怎么在SPSS中做kaplan-meier生存分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么在SPSS中做kaplan-meier生存分析相关的知识,希望对你有一定的参考价值。
参考技术A K-M曲线变量time:生存时间;group:1=治疗组,0=对照组;status:1=出现结局,0=失访或实验结束时仍存活
1将time拉入时间对话框
2将status拉入状态对话框,点击状态框下方的“定义事件”按钮:填入代表事件发生的“1”
3将group拉入因子对话框
4点击“选项”按钮,进行设置,选择生存图
5点击“比较因子”按钮,进行设置设置如下:勾选对数秩
6回到主对话框,点击“确定”输出结果。
统计专业研究生工作室为您服务,需要专业数据分析可以找我本回答被提问者采纳
R语言 | 生存分析及R包survival的Kaplan-Meier

生存分析方法有很多种,大致分为三类:
(1)参数法:根据已知的生存时间分布模型,估计模型参数,最后以分布模型计算生存率;
(2)非参数法:无需生存时间分布,根据样本统计量来估计生存率,如Kaplan-Meier分析(乘积极限法);
(3)半参数法:无需生存时间分布,通过模型评估影响生存率的因素,如Cox回归模型。
本篇首先简介其中的Kaplan-Meier,并展示其在R语言中的执行过程。
Kaplan-Meier生存分析简介
首先对Kaplan-Meier分析方法作个简介。
Kaplan-Meier曲线
首先来看某篇文献中的部分内容,这是在肿瘤疾病等的相关研究中经常可以看到有关患者预后的生存分析,分析某基因的高/低表达、基因是否发生突变等与患者生存时间的关系,评估这些基因功能的失调、缺失等对患者生存时间的贡献,帮助确定关键的预后因素。
曲线图中,每张图中均展示了两组患者,这些患者按WNK2基因是否存在变异(WT为野生型,MT为突变,loss表示由CNV导致的基因座或拷贝数缺失)、WNK2基因的表达水平(high为高表达,low为低表达)等分为两组。通过比较我们可以看到WNK2基因存在变异或低表达的患者的生存时间更短,体现在上方累积的去世患者比例曲线增长更快,下方的仍在世患者比例曲线剧烈下降,代表着WNK2正常功能缺失后带来高风险,暗示其可能是潜在的癌症治疗靶基因。
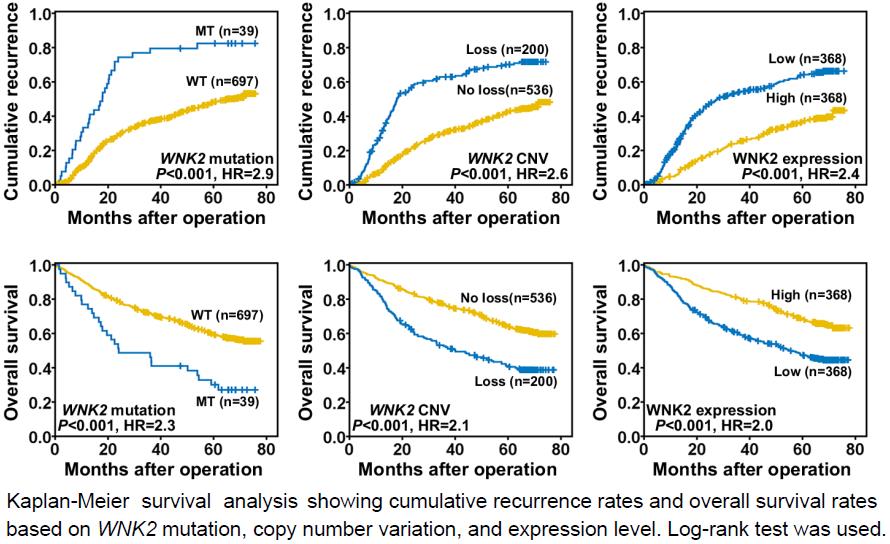
(Zhou et al, 2019)
Kaplan-Meier的应用
Kaplan-Meier是一种非参数的单变量分析方法,根据生存时间分布,估计生存率以及中位生存时间,以生存曲线方式展示,从而分析生存特征。Kaplan Meier估计量的图表是一系列递减的水平步长,在样本量足够大的情况下,该步长接近该种群的真实生存函数(如上图文献示例所示)。
在医学研究中,Kaplan-Meier分析是用于描述治疗后一定时间内存活患者比例的最佳(也是最简约)方法之一。Kaplan-Meier分析可以在各种情况下创建生存曲线,包括计算某一时间点上事件发生的概率,并将这些连续概率乘以任何之前计算的概率,获得最终估计值,这可以计算出两组受试者的存活率以及他们的统计差异(Goel et al, 2010)。
