文中的思路只是讲了个大概,经过具体编程实现后,我才发现论文中缺省了很多细节,现在按照编程的思路再细节一点讲:其实就是从图片的第一个像素扫描,然后找到第一个黑色像素点,接着以这个黑色像素点为中心,把当前当作中心的黑点坐标放进已经遍历的集合visited并把它的横纵坐标分别保存到xaixs和yaxis中,再检测中心黑点的四领域像素,如果发现有黑点,就把黑点坐标加入队列q,下一次就以新发现的黑点为中心再检测四领域的黑点,如此重复,直到周围没有检测到还未遍历过的黑点,然后在所有保存的xaxis和yaxis中找出该区块横纵坐标最大和最小值,换句话说,通过CFS算法我们就可以知道图中有多少个区块(区块指的是连通的区域),以及分别的起止横纵坐标是多少.
然后我用python代码实现的时候,发现CFS算法和FloodFill算法有很多相似之处,所以我直接拿到FloodFill算法的python实现改了一下,做了如下示例:
参考代码:
#! /usr/bin/env python
# encoding:utf-8
import Queue
#用队列和集合记录遍历过的像素坐标代替单纯递归以解决cfs访问过深问题
def cfs(im,x_fd,y_fd):
xaxis=[]
yaxis=[]
pix=im.load()
visited =set()
q=Queue.Queue()
q.put((x_fd, y_fd))
visited.add((x_fd, y_fd))
offsets=[(1, 0), (0, 1), (-1, 0), (0, -1)]#四邻域
while not q.empty():
x,y=q.get()
for xoffset,yoffset in offsets:
x_neighbor,y_neighbor=x+xoffset,y+yoffset
if (x_neighbor,y_neighbor) in (visited):
continue # 已经访问过了
visited.add((x_neighbor, y_neighbor))
try:
if pix[x_neighbor, y_neighbor]==0:
xaxis.append(x_neighbor)
yaxis.append(y_neighbor)
q.put((x_neighbor,y_neighbor))
except IndexError:
pass
xmax=max(xaxis)
xmin=min(xaxis)
#ymin,ymax=sort(yaxis)
return xmax,xmin
#搜索区块起点
def detectFgPix(im,xmax):
l,s,r,x=im.getbbox()
pix=im.load()
for x_fd in range(xmax+1,r):
for y_fd in range(x):
if pix[x_fd,y_fd]==0:
return x_fd,y_fd
def CFS(im):
zoneL=[]#各区块长度L列表
zoneBE=[]#各区块的[起始,终点]列表
zoneBegins=[]#各区块起点列表
xmax=0#上一区块结束黑点横坐标,这里是初始化
for i in range(5):
try:
x_fd,y_fd=detectFgPix(im,xmax)
xmax,xmin=cfs(im,x_fd,y_fd)
L=xmax-xmin
zoneL.append(L)
zoneBE.append([xmin,xmax])
zoneBegins.append(xmin)
except TypeError:
return zoneL,zoneBE,zoneBegins
return zoneL,zoneBE,zoneBegins
#========>CFS ABOVE
===>垂直投影统计
所谓垂直投影统计就是通过得出图片的垂直投影直方图,然后获得拥有相对较少黑色像素的横坐标作为切割点,因为往往这些拥有相对较少的黑色像素的横坐标就是字符粘连的位置,你可以稍微想象一下~但是原始的垂直垂直投影统计最后是直接从得出的横坐标垂直切割,所以对字符外形伤害很大,所以这里运用的垂直投影统计并没有包含切割,只是得出前面的垂直投影统计直方图
参考代码:
#求出图片的垂直投影直方图
def VerticalProjection(im):
VerticalProjection={}
l,s,r,x=im.getbbox()
pix=im.load()
for x_ in range(r):
black=0
for y_ in range(x):
if pix[x_,y_]==0:
black+=1
item=str(x_)
VerticalProjection[item]=black
