用了这么多年Rust终于搞明白了内存分布!
Posted 轻风博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用了这么多年Rust终于搞明白了内存分布!相关的知识,希望对你有一定的参考价值。

导读
Rust作为一门学习曲线十分陡峭的语言,掌握其核心基础数据结构的内存分布对学习Rust会有很大的帮助,本文由浅入深仔细介绍了Rust的各个数据结构在内存中的分布情况。先决条件 Prerequisite
-
我们本文的机器预设是32位的(主要为了画图可以精简一点),所有和位相关的数据结构均会用上标标记(即这些数据结构占用的是1 machine word)。例如:

-
数据结构基本单位示图:

蓝色的框框代表1个byte,绿色的框框pointer下的(1|2|3|4)代表pointer在32位机器上rust是4个byte,他们整体被框在绿色框框中代表一个pointer。
一、基本类型
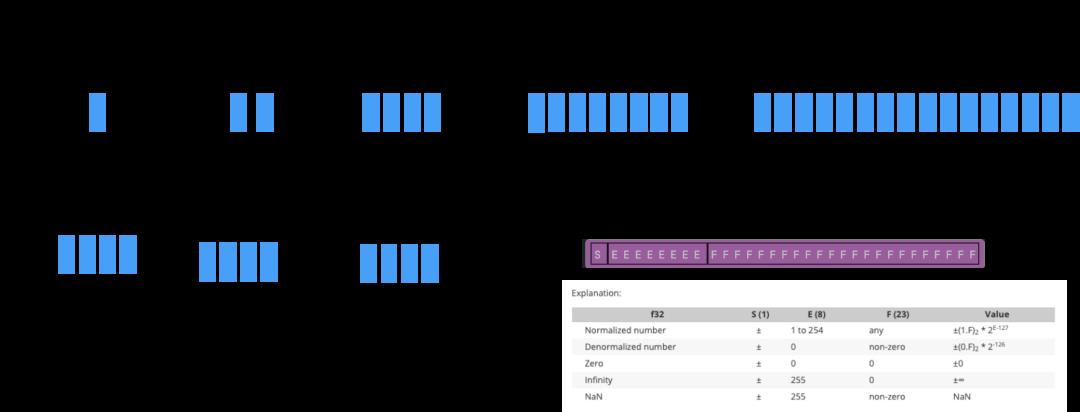
这些数据结构Rust分配的时候都是在栈上的。
1.1 Stack栈 vs Heap堆
我们只提炼一些最基本的区别概要,更多的细节可以看这篇文章[1]有比较好的解释。
栈特点:
-
分配快 -
大小受限
-
分配慢 -
大小不受限
二、元组 Tuple
let a:(char, u8, i32) = (\'a\', 7, 354);
size_of::<(char, u8, i32)>(); // 打印结果 12
align_of::<(char, u8, i32)>(); // 打印结果 4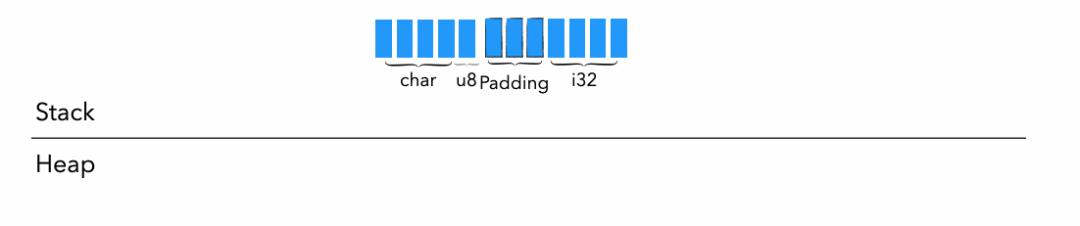
三、引用 Reference
let a: i8 = 6;
let b : &i8 = &a;a 是一个i8,b是一个指向 a 的reference,我们可以看下他俩的内存分布。
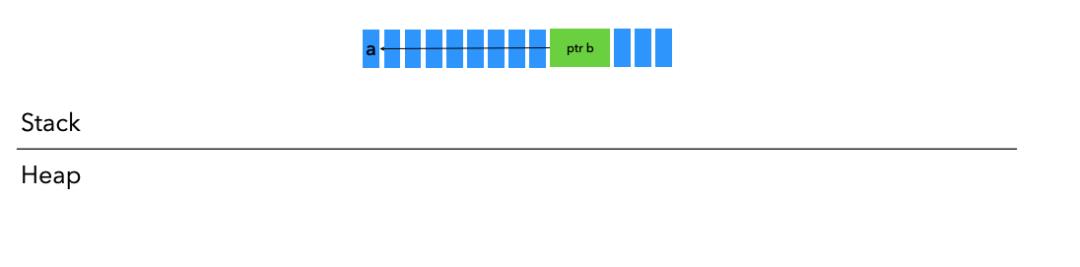
首先,Rust会在栈上分配一个大小为1byte的i8存储a,接着会在内存另外一个空间(不一定和a连续)分配b,b中存储的内存空间会指向a所在的内存空间,同时b的内存占用大小即pointer的大小。
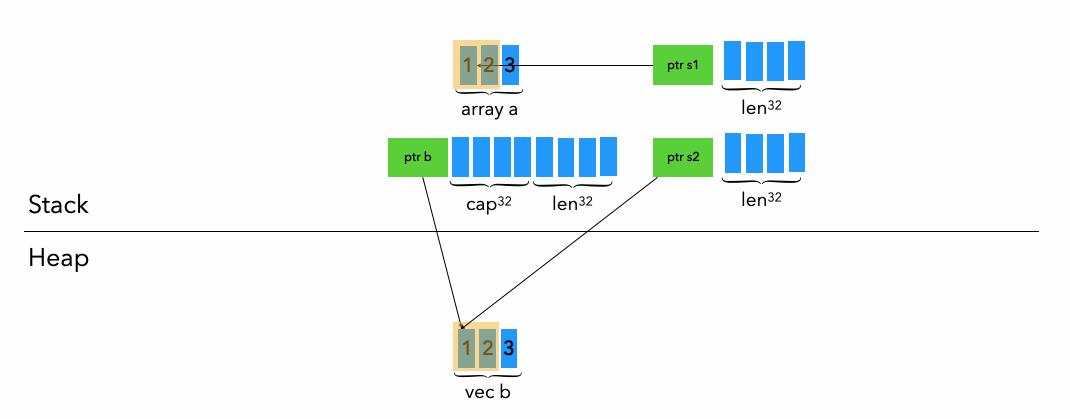
四、Array数租 和 Vector动态数组
接下来我们来看看Rust的数组Array和动态数组Vector的内存分布,以下面的数组和动态数组为例。
let a: [i8; 3] = [1, 2, 3];
let b: Vec<i8> = vec![1, 2, 3];数组Array是固定大小的,所以在创建的时候都指定好了长度;动态数组Vector,由其名字就可以知道他是可以自由伸缩的,那么我们来看看Rust是怎么在内存上存储这两位数据结构的。
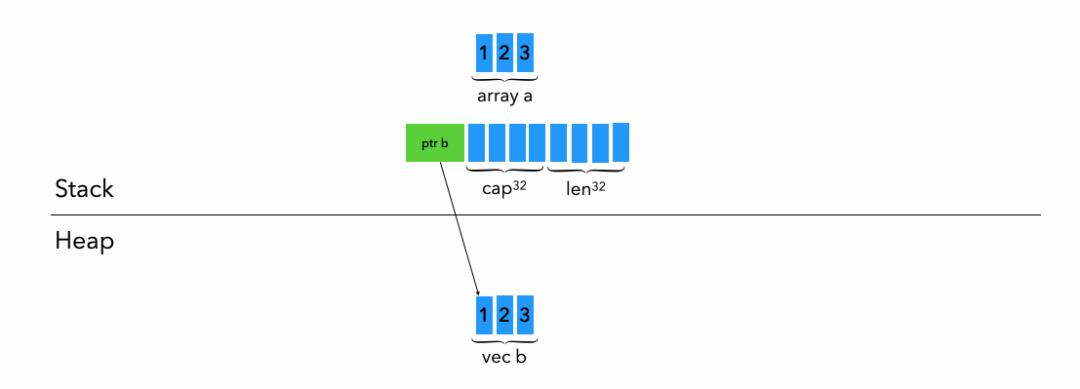
对于Vector b就有点特殊啦,他会由如下三个部分组成:
