易于理解的 python 深度学习摘要算法教程
Posted 冷月长空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了易于理解的 python 深度学习摘要算法教程相关的知识,希望对你有一定的参考价值。
序
“我不想要一份完整的报告,只要给我一份结果摘要就好”。我经常发现自己处于这种状况 -- 无论是在大学里还是在我的职业生涯中。我们准备一份全面的报告,但老师/主管却只有时间阅读摘要。
听起来很熟悉吧?嗯,我决定做点什么。手动将报告转换为汇总版本太耗时了,对吗?我能依靠吗 自然语言处理 (NLP) 帮助我的技巧?
这就是使用深度学习进行文本摘要真正帮助我的地方。它解决了一个一直困扰我的问题- 现在我们的模型可以理解整个文本的上下文 。对于我们所有需要快速知道文件摘要的人来说,这是一个梦想成真!
以及我们在深度学习中使用文本摘要获得的结果?了不起。因此,我在本文中,我们将逐步介绍构建 使用深度学习的文本摘要器 通过覆盖构建它所需的所有概念。然后,我们将在 Python 中实现我们的第一个文本摘要模型!
-
[A Must-Read Introduction to Sequence Modelling (with use cases)](https://www.analyticsvidhya.com/blog/2018/04/sequence-modelling-an-introduction-with-practical-use-cases/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python)
-
[Must-Read Tutorial to Learn Sequence Modeling (deeplearning.ai Course #5)](https://www.analyticsvidhya.com/blog/2019/01/sequence-models-deeplearning/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python)
-
[Essentials of Deep Learning: Introduction to Long Short Term Memory](https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python)
目录
- NLP中的文本摘要是什么?
- 序列到序列 (Seq2Seq) 建模介绍
- 了解编码器 - 解码器体系结构
- 编码器局限性 - 解码器体系结构
- 注意机制背后的直觉
- 理解问题说明书
- 使用 Keras 在 Python 中实现文本摘要
- 如何进一步提高模型的性能?
- 注意力机制是如何工作的?
1. NLP中的文本摘要是什么?
让我们先了解什么是文本摘要,然后再看看它是如何工作的。这里有一个简洁的定义来帮助我们开始:
“自动文本摘要是在保留关键信息内容和总体意义的同时生成简洁流畅的摘要的任务”
-文本总结技术: 简要调查,2017
有大致两种不同的方法用于文本总结:
- 提取概括
- 抽象概括
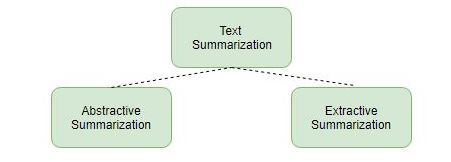
让我们更详细地看看这两种类型。
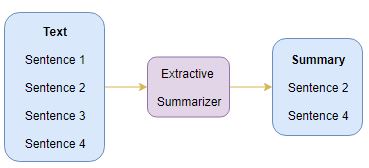
1.1 提取摘要
这个名字透露了这种方法的作用。 我们从原文中识别出重要的句子或短语,并且只从原文中提取那些。 那些提取的句子将是我们的总结。下图说明了提取摘要:
我建议仔细阅读下面的文章,使用TextRank算法构建提取文本摘要器:
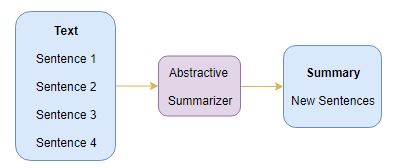
1.2 抽象摘要
这是一个非常有趣的方法。这里, 我们从原文生成新句子。 这与我们之前看到的只使用存在的句子的提取方法相反。通过抽象总结生成的句子可能不会出现在原文中:
你可能已经猜到了 -- 我们将在本文中使用深度学习来构建一个抽象的文本摘要器!在深入了解实现部分之前,让我们首先了解构建文本摘要器模型所需的概念。
前方是激动人心的时刻!