return VerticalProjection
#========>VERTICALPROJECTION ABOVE
上面CFS和垂直投影统计,我们已经拿到了各个区块的长度列表zoneL,区块的起止点列表zoneBE,区块的起点列表zoneBegins,还有图片的垂直投影直方图的一个字典VerticalProjection,但是光是这样还是没有得到最佳的滴水算法起始落水点,别着急,还要结合上面这些东西,推演出一些更重要的东西
===>结合CFS和垂直投影统计所得进行进一步推演
※推演一:利用zoneL和zoneBegins还有基于人工统计值的最大/最小/平均字符长度Dmax/Dmin/Dmean得出切割线列表zonexCutLines
从zoneL取出图片内各个连通区块长度L,用来判断是否需要分割(如果判断到如果区块内只有一个字符就不需要分割),对需要分割的区块,在zoneBegins中拿出各个该区块起始点横坐标,然后加上(num-1)*Dmean就能得到切割线横坐标。其中,num表示该区块内连通字符数量,num-1表示需要得出的切割线数量。
E.g.假设我的区块内有num=2个字符,就必须切num-1=1刀,那么这一刀的横坐标就应该是区块起始点横坐标加上(num-1)*Dmean,那么如果我的区块起始点横坐标是10,统计出来的平均字符长度Dmean=31,那么切割线坐标就是,10+(2-1)*31=41
P.s.之所以说Dmax/Dmin/Dmean是基于人工统计的,是因为这个字符长度,特别是平均字符长度,需要人工去统计足够多数量的验证码,得出字符的最大长度/最小长度/平均长度(也可以说是一般长度),[Dmean的值在防止欠分割/过分割以提高识别率方面至关重要,所以请用尽量多的验证码图片统计平均字符长度Dmean],这里我们取了50张验证码图片做统计.
参考代码:
def zonexCutLines(zoneL,zoneBegins):
Dmax= #最大字符长度,人工统计后填入
Dmin= #最小字符长度,人工统计后填入
Dmean= #平均字符长度,人工统计后填入
zonexCutLines=[]
for i in range(len(zoneL)):
xCutLines=[]
if zoneL[i]>Dmax:
num=round(float(zoneL[i])/float(Dmean))
num_int=int(num)
if num_int==1:
continue
for j in range(num_int-1):
xCutLine=zoneBegins[i]+Dmean*(j+1)
xCutLines.append(xCutLine)
zonexCutLines.append(xCutLines)
else:
continue
return zonexCutLines※推演二:根据起止点列表zoneBE来在VerticalProjection字典中取出与需要切割的区块对应的垂直投影直方图部分,并按黑色像素数量从小到大进行重排,最后append进列表yVectors_sorted
参考代码:
def yVectors_sorted(zoneBE,VerticalProjection):
yVectors_dict={}
yVectors_sorted=[]
for zoneBegin,zoneEnd in zoneBE:
L=zoneEnd-zoneBegin
Dmean= #基于人工统计的平均字符长度值
num=round(float(L)/float(Dmean))#区块长度L除以平均字符长度Dmean四舍五入可得本区块字符数量
num_int=int(num)
if num_int>1:#当本区块字符数量>1时候,可以认为出现字符粘连,是需要切割的区块
for i in range(zoneBegin,zoneEnd+1):
i=str(i)
yVectors_dict[i]=VerticalProjection[i]#扣取需要切割的区块对应的垂直投影直方图的部分
#对扣取部分进行重排并放入yVectors_sorted列表中
yVectors_sorted.append(sorted(yVectors_dict.iteritems(),key=lambda d:d[1],reverse=False))
return yVectors_sorted※推演三:由zoneL,zonexCutLines,yVectors_sorted确定最佳的滴水算法起始点列表drops,主要思想是:由zonexCutLines中取出本区块所要的切割线的横坐标,和对应在yVectors_sorted取出的本区块的重排垂直投影直方图的横坐标做对比,从直方图最左比到最右,若发现和切割线横坐标之间的距离在4以内,我们就可以认为在切割线附近找到了字符粘连处的相对薄弱点,该点即算作一个滴水算法起始点,并放进列表drops中.最后drops列表中的滴水起始点数目应该和所有区块切割线总数目一致
