java在线运行工具,终于搞明白了
Posted 阿里Java后端
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java在线运行工具,终于搞明白了相关的知识,希望对你有一定的参考价值。
正文
ZooKeeper 很流行,有个基本的疑问:
- ZooKeeper 是用来做什么的?
- 之前没有ZK,为什么会诞生 ZK?
OK,解答一下上面的疑问:(下面是凭直觉说的)
- ZooKeeper 是用于简化分布式应用开发的,对开发者屏蔽一些分布式应用开发过程中的底层细节
- ZooKeeper 对外暴露简单的 API,用于支持分布式应用开发
- ZooKeeper 在提供上述功能的同时,其还是一个 高性能、高可用、高可靠的分布式集群
上面说这么多,总结一下,ZK 能解决分布式应用开发的问题,ZK 能很好的解决问题。到这一步,疑问就更多了:
- 分布式应用开发,有哪些常见问题?ZK 是如何屏蔽这些底层细节的?
- ZooKeeper 对外暴露了那些 API?这些 API 如何支持分布式应用开发的?这些 API 还能简化吗?API 的语义性怎么样?
- ZooKeeper 自身是一个高性能、高可用、高可靠的分布式集群,那有个简单的问题:
- 高性能是指什么?ZooKeeper 为了达到高性能,做了哪些工作?
- 高可用同上
- 高可靠同上
Note:本篇 wiki 就是为了解决上述第一个疑问的。(其他疑问会在其他 blog 中逐步解答)
为什么有 ZooKeeper
一个应用程序,涉及多个进程协作时,业务逻辑代码中混杂有大量复杂的进程协作逻辑。
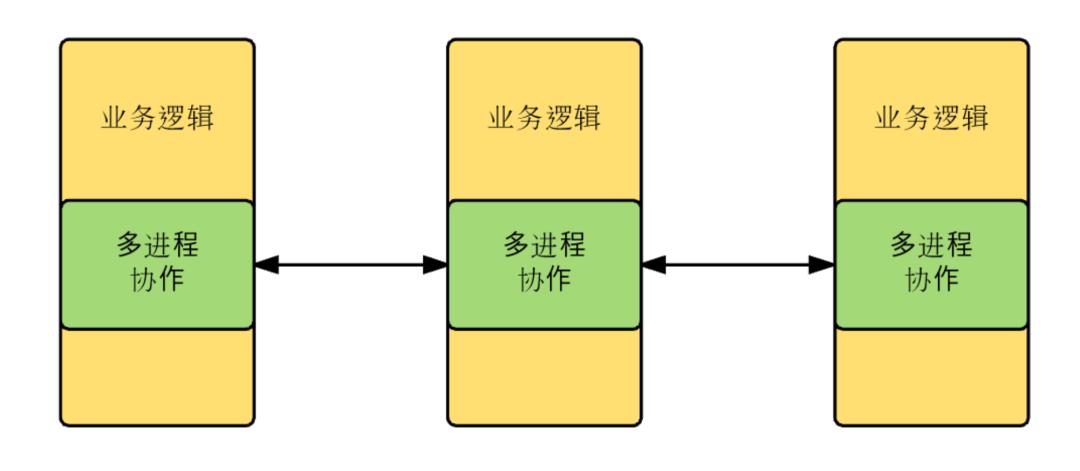
上述多进程协作逻辑,有 2 个特点:
- 处理复杂
- 处理逻辑可重用
因此,考虑将多进程协作的共性问题拎出,作为基础设施,让 RD 更加专注业务逻辑开发,即:
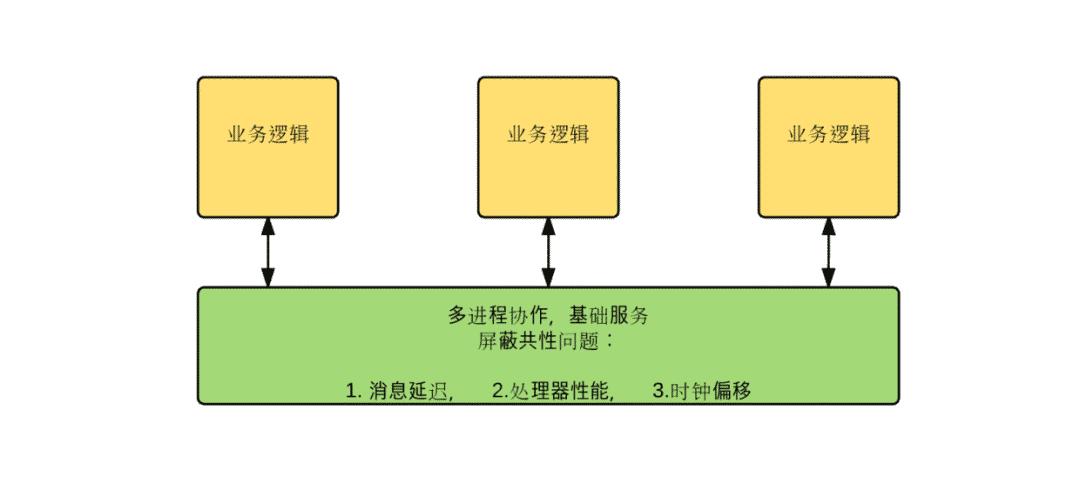
ZooKeeper 就是上述多进程协作基础服务的一种。
ZooKeeper 的特点
ZooKeeper 有几个简单特点:
- ZooKeeper 的 API:从 文件系统 API 得到的启发,提供简单的 API
- ZooKeeper 运行在专用服务器上,跟业务逻辑分离,保证了高容错性和可扩展性
ZooKeeper 是存储设施,但特别注意
- ZK上存储的数据聚焦为:
协作数据(元数据),而不是应用数据,应用数据有自己的存储方案,例如 HDFS 等 - ZK 本质上,可以看作一种
特殊的 FS
特别说明:
应用数据和元数据,由于使用场景不同,对一致性和持久性的要求有差异, 因此,架构设计、数据治理过程中,应将 2 类数据独立看待、独立存储。
ZooKeeper 的使命
ZK 要解决的核心问题:
ZK 目标:简化分布式应用开发中,多进程协作问题。为分布式应用,提供高效、可靠的分布式协调服务(基础服务),例如:
- 统一的命名服务
- 分布式锁
- 进程崩溃检测
- Leader 选举
- 配置管理:配置变更时,及时下发到各个 Client。