当然,Kaplan-Meier并非总与“死亡”或“结束”等时间挂钩,其它例如失业后人们仍然失业多久,接受生育治疗的夫妇怀孕需要多长时间,机器零件的故障时间,等等条件均可适用。
关于生存分析中的复杂因素
在生存分析中,如果每个观测对象都被追踪了相同的时间直到他们功能终止(如生命体死亡,非生命体损坏等),那么计算生存时间就很容易,只要找出在任何时间点尚存的对象所占的比例即可。但是在现实世界中,复杂的因素常常使这项任务无法实现,例如在以下因素的临床试验中,计算生存时间可能会变得复杂:
(1)因故意或由于与研究人员失去联系而退出研究的患者;
(2)研究结束时尚存活,但预计将在未来不久后去世的患者;
(3)参加研究的患者比其他患者晚,等等。
尽管存在与受试者或情况相关的困难,但由于Kaplan-Meier无需考虑生存时间分布,根据样本统计量来估计生存率,因此仍然具有较高功效,并且Kaplan-Meier是计算生存时间的最简约方法之一,获得广泛应用。
R包survival的Kaplan-Meier分析
对于Kaplan-Meier分析,survival包可能是在文献中见到最多的R包了,本篇就以survival包的Kaplan-Meier分析方法为例展示。
示例数据
survival包的内置数据集lung,为NCCTG(North Central Cancer Treatment Group)的肺癌患者临床资料数据。
library(survival)
#示例数据,详情 ?lung
data(lung)
head(lung)
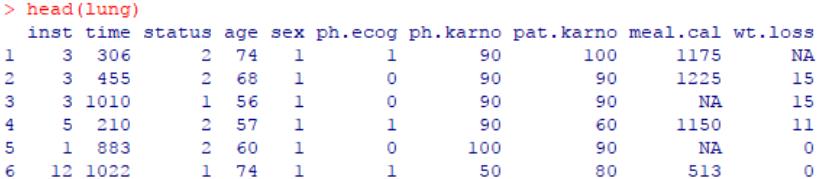
该数据集中记录了228例晚期肺癌患者的生存时间(time,单位为天)、生存状态(status,1为在世,2为去世)以及其它状态特征,例如年龄(age)、性别(sex,1为男性,2为女性)等,详情?lung查看帮助文档中的简介即可。
本示例期望通过Kaplan-Meier分析,比较男性与女性肺癌患者的生存率是否具有显著不同。
Kaplan-Meier分析和Log-rank test
加载survival包,指定指定数据集中的生存时间(time)、患者生存状态(status)以及分组(sex,性别)等执行Kaplan-Meier分析。
#Kaplan-Meier 分析,详情 ?survfit
KM <- survfit(Surv(time, status) ~ sex, data = lung, type = 'kaplan-meier', conf.type = 'log')
KM
summary(KM)
#结果提取,例如重要的统计值
summary(KM)$table
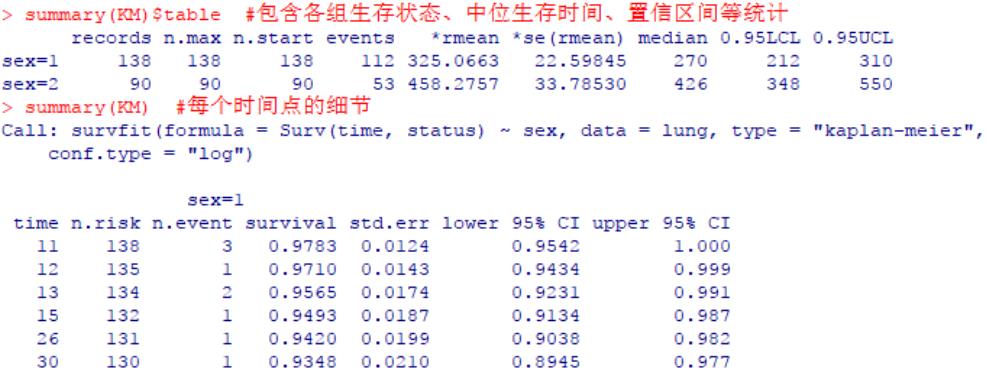
结果中,将计算给定各组中的个体数量、中位生存时间(median survival time)、95%置信区间等。通常,中位生存时间越长代表着预后较好。