-
pointer : pointer b会指向vector b在堆上的实际数据(目前是1, 2, 3 共3 * 1 byte),
-
cap(图中上标32代表这个值和机器位数有关,最后复习一次哦): cap代表最多多少个T(本例中T是i8)的内存可以在堆上让这个动态数组使用,默认大小为创建时的T个数,可根据使用需求自动扩容,但每次扩容时会带来reallocate影响到性能。
-
len (1 machine word),代表目前有多少个T(本例中T是i8)的内存真实被该动态数组使用。
以上即可看到数组和动态数组由于在“动态”这个特点上的不同,出现的内存分布差异啦。
4.1 Slice 数组切片
假设我们想获取到上面例子中a和b两个Array和Vector的前两个元素。
let slice_1: [i32] = a[0..2];
let slice_2: [i32] = b[0..2];然而,对于[i32],Rust没法在编译时明确这个变量需要多少内存,因而也没法在栈上分配内存,因而上例中的slice_1和slice_2实际上会编译失败。这样的变量称之为dynamically sized type,后续会讲到string slice和trait object也属于这个范畴。
let slice_1: &[i32] = &a[0..2]
let slice_2: &[i32] = &b[0..2]当reference指向dynamically sized type时,Rust实际会使用到一个胖指针(fat pointer),其中包含:
-
pointer (1 machine word):指向实际被切片的数据。
-
length (1 machine word): 切片长度,即有多少个T(本例中T为i32)。
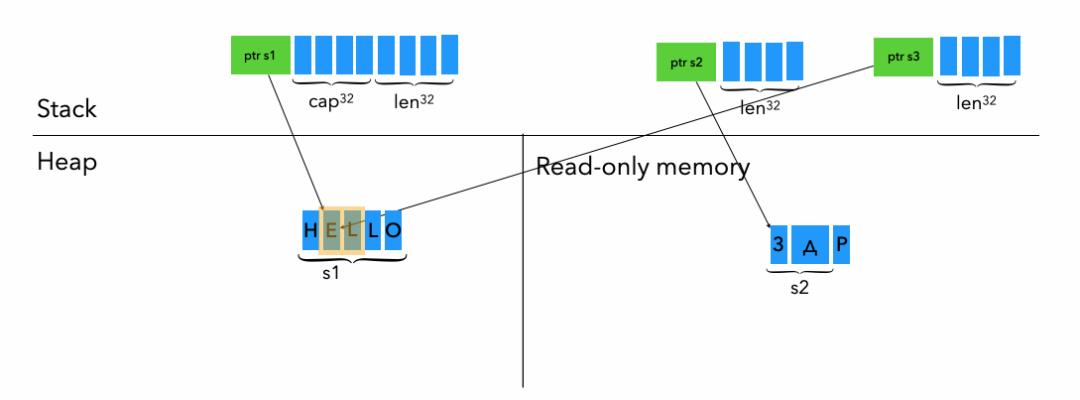
五、String, str, &str
let s1: String = String::from(“HELLO”);
let s2: &str = “ЗдP”; // д -> Russian Language
let s3: &str = &s1[1..3];首先,s1是一个String,String实质上就是Vec的一个包装,其中也是在栈上有一个指针 + cap( 1 machine word ) + len ( 1 machine word ),指针指向了该String实际在堆上的值。String是保证UTF-8兼容的。
-
pointer (1 machine word):指向实际被切片的字符串。
-
length (1 machine word): 切片长度。
六、Struct
6.1 unit-like Struct
struct Data
6.2 Struct with named fields && tuple-like struct
struct Data
nums: Vec<usize>,
dimension: (usize, usize),