2. 序列到序列 (Seq2Seq) 建模介绍
我们可以针对涉及顺序信息的任何问题构建Seq2Seq模型。这包括情感分类、神经机器翻译和命名实体识别 -- 顺序信息的一些非常常见的应用。
在神经机器翻译的情况下,输入是一种语言的文本,输出也是另一种语言的文本:

在命名实体识别中,输入是单词序列,输出是输入序列中每个单词的标签序列:
我们的目标是构建一个文本摘要器,其中输入是一个长的单词序列 (在文本正文中),输出是一个短的摘要 (也是一个序列)。所以, 我们可以将其建模为****多对多Seq2Seq问题。 以下是典型的Seq2Seq模型架构:
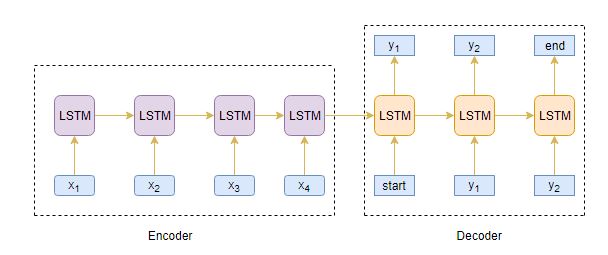
Seq2Seq 模型有两个主要组成部分:
- 编码器
- 解码器
让我们详细了解这两个。这些对于理解文本摘要在代码下是如何工作是至关重要的。您也可以前往 本教程 更详细地理解序列到序列建模。
3. 了解编码器-解码器体系结构
编码器-解码器体系结构主要用于解决输入和输出序列长度不同的序列到序列 (Seq2Seq) 问题。
让我们从文本摘要的角度来理解这一点。输入是一个长的单词序列,输出将是输入序列的短版本。
通常,递归神经网络 (RNNs) 的变体,即门控递归神经网络 (GRU) 或长期短期记忆 (LSTM) 作为编码器和解码器组件是优选的。这是因为他们能够通过克服梯度消失的问题来捕捉长期依赖性。
我们可以分两个阶段设置编码器解码器:
- 训练阶段
- 推理阶段
让我们通过LSTM模型的镜头来理解这些概念。
3.1 训练阶段
在训练阶段,我们将首先设置编码器和解码器。然后,我们将训练模型以预测目标序列偏移一个时间步。让我们详细了解如何设置编码器和解码器。
编码器
编码器长期短期存储模型 (LSTM) 读取整个输入序列,其中在每个时间步,一个字被输入编码器。然后,它在每个时间步处理信息,并捕获输入序列中存在的上下文信息。
我把下面的图表放在一起,说明了这个过程:
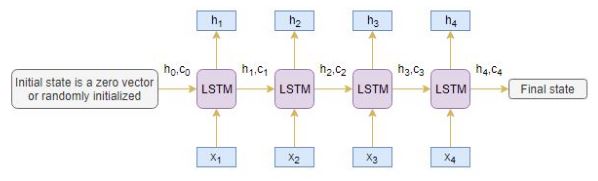
隐藏状态 (h我) 和细胞状态 (c我) 的最后一个时间步骤用于初始化解码器。请记住,这是因为编码器和解码器是LSTM体系结构的两组不同。
解码器
解码器也是一个LSTM网络,它逐字读取整个目标序列,并通过一个时间步预测相同的序列偏移。 解码器被训练以预测给定前一个单词的序列中的下一个单词。
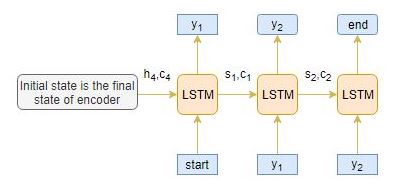
「开始」 和 「结束」是在将目标序列输入解码器之前添加到目标序列中的特殊标记。解码测试序列时目标序列未知。因此,我们开始通过将第一个单词传递到解码器来预测目标序列,该解码器始终是 「开始」指令和 「**结束」**令牌表示句子的结尾。
到目前为止相当直观。
3.2 预测阶段
训练后,在目标序列未知的新源序列上测试模型。因此,我们需要设置推理架构来解码测试序列:
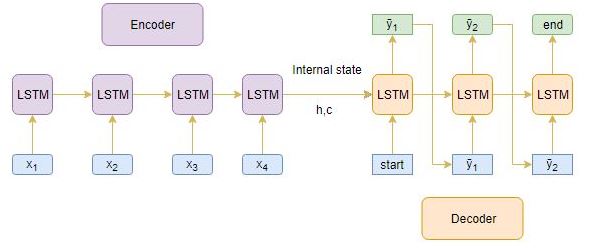
预测过程是如何工作的?