通过对数秩检验(Log-rank test)比较组间生存曲线,可以获得组间生存率的差异p值。Log-rank test是非参数检验,近似于卡方检验,零假设是组间没有差异。
#对数秩检验,详情 ?survdiff
survdiff(Surv(time, status) ~ sex, data = lung)
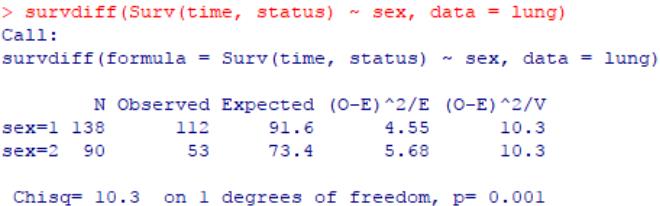
显示p=0.001,组间差异非常显著,也就是两组患者之间的生存率具有显著差异。
再通过比较上述获得的中位生存时间(2>1,即女性>男性),有理由认为男性肺癌患者比女性肺癌患者具有更差的预后,猜测原因可能与男性更多存在吸烟史有关(数据集中没体现)。
接下来绘制生存曲线观测
#绘制生存曲线,反映了尚在世的患者数量比例和时间的关系
plot(KM, main = 'Kaplan-Meier ', xlab = 'Time (days)', ylab = 'Overall survival',
lwd = 2, col = c('blue', 'red'))
legend(x = 'topright', col = c('blue', 'red'), lwd = 2, legend = c('1: male', '2: female'))
#绘制累积风险曲线,反映了疾病风险和时间的关系,与累积的去世患者数量有关
plot(KM, main = 'Cumulative hazard', xlab = 'Time (days)', ylab = 'Cumulative hazard',
lwd = 2, col = c('blue', 'red'), fun = 'cumhaz')
legend(x = 'topright', col = c('blue', 'red'), lwd = 2, legend = c('1: male', '2: female'))
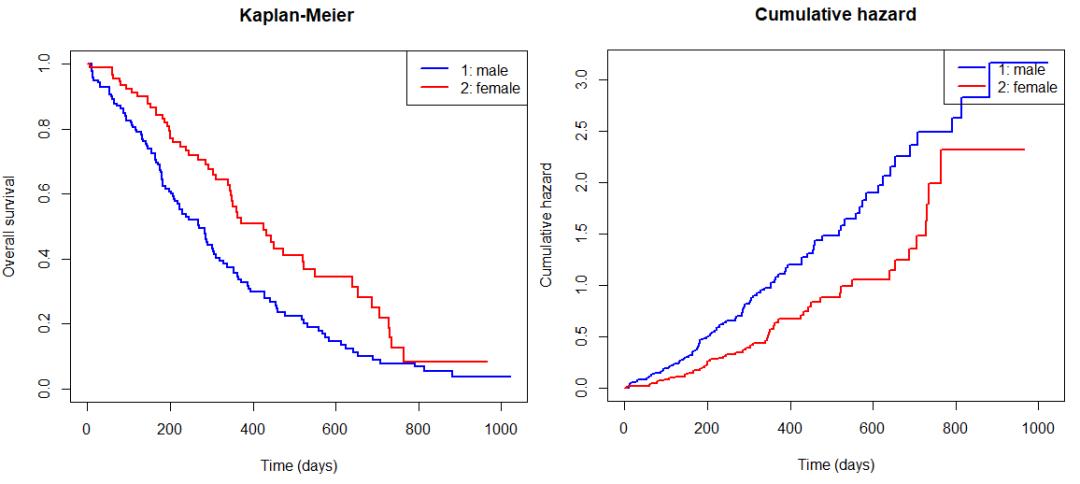
通过生存曲线或累积风险曲线可以直观看出,相比之下男性肺癌患者比女性肺癌患者具有更低的生存率。
* survminer包的可视化方法
此外,survminer包提供了对survival包的Kaplan-Meier分析结果的更好的可视化方案,并可将更多的统计结果包含其中(如显示p值,95%置信区间,以及分位数时间段的生存患者数量等)。
library(survminer)
#生存曲线,详情 ?ggsurvplot
ggsurvplot(KM, conf.int = TRUE, palette = c('blue', 'red'), risk.table = TRUE, pval = TRUE)
#累积风险曲线
ggsurvplot(KM, conf.int = TRUE, palette = c('blue', 'red'), fun = 'cumhaz')
再次可以看出,男性肺癌患者(sex=1)比女性肺癌患者(sex=2)具有显著更差的生存率(p=0.001)。
参考资料
以上是关于怎么在SPSS中做kaplan-meier生存分析的主要内容,如果未能解决你的问题,请参考以下文章