flink平台项目-cnblog
Posted deepJL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink平台项目-cnblog相关的知识,希望对你有一定的参考价值。
flink平台项目
目录
- 架构
- 以前架构
- 现在架构的说明
- CDH&集群规模
- 人员配备
- 开发周期
- 为什么用flinkcdc
- 项目好处
- 千表入湖工具
- flink操作hive
- flink集成hive的步骤
- flinksql 数据源为kafka
- flink读写sql有两种模式
- Temporal Join(时态表join)
- lookup join
- 常见面试题
title: flink平台项目
date: 2023-01-30T11:26:01Z
lastmod: 2023-02-02T19:27:41Z
架构
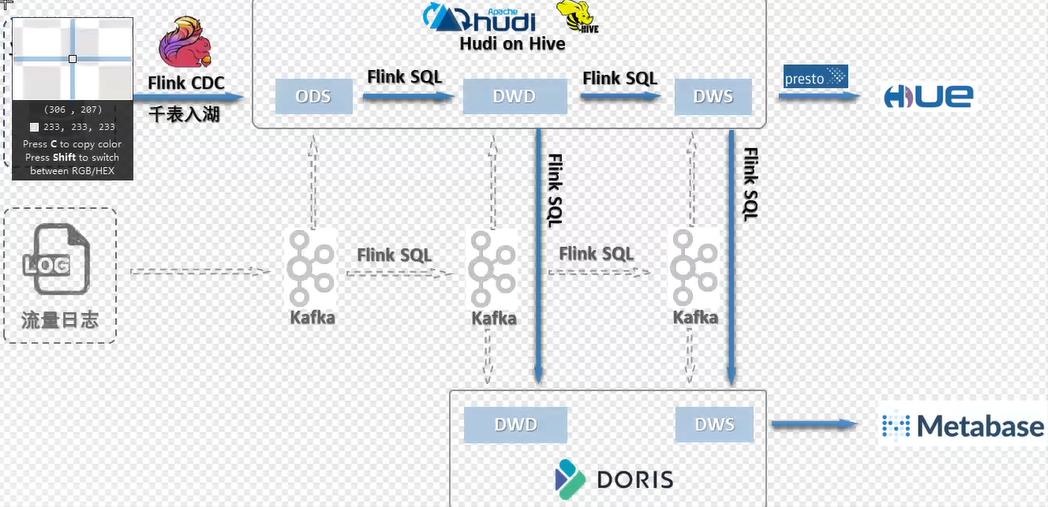

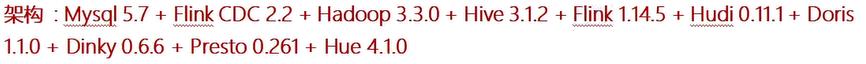
以前架构

问题:
- 需要第三方组件进行持久化,需要增加维护的工作量
- kafka计算的各分层数据存储在kafka集群中,增加持久化的链路
- Debezium 定继单节点 出现单点故障
- hbase存储的时候, kv键值对 , rowkey是主键,使用rowkey查询非常快,但是与非主键数据拉宽,效率较低
比如id 是rowkey,name不是rowkey ,关联name的时候不是rowkey,关联的时候就不快(可以使用二级索引(phenx)加快)
现在架构的说明
dinky 千表入湖
hudi = kafka + hive(操作的是hdfs)
海量数据不丢失
hudi分钟级 准实时. T+1延迟问题得到解决
读取schema不再需要严格定义schema类型
支持数据库表结构的变化
hudi新版本现在支持外部表 0.11.0 ,doris直接外部表读hudi数据,也就是只是hudi中存一份数据
CDH&集群规模
6.3 一台一万
阿里云主机(128G内存 20核cpu 40线程 8THDD 2TSSD) 每年5万

人员配备

开发周期

为什么用flinkcdc
支持全量+增量的功能
项目好处
链路短好维护
- 时效性
- 流批一体
- 复杂的链路
千表入湖工具
阿里云用ververica
flink操作hive

和spark-thrift类似
flink集成hive的步骤
flink 借用了hive 的metastore
- 将jar包上传到flink lib 目录下
- 配置sql-conf , 主要hive catelog ,后续的操作都是基于hive 库和表
-
catelog是什么: 指定读取哪里的元数据
-