以下是解码测试序列的步骤:
- 对整个输入序列进行编码,并用编码器的内部状态初始化解码器
- 通过 <**开始>**令牌作为解码器的输入
- 使用内部状态运行解码器一次
- 输出将是下一个单词的概率。将选择具有最大概率的单词
- 在下一个时间步中将采样的字作为输入传递给解码器,并用当前时间步更新内部状态
- 重复步骤3-5,直到我们生成 <**结束>**标记或命中目标序列的最大长度
让我们举一个由 [x给出测试序列的例子1,X2,X3,X4]。对于这个测试序列,推理过程是如何工作的?我想让你在看下面我的想法之前先考虑一下。
- 将测试序列编码为内部状态向量
- 观察解码器如何在每个时间步预测目标序列:
时间步长: t = 1
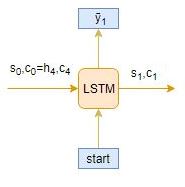
时间步长: t = 2
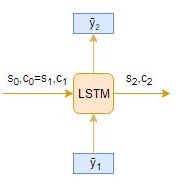
和,时间步长: t = 3

4.编码器的局限性 - 解码器体系结构
尽管这种编码器-解码器体系结构很有用,但它也有一定的局限性。
- 编码器将整个输入序列转换为固定长度矢量,然后解码器预测输出序列。这仅适用于短序列 由于解码器正在查看预测的整个输入序列
- 长序列的问题来了。 编码器很难将长序列记忆成固定长度的向量
“这种编码器-解码器方法的一个潜在问题是,神经网络需要能够将源句子的所有必要信息压缩为固定长度的向量。这可能使神经网络难以处理长句。随着输入句子长度的增加,基本编码器-解码器的性能迅速下降。”
-通过共同学习对齐和翻译的神经机器翻译
那么我们如何克服长序列的问题呢?这是概念 注意机制 进入画面。它旨在通过仅查看序列的几个特定部分而不是整个序列来预测单词。这真的和听起来一样棒!
5. 注意力机制背后的直觉
在时间步长生成一个单词,我们需要对输入序列中的每个单词关注多少 T ?这是注意力机制概念背后的关键直觉。
让我们考虑一个简单的例子来了解注意力机制是如何工作的:
- 源序列: “你最喜欢哪项运动?
