postgresql copy from 文件,文件字段包含双引号怎么处理?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了postgresql copy from 文件,文件字段包含双引号怎么处理?相关的知识,希望对你有一定的参考价值。
可以使用类似这样的命令进行导入:1
2
3
4
5
6
7
8
9
copy
target_table_name
(field_1,
field_2,
field_3)
from
'C:\sourceData.txt'
with
(
FORMAT
csv,
DELIMITER
',',
escape
'\',
header
true,
quote
'"',
encoding
'UTF8')
这里,
with后面括号中跟的是导入参数设置:
format指定导入的文件格式为csv格式
delimiter指定了字段之间的分隔符号位逗号
escape指定了在引号中的转义字符为反斜杠,这样即使在引号字串中存在引号本身,也可以用该字符进行转义,变为一般的引号字符,而不是字段终结
header
true:指定文件中存在表头。如果没有的话,则设置为false
quote指定了以双引号作为字符串字段的引号,这样它会将双引号内的内容作为一个字段值来进行处理
encoding指定了文件的编码格式为utf8,
如果是别的格式则修改为适当的编码格式. 参考技术A 可以使用类似这样的命令进行导入:
copy target_table_name (field_1, field_2, field_3)
from 'C:\sourceData.txt'
with (
FORMAT csv,
DELIMITER ',',
escape '\',
header true,
quote '"',
encoding 'UTF8')这里,
with后面括号中跟的是导入参数设置:
format指定导入的文件格式为csv格式
delimiter指定了字段之间的分隔符号位逗号
escape指定了在引号中的转义字符为反斜杠,这样即使在引号字串中存在引号本身,也可以用该字符进行转义,变为一般的引号字符,而不是字段终结
header
true:指定文件中存在表头。如果没有的话,则设置为false
quote指定了以双引号作为字符串字段的引号,这样它会将双引号内的内容作为一个字段值来进行处理
encoding指定了文件的编码格式为utf8, 如果是别的格式则修改为适当的编码格式.本回答被提问者采纳
postgresql----COPY之表与文件之间的拷贝
postgresql提供了COPY命令用于表与文件(和标准输出,标准输入)之间的相互拷贝,copy to由表至文件,copy from由文件至表。
示例1.将整张表拷贝至标准输出
test=# copy tbl_test1 to stdout; 1 HA 12 2 ha 543
示例2.将表的部分字段拷贝至标准输出,并输出字段名称,字段间使用\',\'分隔
test=# copy tbl_test1(a,b) to stdout delimiter \',\' csv header; a,b 1,HA 2,ha
示例3.将查询结果拷贝至标准输出
test=# copy (select a,b from tbl_test1 except select e,f from tbl_test2 ) to stdout delimiter \',\' quote \'"\' csv header; a,b 2,ha
将标准输入拷贝至表中需要注意几点
1.字段间分隔符默认使用【Tab】键
2.换行使用回车键
3.结束使用反斜线+英文据点(\\.)
4.最好指定字段顺序,要不然可能会错位赋值
示例4.将标准输入拷贝至表中
test=# copy tbl_test1(a,b,c) from stdin; Enter data to be copied followed by a newline. End with a backslash and a period on a line by itself. >> 1 公举 公主 >> 2 万岁 万万岁 >> \\. COPY 2 test=# select * from tbl_test1 ; a | b | c ---+------+-------- 1 | HA | 12 2 | ha | 543 1 | 公举 | 公主 2 | 万岁 | 万万岁 (4 rows)
示例5.从标准输入拷贝至表中,并将标准输入第一行作为字段名(和表中不符也没关系,copy会自动忽略第一行),字段分隔符为\',\'
test=# copy tbl_test1(a,b,c) from stdin delimiter \',\' csv header; Enter data to be copied followed by a newline. End with a backslash and a period on a line by itself. >> a,b,c >> 3,你好,hello >> 4,超人,super >> \\. COPY 2 test=# select * from tbl_test1 ; a | b | c ---+------+-------- 1 | HA | 12 2 | ha | 543 1 | 公举 | 公主 2 | 万岁 | 万万岁 3 | 你好 | hello 4 | 超人 | super (6 rows)
以上是表与标准输出和标准输入间的相互拷贝,表与文件的拷贝和以上完全相同,只是将标准输出和标准输入换成文件。需要注意的是:
1.数据库用户必须有文件所在的路径的写权限。
2.如果表存在中文字符,导出至csv文件时需要设置编码为GBK,否则使用excel打开是中文显示乱码。
3.将文件导入表中时仍要考虑编码问题
示例6.将表拷贝至csv文件中
test=# copy tbl_test1 to \'/tmp/tbl_test1.csv\' delimiter \',\' csv header; COPY 6
使用excel打开文件,中文显示为乱码

示例7. 将表以GBK编码拷贝至csv文件中
test=# copy tbl_test1 to \'/tmp/tbl_test1.csv\' delimiter \',\' csv header encoding \'GBK\'; COPY 6
使用excel打开,中文显示正常
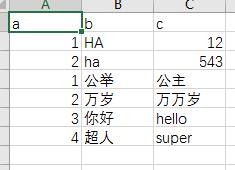
示例8.将刚才导出的文件再次拷贝至表中,使用默认编码UTF8
test=# copy tbl_test1(a,b,c) from \'/tmp/tbl_test1.csv\' delimiter \',\' csv header; ERROR: invalid byte sequence for encoding "UTF8": 0xb9 CONTEXT: COPY tbl_test1, line 4
示例9.将刚才导出的文件再次拷贝至表中,使用GBK编码
test=# copy tbl_test1(a,b,c) from \'/tmp/tbl_test1.csv\' delimiter \',\' csv header encoding \'GBK\'; COPY 6
以上是关于postgresql copy from 文件,文件字段包含双引号怎么处理?的主要内容,如果未能解决你的问题,请参考以下文章
postgresql copy from 字符串转换为时间类型
COPY FROM .csv 文件到远程 PostgreSQL 数据库(在 Linux 服务器上运行)
在 PostgreSQL 中使用 COPY FROM 命令在多个表中插入
PostgreSQL的“COPY table FROM file”语句可以在Go中使用吗?