python3-开发进阶Flask的基础
Posted 明天的希望,让我们忘了今天的痛苦。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3-开发进阶Flask的基础相关的知识,希望对你有一定的参考价值。
内容概要:
- SQLAlchemy
- flsak-sqlalchemy
- flask-script
- flask-migrate
- Flask的目录结构
一、SQLAlchemy
1、概述
SQLAlchemy是一个ORM的框架,ORM就是关系对象映射,具体可以参照Django中的ORM。
作用:帮助我们使用类和对象快速实现数据库操作
数据库:
-原生:MYSQLdb pymysql
区别就是 MYSQLdb 不支持python3 pymysql 都支持
ORM框架
SQLAlchemy
2、SQLAlchemy用法
1、安装
pip3 install sqlalchemy
2、配置


from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column from sqlalchemy import Integer,String,Text,Date,DateTime from sqlalchemy import create_engine Base = declarative_base() class Users(Base): __tablename__ = \'users\' id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) def create_all(): engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/duoduo123?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.create_all(engine) def drop_all(): engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/duoduo123?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.drop_all(engine) if __name__ == \'__main__\': create_all()
3、增删改查的演示
from duoduo.test import Users from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/duoduo123?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) #根据Users类对user表进行增删改查 session=SessionFactory() #增加 #单个 # obj=Users(name=\'many qian\') # session.add(obj) # session.commit() #多个 # session.add_all([ # Users(name=\'大娃\'), # Users(name=\'二娃\') # ]) # session.commit() #查 所有 # tes=session.query(Users).all() # print(tes) #拿到的对象 # for row in tes: # print(row.id,row.name) # tes=session.query(Users).filter(Users.id==3) #> < >= <= # # for row in tes: # print(row.id,row.name) # # tes=session.query(Users).filter(Users.id<=3).first()#> < >= <= # # print(tes.id,tes.name) #删除 # tes=session.query(Users).filter(Users.id==3).delete() #> < >= <= # session.commit() #改 # session.query(Users).filter(Users.id ==4).update({Users.name:\'三娃\'}) # session.query(Users).filter(Users.id ==4).update({\'name\':\'四娃\'}) # session.query(Users).filter(Users.id ==4).update({\'name\':Users.name+\'NICE\'},synchronize_session=False) # session.commit() # # # session.close()
4、单表常用操作
# ############################## 其他常用 ############################### # 1. 指定列 # select id,name as cname from users; # result = session.query(Users.id,Users.name.label(\'cname\')).all() # for item in result: # print(item[0],item.id,item.cname) # 2. 默认条件and # session.query(Users).filter(Users.id > 1, Users.name == \'duoduo\').all() # 3. between # session.query(Users).filter(Users.id.between(1, 3), Users.name == \'duoduo\').all() # 4. in # session.query(Users).filter(Users.id.in_([1,3,4])).all() # session.query(Users).filter(~Users.id.in_([1,3,4])).all() # 5. 子查询 # session.query(Users).filter(Users.id.in_(session.query(Users.id).filter(Users.name==\'duoduo\'))).all() # 6. and 和 or # from sqlalchemy import and_, or_ # session.query(Users).filter(Users.id > 3, Users.name == \'duoduo\').all() # session.query(Users).filter(and_(Users.id > 3, Users.name == \'duoduo\')).all() # session.query(Users).filter(or_(Users.id < 2, Users.name == \'duoduo\')).all() # session.query(Users).filter( # or_( # Users.id < 2, # and_(Users.name == \'duoduo\', Users.id > 3), # Users.extra != "" # )).all() # 7. filter_by # session.query(Users).filter_by(name=\'duoduo\').all() # 8. 通配符 # ret = session.query(Users).filter(Users.name.like(\'d%\')).all() #%任何的东西 # ret = session.query(Users).filter(~Users.name.like(\'d_\')).all() #_ 只有一个字符 # 9. 