- 目标序列: “我喜欢板球”
第一个词I 在目标序列中连接到第四个单词 You 在源序列中,对吗?同样,第二个词“**爱”**在目标序列中与第五个单词相关联 “喜欢” 在源序列中。
因此,我们可以增加导致目标序列的源序列的特定部分的重要性,而不是查看源序列中的所有单词。 这是注意机制背后的基本思想。
根据参与的上下文向量的导出方式,有两种不同类别的注意力机制:
- 全球关注
- 局部关注
让我们简单地谈谈这些课程。
5.1 全局关注
在这里,注意力集中在所有的源位置上。换言之,编码器的所有隐藏状态都被考虑用于导出被关注的上下文向量:
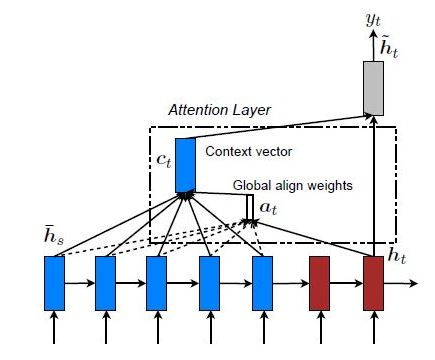
5.2 局部关注
在这里,注意力只放在几个源位置上。 仅考虑编码器的一些隐藏状态来导出参与的上下文向量:
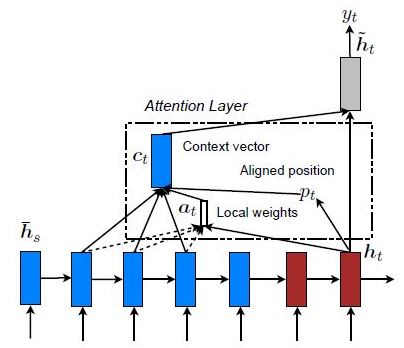
我们将在本文中使用全局注意力机制。
6. 理解问题陈述
顾客评论通常是长的和描述性的。可以想象,手动分析这些评论确实很耗时。这就是自然语言处理的辉煌之处,可以用来生成长时间评论的摘要。
我们将研究一个非常酷的数据集。 我们****这里的目标是使用我们在上面学到的基于抽象的方法为亚马逊美食评论生成一个摘要。
您可以从以下位置下载数据集这里。
7. 使用 Keras 在 Python 中实现文本摘要
是时候启动我们的Jupyter笔记本了!让我们立即深入了解实现细节。
7.1 自定义注意力层
Keras不正式支持注意层。因此,我们可以实现我们自己的注意层或使用第三方实现。我们将在本文中选择后一个选项。 您可以从以下位置下载注意力层 这里 并将其复制到另一个名为 注意py
让我们将其导入到我们的环境中:
7.2 导入库,读取数据集
该数据集由亚马逊美食评论组成。数据跨度超过10年,包括截至2012年10月的全部约500,000次审查。这些评论包括产品和用户信息、评分、纯文本评论和摘要。它还包括来自所有其他亚马逊类别的评论。
我们将对100,000篇评论进行抽样,以减少我们模型的培训时间。如果您的机器具有这种计算能力,请随意使用整个数据集来训练您的模型。
7.3 预处理,删除重复项和NA值
在进入模型构建部分之前,执行基本预处理步骤非常重要。使用混乱和未清理的文本数据是一个潜在的灾难性举动。所以在这一步中,我们将从文本中删除所有不需要的符号、字符等,这些不会影响我们问题的目标。
这是我们将用于扩展收缩的字典:
我们需要为预处理评论和生成摘要定义两种不同的功能,因为文本和摘要中涉及的预处理步骤略有不同。
A) 文本清理
让我们看一下数据集中的前10条评论,以了解文本预处理步骤:
数据 [‘文本‘][:10]
输出 :
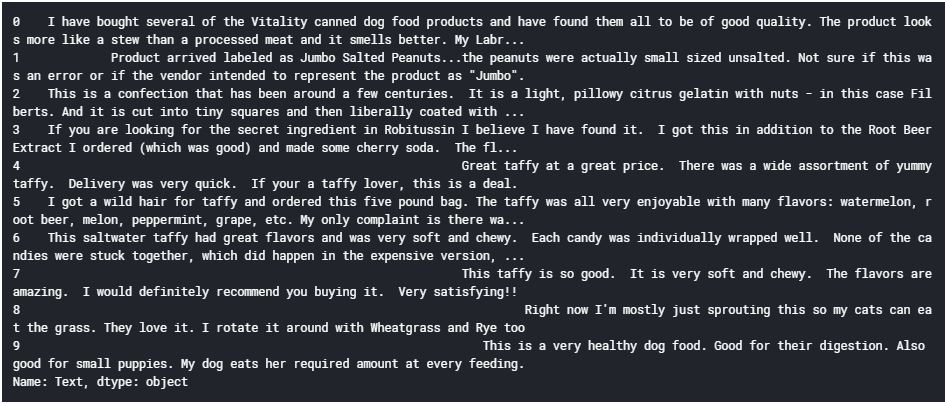
我们将为数据执行以下预处理任务:
- 将所有内容转换为小写
- 删除HTML标签
- 收缩映射
- 删除 ()
- 删除括号内的所有文本 ()
- 消除标点符号和特殊字符
- 删除停止符
- 删除短词
让我们定义函数:
B) 整理清洗
现在,我们将查看评论的前10行,以了解 “摘要” 列的预处理步骤:
输出 :
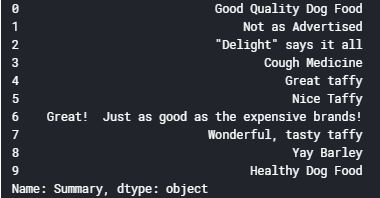
为此任务定义函数:
记得添加 启动 和 结束 摘要开头和结尾处的特殊令牌:
现在,让我们看一下前5条评论及其摘要:
输出 :

7.4 了解序列的分布
在这里,我们将分析评论的长度和摘要,以全面了解文本长度的分布。 这将帮助我们确定序列的最大长度:
输出 :
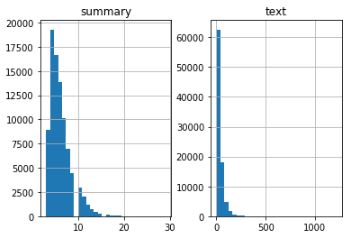
我们可以将评论的最大长度固定为80,因为这似乎是大多数评论的长度。同样,我们可以将最大摘要长度设置为10:
我们越来越接近模型构建部分。在此之前,我们需要将数据集拆分为训练和验证集。我们将使用数据集的90% 作为训练数据,并评估其余10% (保留集) 的性能:
7.5 准备标记器
标记器构建词汇表并将单词序列转换为整数序列。 继续为文本和摘要构建标记器:
A) 文本标记器
B) 摘要标记器
7.6 构建模型
我们终于进入了模型构建部分。但是在此之前,我们需要熟悉一些在构建模型之前需要的术语。
- **返回序列 = True:**当返回序列参数设置为 真正 ,LSTM为每个时间步产生隐藏状态和单元格状态
- **返回状态 = True:**当返回状态 = 真正 ,LSTM仅产生最后一个时间步的隐藏状态和单元格状态
- **初始状态:**这用于初始化第一个时间步骤的LSTM的内部状态
- **堆叠LSTM:**堆叠式LSTM有多层相互堆叠的LSTM。这导致序列的更好表示。我鼓励您尝试将LSTM的多层堆叠在一起 (这是学习此知识的好方法)
在这里,我们正在为编码器构建一个3堆叠的LSTM:
输出 :
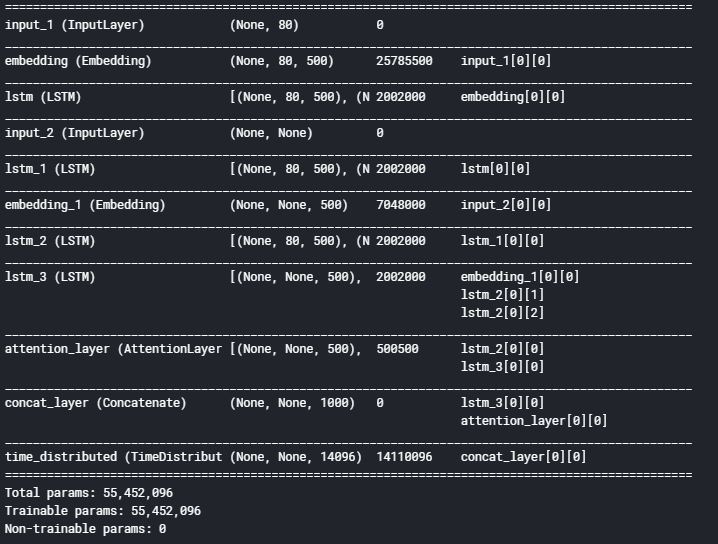
我正在使用稀疏分类交叉熵 作为损失函数,因为它会将整数序列动态转换为一个热向量。这克服了任何内存问题。
还记得提前停车的概念吗?它用于通过监视用户指定的度量标准在正确的时间停止训练神经网络。在这里,我正在监视验证丢失 (val_loss)。一旦验证损失增加,我们的模型将停止训练:
我们将在批处理大小为512的情况下训练模型,并在保留集 (占我们数据集的10%) 上对其进行验证:
7.7 了解诊断图
现在,我们将绘制一些诊断图,以了解模型随时间的行为:
输出 :
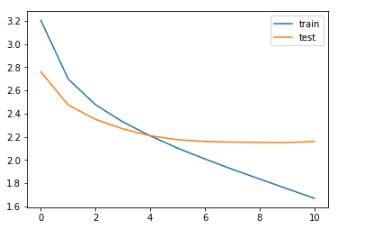
我们可以推断,在纪元10之后,验证损失略有增加。因此,我们将在该纪元之后停止训练该模型。
接下来,让我们构建字典,将索引转换为目标词汇和源词汇的单词:
推理
为编码器和解码器设置推理:
我们在下面定义一个函数,它是推理过程的实现 (我们在上节中讨论过):
让我们定义将整数序列转换为单词序列以进行摘要和评论的函数:
以下是模型生成的一些摘要:
这真的很酷。尽管实际的总结和我们模型生成的总结在文字方面不匹配,但它们都传达了相同的含义。我们的模型能够根据文本中的上下文生成清晰的摘要。这就是我们如何在Python中使用深度学习概念执行文本摘要。
8. 我们如何进一步提高模型的性能?
你的学习不止于此!你可以做更多的事情来尝试这个模型:
- 我建议你 增加训练数据集的大小 并建立模型。深度学习模型的泛化能力随着训练数据集大小的增加而增强
- 尝试 实现双向LSTM 它能够从两个方向捕获上下文并产生更好的上下文向量
- 使用 波束搜索策略 用于解码测试序列而不是使用贪婪方法 (argmax)
- 评价 您的模型的性能基于 蓝色分数
- 实现指针生成器网络 和覆盖机制
9. 注意力机制是如何工作的?
现在,让我们来谈谈注意机制的内部工作原理。正如我在文章开头提到的,这是一个数学繁重的部分,所以把它看作是可选的学习。我仍然强烈建议通读这篇文章,以真正理解注意力机制是如何工作的。
- 编码器输出隐藏状态 ( H**J** ) 对于每个时间步J 在源序列中
- 同样,解码器输出隐藏状态 ( S**我** ) 对于每个时间步我 在目标序列中
- 我们计算一个被称为对准分数****(EIj),在此基础上,使用分数函数将源词与目标词对齐。校准 分数从源隐藏状态计算得出 HJ 和目标隐藏状态 S我 使用评分函数。这由:
** eij= score (si, hj )**
哪里 E**Ij** 表示目标时间步的对齐得分 我 和源时间步 J 。
根据所使用的评分功能的类型,有不同类型的注意机制。我在下面提到了一些流行的注意机制:

- 我们标准化校准分数使用softmax函数检索注意权重 ( A**Ij**):
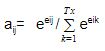
- 我们计算注意力权重的线性乘积之和 AIj 和编码器的隐藏状态 HJ 生产 参与的上下文向量 ( C**我**):
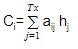
- 参与的上下文向量以及解码器在时间步的目标隐藏状态 我 连接以产生一个有参与的隐藏向量 S我
S我= 串联 ([s我; C我])
- 有人值守的隐藏矢量 S我 然后被送入致密层以产生 Y**我**
Y我= 密集 (秒我)
让我们借助一个例子来理解上述注意机制步骤。将源序列视为 [x1,X2,X3,X4] 和目标序列是 [y1,Y2]。
- 编码器读取整个源序列并输出每个时间步的隐藏状态,例如 H1,H2,H3,H4
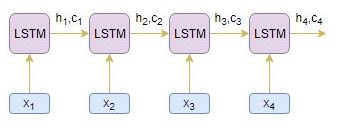
- 解码器读取偏移一个时间步的整个目标序列,并输出每个时间步的隐藏状态,例如 S1,S2,S3
目标时间步长i = 1
- 校准分数 E1j 从源隐藏状态计算 H我 和目标隐藏状态 S1 使用评分功能:
E11= 分数1,H1)
E12= 分数1,H2)
E13= 分数1,H3)
E14= 分数1,H4)
- 标准化校准分数 E1j 使用softmax可产生注意力权重 A1j :
A11= Exp (e11)/((Exp (e11) + Exp (e12) + Exp (e13) + Exp (e14))
A12= Exp (e12)/(Exp (e11) + Exp (e12) + Exp (e13) + Exp (e14))
A13= Exp (e13)/(Exp (e11) + Exp (e12) + Exp (e13) + Exp (e14))