七、Enum
enum HTTPStatus
Ok,
NotFound,
对于C-style enum,在内存中,rust会根据该enum中最大的数来选择内存占用最小的int来存储,此例中没有指定就会默认Ok为0,NotFound为1,Rust选择占用1 byte的i8来存储enum。
enum HttpStatus
Ok = 200,
NotFound = 404,
Empty,
Number(i32),
Array(Vec<i32>),
7.1 Option
pub enum Option<T>
None,
Some(T),


八、Box
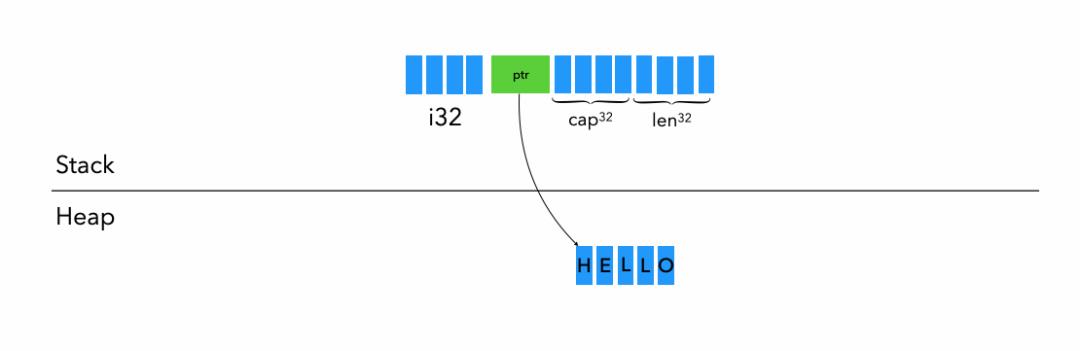
(图中省去了padding)
let t: (i32, String) = (5, “Hello”.to_string);
let mut b = Box::new(t);
可以看到,原本在栈上的内容都被转移到Heap上,减少了我们在栈上的内存空间消耗。
本文来自博客园,作者:古道轻风,转载请注明原文链接:https://www.cnblogs.com/88223100/p/Rust-memory-distribution.html
用了这么多年CSS,终于知道是怎么工作的了
我们每天都在与CSS打交道,那么CSS的原理是什么呢?
一、浏览器渲染
开篇,我们还是不厌其烦的回顾一下浏览器的渲染过程,先上图:
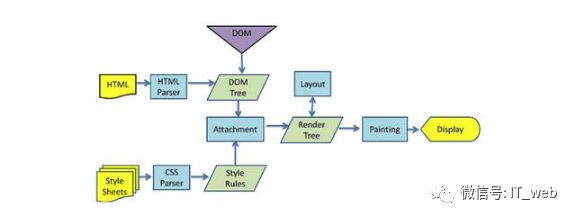
正如上图所展示的,我们浏览器渲染过程分为了两条主线:
以上是关于用了这么多年Rust终于搞明白了内存分布!的主要内容,如果未能解决你的问题,请参考以下文章