-
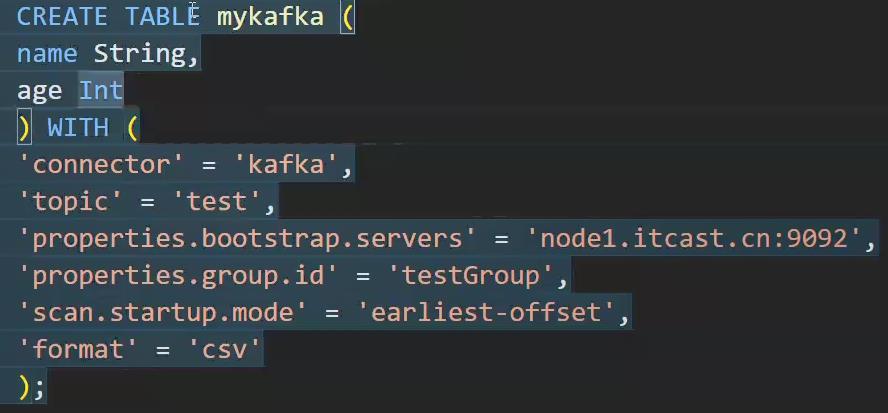
flinksql 数据源为kafka
flink读写sql有两种模式
自带的模式

hive的模式

用处:

Temporal Join(时态表join)
单流驱动
一般指的是两个数据流
反应历史不同变化的维度数据
lookup join
指的是数据流和外部表 mysql redis 进行关联统计, 没有历史变化的信息
常见面试题


一站式Flink&Spark平台解决方案——StreamX

大家好,我是独孤风。今天为大家推荐的是一个完全开源的项目StreamX。该项目的发起者Ben也是我的好朋友。
****什么是StreamX,StreamX 是Flink & Spark极速开发脚手架,流批一体一站式大数据平台。 自2021年3月开源以来,贡献者已累计发展到10多位。
随着Flink&Spark生态的不断完善,越来越多的企业选择这两款组件,或者其中之一作为离线&实时的大数据开发工具,但是在使用他们进行大数据的开发中我们会遇到一些问题,比如:
- 任务运行监控怎么处理?
- 使用Cluster模式还是Nodeport暴露端口访问Web UI?
- 提交任务能否简化打包镜像的流程?
- 如何减少开发压力?
而StreamX就是专为解决这些问题而出现的,其提供了如下的一些功能:
- 开发脚手架
- Kubernetes部署模式支持
- YARN-Application部署模式支持
- 多版本Flink支持(1.12.x, 1.13.x, 1.14.x )
- 一系列开箱即用的Connectors
- 支持项目编译功能(CICD/maven编译)
- 快捷的日常操作(任务启动、停止、savepoint)
- 支持Notebook(在线任务开发)
- 在线参数配置
- 项目配置和依赖版本化管理
- 在线管理依赖(maven pom)和自定义jar
- 自定义 udf、连接器等支持
- Flink SQL WebIDE
有的同学可能会使用Zeppelin比较多,两者是有一定区别的,侧重点不同。未来也会写文做一下两者的对比。
StreamX近期也发布了最新的版本StreamX 1.2.0。
在最新的版本中支持了以下功能:
- 与 Hadoop 解耦, 平台在启动时不在强制依赖 Hadoop 环境
- 较完整的支持了 Kubernetes 部署模式(Native Application/Native Session)
- Kubernetes 部署模式下, 任务的状态追踪监控
- 支持自动 build/push 镜像
- Flink 最新1.14.0 支持, 目前已经支持 Flink 1.12.x / 1.13.x / 1.14.0
- 新增打包机模块,任务打包 fat-jar 更方便
在2021年11月18日,StreamX 也成功的入选了开源中国的2021年度最有价值开源项目。

未来的StreamX也进行着与doris,dolphinscheduler等整合的计划,也会继续增强StreamX在Flink流上的开发部署能力与运行监控能力,努力把StreamX打造成一个功能完善的流数据 DevOps。
StreamX是一个完全由国人发起的开源项目。也欢迎大家联系我们,加入到开源项目中来,为中国开源崛起献上一份自己的力量,未来共同向着成为Apache顶级项目而努力。
Streamx 官网:
Streamx Github:
https://github.com/streamxhub/streamx
Streamx Gitee:
https://gitee.com/streamxhub/streamx
on K8s 部署:
以上是关于flink平台项目-cnblog的主要内容,如果未能解决你的问题,请参考以下文章
Flink从入门到精通100篇(二十二)-微博基于Flink的机器学习实战项目
袋鼠云:基于Flink构建实时计算平台的总体架构和关键技术点