A14= Exp (e14)/(Exp (e11) + Exp (e12) + Exp (e13) + Exp (e14))
- 参与上下文向量 C**1** 由编码器隐藏状态的乘积的线性和导出 H**J** 和校准分数 A**1j**:
C1= H1* A11+ H2* A12+ H3* A13+ H4* A14
- 参与上下文向量 C1 和目标隐藏状态 S1 连接以产生一个有参与的隐藏向量 S1
S1= 串联 ([s1; C1])
- 注意隐藏向量 S1 然后被送入致密层以产生 Y**1**
Y1= 密集 (秒1)
目标时间步长i = 2
- 校准分数 E2j 从源隐藏状态计算 H我 和目标隐藏状态 S2 使用给定的分数函数
E21= 分数2,H1)
E22= 分数2,H2)
E23= 分数2,H3)
E24= 分数2,H4)
- 标准化校准分数 E**2j** 使用softmax可产生注意力权重 A**2j**:
A21= Exp (e21)/(Exp (e21) + Exp (e22) + Exp (e23) + Exp (e24))
A22= Exp (e22)/(Exp (e21) + Exp (e22) + Exp (e23) + Exp (e24))
A23= Exp (e23)/(Exp (e21) + Exp (e22) + Exp (e23) + Exp (e24))
A24= Exp (e24)/(Exp (e21) + Exp (e22) + Exp (e23) + Exp (e24))
- 参与上下文向量 C2 由编码器隐藏状态的乘积的线性和导出 H我 对齐得分a 2j :
C2= H1* A21+ H2* A22+ H3* A23+ H4* A24
- 参与上下文向量 C2 和目标隐藏状态 S2 连接以产生一个有参与的隐藏向量 S2
S2= 串联 ([s2; C2])
- 有人参与隐藏矢量 S2 然后被送入致密层以产生 Y2
Y2= 密集 (秒2)
我们可以对目标时间步骤i = 3执行类似的步骤来产生 Y**3.**
我知道这是大量的数学和理论,但是现在理解这一点将有助于你掌握注意力机制背后的基本思想。这催生了NLP的许多最新发展,现在你已经准备好留下自己的印记了!
示例代码
找到整个笔记本 这里 。
写在最后
深呼吸 -- 我们在这篇文章中谈到了很多地方。恭喜您使用深度学习构建了第一个文本摘要模型!我们已经了解了如何使用 Python 中的 Seq2Seq 建模来构建我们自己的文本摘要器。
如果您对本文有任何反馈或任何疑问/疑问,请在下面的评论部分分享,我会回复您。并确保您使用我们在此处构建的模型进行实验,并与社区分享您的结果!
作者:设计稿智能生成代码
链接:https://juejin.im/post/6891937843103727630
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以上是关于易于理解的 python 深度学习摘要算法教程的主要内容,如果未能解决你的问题,请参考以下文章
基于深度学习的中文车牌识别与管理系统(含UI界面,Python代码)