python序列化与反序列化(json与pickle)
Posted NIUSHA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python序列化与反序列化(json与pickle)相关的知识,希望对你有一定的参考价值。
在python中,序列化可以理解为将python中对象的编码格式转换为json(pickle)格式的字符串,而反序列化可以 理解为将json(pickle)格式的字符串转换为python中对象的编码格式
举一个简单的例子,我们在vmvare环境下编写python程序,然后需要临时走开一下,但是我们又不想把这个vmvare关闭,这个时候我们可以选择挂机,这样我们再回来继续操作时候,就可以直接恢复到走之前的状态,那么我们之前编写的代码及vmvare的状态是保存在哪里了呢,实际上是保存在文件当中来了,但是我们知道文件只能对字符串这种类型的数据进行处理,这时候在操作过程中,当我们将数据存入文件当中的时候,我们就需要将python对象的编码格式转换成字符串格式,即序列化,同样的,当我们在恢复python中的编码时候,就需要把字符串的编码格式转换成我们需要的编码格式,即所谓的反序列化。而恰好python中的json和pickle模块可以用来实现这一功能
json
json提供了四个功能:dumps,dump,loads,load(前面两个都是用来实现序列化的,后面两个用来实现反序列化)
首先我们来看一下如果不用json序列化到底能不能实现对文件的操作
我们创建一个文件,向里面存入一个字典看看行不行
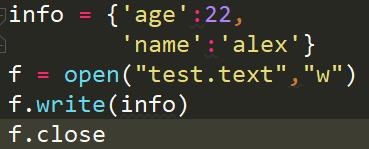
结果呢

很明显报错了,告诉我们写进文件的内容一定得是字符串格式的,不是字典。
我们试着用json模块写入吧
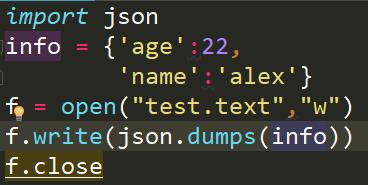
结果创建了一个文件,并且相应的内容也写进去了

上面我们用了json的dumps功能实现的序列化,我们再用dump实现一下,代码简化了
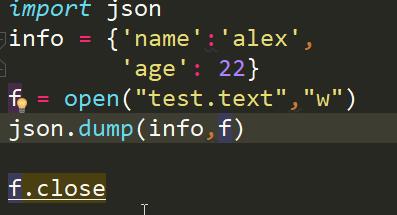
结果是一样的
我们再来看看反序列化
如果我们不用反序列化,看看能不能找到字典中的name对应的额元素呢
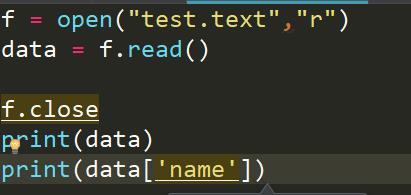
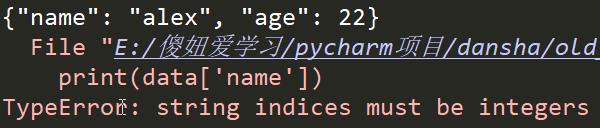
结果是不可以的
那我们来导入json模块吧
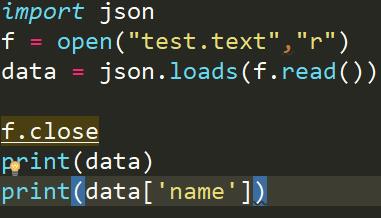

我们再用json的另一个反序列化功能load写一下这段代码
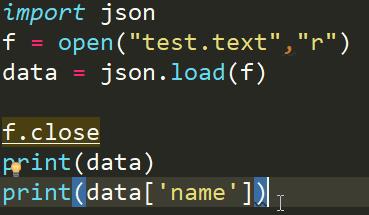
结果是一样的
看起来json的功能很强大但是他只能用来实现对列表,字典,字符串这样简单的数据类型进行处理,对于复杂的比如函数就处理不了了,但是他有他的优点,就是可以实现与java等其他语言的交互,鉴于json的局限性,我们试一试pickle吧,他能实现对一切对象的序列化及反序列化操作,但是他不能实现与其他语言的交互
我们先来看看json遇到复杂对象的情况,为此我们定义了一个niusha函数,将他的内存地址添加到字典中
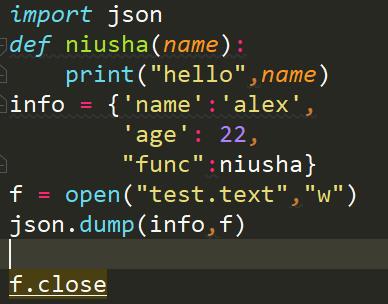
结果似乎差强人意啊

报错了
我们再用pickle试试
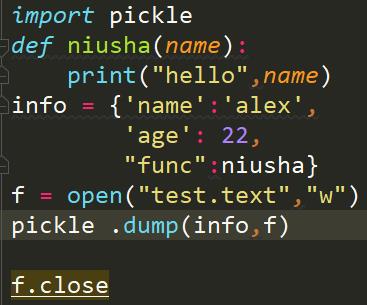
结果怎么变成了这样

注意哈,这里我们用pickle.dumps默认变成了二进制。所以报错了。我们需要改动一下
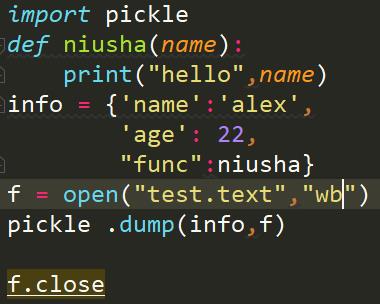
将文件的写的方式改为“wb”即可
我们再来看看pickle的反序列化
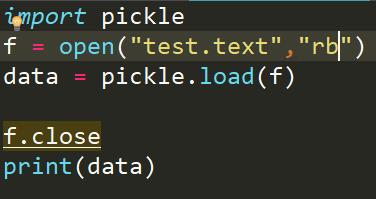
结果怎么出错了呢

这是因为我们在序列化中定义的niusha函数,使用完之后就被释放了,所以我们在反序列化过程中找不到这个函数,这里我们是为了证明pickle可以序列化函数等复杂的对象,在实际中是不应该这样用的,如果是在要这么用,我们只能将序列化中的代码copy过来
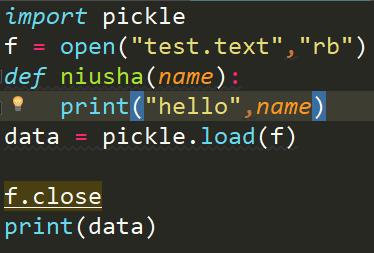
这样结果就出来了

注意,这里我们都只是尝试了pickle的dump,与load方法,他的dumps功能与loads功能与json用法是一样的,这里就不再描述了
以上是关于python序列化与反序列化(json与pickle)的主要内容,如果未能解决你的问题,请参考以下文章