参考代码:
def get_dropsPoints(zoneL,zonexCutLines,yVectors_sorted):
Dmax=
Dmean=
drops=[]
# yVectors_sorted__=[]
# xCutLines=[]
h=-1
for j in range(len(zoneL)):
yVectors_sorted_=[]
if zoneL[j]>Dmax:
num=round(float(zoneL[j])/float(Dmean))
num_int=int(num)
#容错处理
if num_int==1:
continue
h+=1
yVectors_sorted__=yVectors_sorted[h]
xCutLines=zonexCutLines[h]
#分离
yVectors_sorted_x=[]
yVectors_sorted_vector=[]
for x,vector in yVectors_sorted__:
yVectors_sorted_x.append(x)
yVectors_sorted_vector.append(vector)
for i in range(num_int-1):
for x in yVectors_sorted_x:
x_int=int(x)
#d表示由Dmean得出的切割线和垂直投影距离的最小点之间的距离
d=abs(xCutLines[i]-x_int)
#d和Dmean一样也需要人工设置
if d<4:
drops.append(x_int)#x是str格式的
break
else:
#print '本区块只有一个字符'
continue
return drops
好了,既然我们通过了推演,最终得到了包含了需要滴水切割的起始点横坐标列表drops,那么我们接下来就是要去运用经典的滴水算法完成验证码粘连字符的切割
===>经典滴水算法
经典滴水算法可以描述为:
1.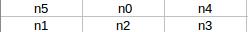 如左图,n0为当前水滴位置;
如左图,n0为当前水滴位置;
2.当n1-n5全为黑或者全为白,权重为4,那么当前位置从n0挪到n2;
3.若非2中情况,则要根据权重Wi来判断n0=>?(这里的五种情况,论文[1]中将会有更为详细的说明)
4.当n0到达图片底部,则刚才它走过的路径就是滴水切割路径
5.值得注意的是,实际中会出现水平移动距离太远导致过分割的情况,所以要水平方向上给水滴的移动距离加上一个约束,以避免过分割的现象
def get_Wi(im,Xi,Yi):
pix=im.load()
#statement
n1=pix[Xi-1,Yi+1]
n2=pix[Xi,Yi+1]
n3=pix[Xi+1,Yi+1]
n4=pix[Xi+1,Yi]
n5=pix[Xi-1,Yi]
if n1==255:
n1=1
if n2==255:
n2=1
if n3==255:
n3=1
if n4==255:
n4=1
if n5==255:
n5=1
S=5*n1+4*n2+3*n3+2*n4+n5
if S==0 or S==15:
Wi=4
else:
Wi=max(5*n1,4*n2,3*n3,2*n4,n5)
return Wi
def situations(Xi,Yi,Wi):
switcher={
1: lambda:(Xi-1,Yi),
2: lambda:(Xi+1,Yi),
3: lambda:(Xi+1,Yi+1),
4: lambda:(Xi,Yi+1),
5: lambda:(Xi-1,Yi+1),
}
func=switcher.get(Wi,lambda:switcher[4]())
return func()
#改进型就是在drops滴水起点的获取方式和经典不一样
def dropPath(im,drops):
l,s,r,x=im.getbbox()
path=[]
zonePath=[]
for drop in drops:
Xi=drop
Yi=0
limit_left=drop-4#左约束
limit_right=drop+4#右约束
while Yi!=x-1:
Wi=get_Wi(im,Xi,Yi)
Xi,Yi=situations(Xi,Yi,Wi)
if Xi==limit_left or Xi==limit_right:
Xi,Yi=path[-1]#若触碰到约束边界,就回退到上一次的坐标
if Yi>2:
#如果遇到当前水滴位置坐标和上或者上上次的坐标一样,则设置为权重4,即垂直向下从n0挪动到n2的位置
if path[-2]==(Xi,Yi) or path[-1]==(Xi,Yi):
Xi,Yi=situations(Xi,Yi,4)
path.append((Xi,Yi))
zonePath.append(path)
return zonePath
#主函数
def DropCUT(im):
pix=im.load()
drops=Drops(im)
zonePath=dropPath(im,drops)
for path in zonePath:
for x,y in path:
pix[x,y]=255#令滴水路径上的所有坐标都染上白色
return im#17.1.1更新:感谢评论区baidu_37218175的提醒,我发现我给少了个Drops函数(在上面主函数DropCUT里面的那个Drops(im))
#其实Drops(im)作用很简单,就是把前面的求出水滴起始落点坐标的所有步骤全部串起来
def Drops(im):
#PartONE
zoneL,zoneBE,zoneBegins=CFS(im)
#PartTWO
zonexCutLines_=zonexCutLines(zoneL,zoneBegins)
#PartThree
yVectors_sorted_=yVectors_sorted(zoneBE,VerticalProjection(im))
#PartFOUR
drops=get_dropsPoints(zoneL,zonexCutLines_,yVectors_sorted_)
#print '最佳滴水点横坐标分别为为====>',drops
return drops===>改进型滴水算法切割测试
来看看效果:

[左边是改进型滴水算法切割前,右边是改进型滴水算法切割后]
自此,图片分割完毕,再用100张这种改进型滴水算法分割形成的图片做成训练集100.traineddata,经过测试,我想说,72%几率在3次内登录成功,其中66%情况是1次就成功了,总体成功率在50%左右,而失败我分析了下,主要是因为遇到远远超过/短于你所统计的Dmean字符长度的字符,我们遇到的就是GMNQW过长和ELJ过短,还有H容易中间切一刀,Tesseract就把他识别为F了。所以为什么前面说的Dmean的统计值是至关重要的
过分割的情况: 因为同时遇到NQ,所以你可以看下方识别成什么样了….
因为同时遇到NQ,所以你可以看下方识别成什么样了….
从上面的情况看,前期做了个粘连字符切割,识别率小幅上升,从测试中看,至少不会出现之前识别得乱七八糟的情况,但是局限性正如论文[1]里面最后说的,对于字符长度差别太大的情况以及字符扭曲和倾斜的情况,分割精确度会收到消极影响,容易造成字符的损伤.
接下来的话,如果想要进一步提高准确率,可以尝试用腐蚀膨胀算法提取字符骨架,或许能减轻字符长度区别问题
10.19更新:总感觉上面自己写的代码重重复复地用列表组装,然后在第二个函数内用for来解开这层用来组装的列表,显得非常复杂,一点都不优雅简洁,而且这个最外层的列表貌似除了用来组装以外没有其他功能,可以说用列表包装再在另外一个函数内解开的这步我认为是错误的,但是我现在没有精力改进了…..所以建议各位觉得有更加优雅的办法的话,请在下面评论~
12.12更新:后面继续实验性加入了腐蚀膨胀算法(在滴水切割后),发现效果并不好,应该说并没有什么卵用,后面换成了PIL中的maxfilter和minfilter组合(先感谢林少川的方法和工作),达到一种类似与腐蚀的效果,让字符更加纤细,然后出乎我们意料的是识别率有20%左右的上升(50%==>70%),这一定程度符合我们预期的效果,然后最后推荐一个关于python图形处理的博客~双12快乐 :-)
<2>其他验证码识别
待更新
免责声明
技术分享用,勿用于商业用途
参考文献:
[1]LI Xingguo, GAO Wei. Segmentation method for merged characters in CAPTCHA based on drop fall algorithm.
Computer Engineering and Applications, 2014, 50 (1): 163-166.
[2]Yan J, El Ahmad A S.A low-cost attack on a Microsoft CAPTCHA[C]//Proceedings of the 15th ACM Conference on Computer and Communications Security, 2008: 543-554.
以上是关于python爬虫模拟登录是啥意思的主要内容,如果未能解决你的问题,请参考以下文章