切片 # result = session.query(Users)[1:2] # 10.排序 # ret = session.query(Users).order_by(Users.name.desc()).all() # ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() #desc从大到小 asc从小到大排 # 11. group by from sqlalchemy.sql import func # ret = session.query( # Users.depart_id, # func.count(Users.id), # ).group_by(Users.depart_id).all() # for item in ret: # print(item) # # from sqlalchemy.sql import func #进行二次筛选,只能用having # ret = session.query( # Users.depart_id, # func.count(Users.id), # ).group_by(Users.depart_id).having(func.count(Users.id) >= 2).all() # for item in ret: # print(item) # 12.union 去重 和 union all 上下拼接不去重 """ select id,name from users UNION select id,name from users; """ # q1 = session.query(Users.name).filter(Users.id > 2) # q2 = session.query(Users.name).filter(Users.id > 2) # ret = q1.union(q2).all() # # q1 = session.query(Users.name).filter(Users.id > 2) # q2 = session.query(Users.name).filter(Users.id > 2) # ret = q1.union_all(q2).all() session.close()
5、连表常用操作
在上面的配置里,重新搞两给表
from sqlalchemy import ForeignKey from sqlalchemy.orm import relationship #按照上面配置的代码加上这些东西,配置的表删除 class Depart(Base): __tablename__ = \'depart\' id = Column(Integer, primary_key=True) title = Column(String(32), index=True, nullable=False) class Users(Base): __tablename__ = \'users\' id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) depart_id = Column(Integer,ForeignKey("depart.id")) #跟表结构无关 dp = relationship("Depart", backref=\'pers\')
下面是实例演示:之前自己添加一点数据:
#django的manytomany 在flask中两个ForeignKey完成 from duoduo.test import Users,Depart,Student,Course,Student2Course from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/duoduo123?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) #根据Users类对user表进行增删改查 session=SessionFactory() # #1、查询所有用户 # # ret =session.query(Users).all() # # # # for i in ret: # # print(i.id,i.name,i.depart_id) #2、查询所有用户,所属部门名称 # ret=session.query(Users.id,Users.name,Depart.title).join(Depart,User.depart_id==Depart.id).all() # #这里有默认ForeignKey ,User.depart_id==Depart.id 可以不加也行 # for i in ret: # print(i.id ,i.name,i.title) #SELECT users.id AS users_id, users.name AS users_name, depart.title AS depart_title #FROM users INNER JOIN depart ON depart.id = users.depart_id # q=session.query(Users.id,Users.name,Depart.title).join(Depart) # print(q) #3、relation字段:查询所有用户+所有部门名称 # ret=session.query(Users).all() # for row in ret: # print(row.id,row.name,row.depart_id,row.dp.title) #4、relation字段:查询销售部所有人员 # obj=session.query(Depart).filter(Depart.title ==\'大娃\').first() # # for i in obj.pers: # # print(i.id,i.name,obj.title) #5、创建一个名称叫:IT部门,再在该部门中添加一个员工叫:多多 #方式一: # d1=Depart(title=\'IT\') # session.add(d1) # session.commit() # # u1=Users(name=\'duoduo\',depart_id=d1.id) # session.add(u1) # session.commit() #方式二: # u1=Users(name=\'多多1\',dp=Depart(title=\'IT\')) # session.add(u1) # session.commit() #6、创建一个部门叫王者荣耀,这个部门添加多个员工:亚瑟,后裔,貂蝉 # d1=Depart(title=\'王者荣耀\') # d1.pers=[Users(name=\'亚瑟\'),Users(name=\'后裔\'),Users(name=\'貂蝉\')] # # session.add(d1) # session.commit() #1、录入数据 # session.add_all([ # Student(name=\'大娃\'), # Student(name=\'二娃\'), # Course(title=\'物理\'), # Course(title=\'化学\'), # # ]) # session.add_all([ # Student2Course(student_id=2,course_id=1), # # Student2Course(student_id=1,course_id=2) # ] # ) #2、查每个人选了课程的名称,三张表进行关联 # ret=session.query(Student2Course.id,Student.name,Course.title).join(Student,Student2Course.student_id==Student.id,isouter=True).join(Course,Student2Course.course_id==Course.id,isouter=True).order_by(Student2Course.id.asc()) # for i in ret: # print(i) #3、\'大娃\'所选的所有课 # ret=session.query(Student2Course.id,Student.name,Course.title).join(Student,Student2Course.student_id==Student.id,isouter=True).join(Course,Student2Course.course_id==Course.id,isouter=True).filter(Student.name==\'大娃\').order_by(Student2Course.id.asc()) # # for i in ret: # print(i) # obj=session.query(Student).filter(Student.name==\'大娃\').first() # for item in obj.course_list: # print(item.title) #4选了\'化学\'课程的所有人的名字 # obj=session.query(Course).filter(Course.title==\'化学\').first() # for item in obj.student_list: # print(item.name) #创建一个课程,创建2个学,两个学生选新创建的课程 # obj=Course(title=\'体育\') # obj.student_list=[Student(name=\'五娃\'),Student(name=\'六娃\')] # # session.add(obj) # session.commit() # session.close()
class Student(Base): __tablename__ = \'student\' id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) course_list = relationship(\'Course\', secondary=\'student2course\', backref=\'student_list\') class Course(Base): __tablename__ = \'course\' id = Column(Integer, primary_key=True) title = Column(String(32), index=True, nullable=False) class Student2Course(Base): __tablename__ = \'student2course\' id = Column(Integer, primary_key=True, autoincrement=True) student_id = Column(Integer, ForeignKey(\'student.id\')) course_id = Column(Integer, ForeignKey(\'course.id\')) __table_args__ = ( UniqueConstraint(\'student_id\', \'course_id\', name=\'uix_stu_cou\'), # 联合唯一索引 # Index(\'ix_id_name\', \'name\', \'extra\'), # 联合索引 )
连接的方式:
from duoduo.test import Users,Depart,Student,Course,Student2Course from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/duoduo123?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) #连接 #第一种方式 # #并发 # def task(): # #去连接池获取一个连接 # session=SessionFactory() # ret=session.query(Student).all() # print(ret) # #将连接交还给连接池 # session.close() # # # from threading import Thread # # for i in range(20): # t=Thread(target=task) # t.start() # #第二种方式 from sqlalchemy.orm import scoped_session session=scoped_session(SessionFactory) def task(): ret=session.query(Student).all() print(ret) session.remove() #连接断开 from threading import Thread for i in range(20): t=Thread(target=task) t.start()
执行原生SQ:
from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session from models import Student,Course,Student2Course engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/duoduo123?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) SessionFactory = sessionmaker(bind=engine) session = scoped_session(SessionFactory) def task(): """""" # 方式一: """ # 查询 # cursor = session.execute(\'select * from users\') # result = cursor.fetchall() # 添加 cursor = session.execute(\'INSERT INTO users(name) VALUES(:value)\', params={"value": \'duoduo\'}) session.commit() print(cursor.lastrowid) """ # 方式二: """ # conn = engine.raw_connection() # cursor = conn.cursor() # cursor.execute( # "select * from t1" # ) # result = cursor.fetchall() # cursor.close() # conn.close() """ # 将连接交还给连接池 session.remove() from threading import Thread for i in range(20): t = Thread(target=task) t.start()
二、Flask的第三方组件
1、flask-sqlalchemy
a、先下载安装
pip3 install flask-sqlalchemy
b、项目下的__init__.py导入
#第一步 :导入并实例化SQLALchemy from flask_sqlalchemy import SQLAlchemy db=SQLAlchemy() #一定要在蓝图导入的上面,是全局变量
