python多线程下载文件
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python多线程下载文件相关的知识,希望对你有一定的参考价值。
看到一篇多线程下载的文章,这里把自己的理解写一篇多线程下载的文章。
我们访问http://192.168.10.7/a.jpg时是get请求,response的head包含Content-Length: 37694
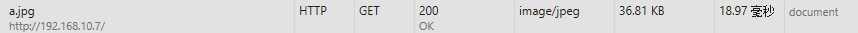
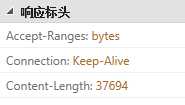
这个就是a.jpg文件的大小
抓包的话,server端是发送多个数据包(PDU)和一个文件信息,然后拼装成了a.jpg图片:
 ,部分截图。
,部分截图。
如果我用requests.head("http://192.168.10.7/a.jpg")时,server端只返回文件信息,而不会发送文件数据。
response = requests.head(self.url) print(response.headers) # {‘Keep-Alive‘: ‘timeout=5, max=100‘, ‘Accept-Ranges‘: ‘bytes‘, ‘Date‘: ‘Sat, 18 Feb 2017 02:56:08 GMT‘, ‘ETag‘: ‘"933e-548c4b0beff53"‘, ‘Content-Type‘: ‘image/jpeg‘, ‘Content-Length‘: ‘37694‘, ‘Last-Modified‘: ‘S at, 18 Feb 2017 02:21:39 GMT‘, ‘Connection‘: ‘Keep-Alive‘, ‘Server‘: ‘Apache/2.4.18 (Ubuntu)‘}
文件a.jpg大小是37964字节
保存a.jpg文件后查看文件大小也是
好了,我们知道文件大小了的话,那如何多线程下载了?
假如我们用3个线程去下载a.jpg,那么我们会用线程1去下载1260x10=12600字节,线程2下载12601-25200字节,以此类推,还不够就用线程1再去下载。
但是get请求不是会直接下载a.jpg文件了?怎么只获取一部分文件的数据了?
我们可以在get请求的head部分加入“Range: bytes=0-12599”, 先测试下
# res.text 是将get获取的byte类型数据自动编码,是str类型, res.content是原始的byte类型数据
# 所以下面是直接write(res.content)
headers = {"Range":"bytes=0-12599"}
res = requests.get(self.url,headers=headers)
# res.text 是将get获取的byte类型数据自动编码,是str类型, res.content是原始的byte类型数据
# 所以下面是直接write(res.content)
with open(self.filename,‘wb‘) as f:
f.write(res.content)
然后可以看到下载获取的一部分图片:

我们再获取下一部分数据,
headers = {"Range":"bytes=12600-25199"}
res = requests.get(self.url,headers=headers)
# res.text 是将get获取的byte类型数据自动编码,是str类型, res.content是原始的byte类型数据
# 所以下面是直接write(res.content)
with open(self.filename,‘ab+‘) as f:
print(f.tell())
f.write(res.content)
可以看到文件:

我们知道:
r或rt 默认模式,文本模式读 rb 二进制文件 w或wt 文本模式写,打开前文件存储被清空 wb 二进制写,文件存储同样被清空 a 追加模式,只能写在文件末尾 a+ 可读写模式,写只能写在文件末尾 w+ 可读写,与a+的区别是要清空文件内容 r+ 可读写,与a+的区别是可以写到文件任何位置
如果是多线程的而下载的话,我们用open(‘file‘,‘rb+‘),我先用这种模式继续上面下载文件,上面下载到了25199字节,
那这次我从26000开始下载,f.seek(26000)后开始保存下载的文件,看文件是否能保存,看到的文件是否会中间出现空白:
headers = {"Range":"bytes=26000-37694"}
res = requests.get(self.url,headers=headers)
# res.text 是将get获取的byte类型数据自动编码,是str类型, res.content是原始的byte类型数据
# 所以下面是直接write(res.content)
with open(self.filename,‘rb+‘) as f:
f.seek(26000)
f.write(res.content)
下载后的文件:

这个,可能图片显示可能跟我们想象的不一样,但是rb+肯定是可以从任意位置读写的。
还介绍一个知识点,可能在自己测试的时候用的到,就是:
f.truncate(n): 从文件的首行首字符开始截断,截断文件为n个字符;无n表示从当前位置起截断;截断之后n后面的所有字符被删除。
好了,现在我们开始使用多线程下载文件:
设计思路是:
1、每个线程下载一部分数据
2、每个线程用rb+模式打开文件
3、每个线程下载数据后,用f.seek()到相应的位置,然后再写数据。
直接f=open(),再多线程f.write()时会出现文件写错误。
我们可以用os.dup()复制文件符合os.fsopen(fd,mode,buffer)来打开处理文件。
os.dup()和os.fdopen()的好处个人理解是os.dup()复制文件句柄,os.fdopen()先写缓存,具体官方文档还有待查证。
代码:
版本 python3,
pip install requests
下面代码可以拿来直接跑
#! -coding:utf8 -*- import threading,sys import requests import time import os class MulThreadDownload(threading.Thread): def __init__(self,url,startpos,endpos,f): super(MulThreadDownload,self).__init__() self.url = url self.startpos = startpos self.endpos = endpos self.fd = f def download(self): print("start thread:%s at %s" % (self.getName(), time.time())) headers = {"Range":"bytes=%s-%s"%(self.startpos,self.endpos)} res = requests.get(self.url,headers=headers) # res.text 是将get获取的byte类型数据自动编码,是str类型, res.content是原始的byte类型数据 # 所以下面是直接write(res.content) self.fd.seek(self.startpos) self.fd.write(res.content) print("stop thread:%s at %s" % (self.getName(), time.time())) # f.close() def run(self): self.download() if __name__ == "__main__": url = sys.argv[1] #获取文件的大小和文件名 filename = url.split(‘/‘)[-1] filesize = int(requests.head(url).headers[‘Content-Length‘]) print("%s filesize:%s"%(filename,filesize)) #线程数 threadnum = 3 #信号量,同时只允许3个线程运行 threading.BoundedSemaphore(threadnum) # 默认3线程现在,也可以通过传参的方式设置线程数 step = filesize // threadnum mtd_list = [] start = 0 end = -1 # 请空并生成文件 tempf = open(filename,‘w‘) tempf.close() # rb+ ,二进制打开,可任意位置读写 with open(filename,‘rb+‘) as f: fileno = f.fileno() # 如果文件大小为11字节,那就是获取文件0-10的位置的数据。如果end = 10,说明数据已经获取完了。 while end < filesize -1: start = end +1 end = start + step -1 if end > filesize: end = filesize # print("start:%s, end:%s"%(start,end)) # 复制文件句柄 dup = os.dup(fileno) # print(dup) # 打开文件 fd = os.fdopen(dup,‘rb+‘,-1) # print(fd) t = MulThreadDownload(url,start,end,fd) t.start() mtd_list.append(t) for i in mtd_list: i.join()
执行结果:
python multiprocess_download.py http://192.168.10.7/of.tar.gz of.tar.gz filesize:36578022 start thread:Thread-1 at 1487405833.7353075 start thread:Thread-2 at 1487405833.736311 start thread:Thread-3 at 1487405833.7378094 stop thread:Thread-1 at 1487405836.9561603 stop thread:Thread-3 at 1487405837.0016065 stop thread:Thread-2 at 1487405837.0116146
多次测试,下载后的文件都可以正常打开。
如果有多个站点有of.tar.gz文件,那更可以体现多线程下载的体验。
根据上面的理论,我们应该可以做一个类似p2p的下载,比如10台机器,每台启动一个agent,每个agent给server上报自己目录下的文件信息,当有一个agent有下载文件时,会去server查询哪些agent有这个文件,然后计算去哪些agent下载哪段数据。
以上是关于python多线程下载文件的主要内容,如果未能解决你的问题,请参考以下文章
使用 python yfinance 多线程下载雅虎股票历史