#也要导入表的models.py的所有表
c、初始化
db.init_app(app) #在注册蓝图的地方的下面
d、在配置文件中写入配置
# ##### SQLALchemy配置文件 ##### SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:123@127.0.0.1:3306/duoduo?charset=utf8" SQLALCHEMY_POOL_SIZE = 10 SQLALCHEMY_MAX_OVERFLOW = 5
e、创建models.py中的类(对应数据库中的表)
from sqlalchemy import Column from sqlalchemy import Integer,String,Text,Date,DateTime from (项目目录) import db class Users(db.Model): #继承的db.Model __tablename__ = \'users\' id = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=False) # depart_id = Column(Integer)
f、生成表(使用app上下文)
from (项目目录) import db,create_app app = create_app() app_ctx = app.app_context() # app_ctx = app/g with app_ctx: # __enter__,通过LocalStack放入Local中 db.create_all() # 调用LocalStack放入Local中获取app,再去app中获取配置
补充一个知识点:
class Foo(object): def __enter__(self): print(\'进入\') def __exit__(self, exc_type, exc_val, exc_tb): print(\'出来\') obj =Foo() with obj: #with Foo() print(\'多多\') #结果 #进入 #多多 #出来
g、基于ORM对数据库进行操作
from flask import Blueprint from (项目目录) import db from (项目目录) import models us = Blueprint(\'us\',__name__) @us.route(\'/index\') def index(): # 使用SQLAlchemy在数据库中插入一条数据 # db.session.add(models.Users(name=\'多多\',depart_id=1)) #插入数据 # db.session.commit() # db.session.remove() result = db.session.query(models.Users).all() print(result) db.session.remove() return \'Index\'
这里面db.session.add的源码:
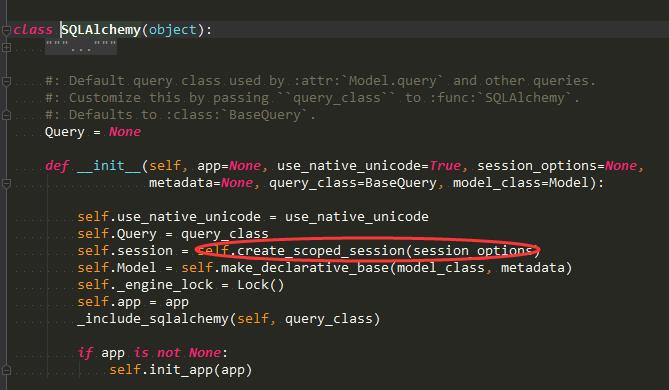
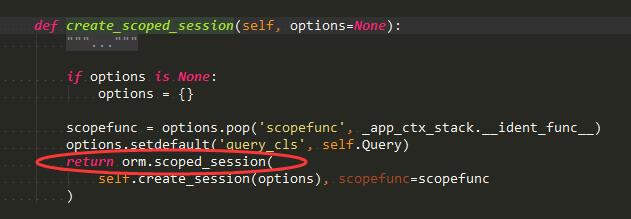
2、 flask-script
下载安装
pip3 install flask-script
功能:
a、增加runsever
from (项目目录) import create_app from flask_script import Manager app = create_app() manager = Manager(app) if __name__ == \'__main__\': # app.run() manager.run()
b、位置传参
from (项目目录) import create_app from flask_script import Manager app = create_app() manager = Manager(app) @manager.command def custom(arg): """ 自定义命令 python manage.py custom 123 :param arg: :return: """ print(arg) if __name__ == \'__main__\': # app.run() manager.run()
c、关键字传参
from flask_script import Manager from (项目目录) import create_app app = create_app() manager = Manager(app) @manager.option(\'-n\', \'--name\', dest=\'name\') @manager.option(\'-u\', \'--url\', dest=\'url\') def cmd(name, url): """ 自定义命令 执行: python manage.py cmd -n qianduoduo -u http://www.baidu.com :param name: :param url: :return: """ print(name, url) if __name__ == \'__main__\': # app.run() manager.run()
3、flask-migrate
安装
pip3 install flask-migrate
配置是依赖 flask-script
from flask_script import Manager from flask_migrate import Migrate, MigrateCommand from (项目目录) import create_app from (项目目录) import db app = create_app() manager = Manager(app) Migrate(app, db) """ # 数据库迁移命名 python manage.py db init #只执行一次 python manage.py db migrate # makemirations python manage.py db upgrade # migrate """ manager.add_command(\'db\', MigrateCommand) if __name__ == \'__main__\': # app.run() manager.run()
补充工具:(协同开发的保证开发的环境一致性)
1、pipreqs
找到项目使用的所有组件的版本
pip3 install pipreqs
在项目中的命令行
pipreqs ./ --encoding=utf-8
在项目中找了文件requirements.txt
如何装那些模块?
pip install 的时候可以指定一个文件,他会自己读每一行,然后安装
pycharm 打开文件的时候也会提示下载
2、虚拟环境 (开发环境版本不能共存的)
安装
pip3 install virtualenv
创建虚拟环境
#找一个存放虚拟环境的文件夹 virtualenv env1 --no-site-packages 创建环境 activate #激活环境 deactivate # 退出环境 #也可以用pycharm鼠标点点就好了,最新的版本就有虚拟环境goon功能 #当我们需要特定的环境,可以在电脑上有多高开发环境
以上是关于python3-开发进阶Flask的基础的主要内容,如果未能解决你的问题,请参考以下文章
分享《Flask Web开发实战:入门进阶与原理解析》PDF+源代码
《Flask Web开发实战:入门进阶与原理解析》PDF+源代码