一个简单的问题:多进程的协作是什么?尼玛呀,有完没完,啥问题你都有,面对这个掉咋天的脑壳,还是回答一下。
多进程协作,整体分为 2 类:
- 协作:多进程需要一同处理某些事情,一些进程采取行动是的其他进程能够正常工作,例如:主从结构,M 向 S 分配任务,S 才会执行,否则 S 就保持空闲状态
- 竞争:两个进程不能同时工作,一个进程必须等待另个进程执行完毕,例如:主从结构,M 节点失效后,很多 S 都想成为 M,这时,就需要互斥锁,只有第一个获得锁的 S 成为 M
特别说明:
- 不跨网络协作:多进程,可以在同一台物理主机上,同步原语很方便(比如?管道、共享内存、消息队列、信号量)
- 跨网络协作:多进程,分布在不同的物理主机上,ZK 关注这一类
跨网络多进程协作,进程通信,基本思路有 2 个:
- 消息机制:通过网络,直接信息交换,多消息传递算法,实现同步原语
- 共享存储:利用外部共享存储,实现多进程协作,要求
共享存储提供有序访问,ZK 采用这种方式
真实系统中,跨网络通信,有几个共性问题:
- 消息延迟:由于网络原因,后发送先到达
- 处理器性能:由于系统调度原因,消息到达后,延迟处理
- 时钟偏移:不同物理主机,时钟发生偏移
ZK 精心设计用于屏蔽上述 3 个共性问题,使得这些问题在应用服务层面完全透明化。
ZooKeeper 特性
ZooKeeper 解决的本质问题
分布式系统的一致性问题:
- 消息传递:延迟性,先发送的消息,不一定先到达;
- 消息传递:丢失性,发送的消息,可能丢失;
- 节点崩溃:分布式系统内,任何一个节点都可能崩溃;
在这种情况下,如何保证数据的一致性?
- 提案投票:基于投票策略,2PC
- 选举投票:基于投票策略,投出
优先级最高的节点(包含最新数据的节点)
Paxos 目标:解决分布式一致性问题,提高分布式系统容错性的一致性算法。
Paxos 本质:基于消息传递的高度容错的一致性算法
ZooKeeper 定位
ZooKeeper 是:
- 分布式协调服务
- 高效、可靠
- 方便应用程序,聚焦
业务逻辑开发,而不需要过多关注分布式进程间协作细节
ZooKeeper 不直接暴露原语,而是,暴露一部分调用方法组成的 API,类似文件系统的 API,支持应用程序实现自己的原语。
ZooKeeper 特性
ZooKeeper 可以保证如下分布式一致性特性:
- 顺序一致性:同一个 Client 发起的事务请求,严格按照发起顺序执行
- 原子性:事务请求,要么应用到所有节点,要么一个节点都没有应用
- 单一视图:Client 无论连接到哪个节点,看到的服务端数据都是一致的(Note:不准确,其实是最终一致性)
- 可靠性:事务一旦执行成功,状态永久保留
- 实时性:事务一旦执行成功,Client 并不能立即看到最新数据,但 ZooKeeper 保证最终一致性
ZooKeeper 设计目标
ZooKeeper 致力于提供高性能、高可用、顺序一致性的分布式协调服务,保证数据最终一致性。
目标一:高性能(简单的数据模型)
- 采用
树形结构组织数据节点; - 全量数据节点,都存储在内存中;
- Follower 和 Observer 直接处理非事务请求;
目标二:高可用(构建集群)
- 半数以上机器存活,服务就能正常运行
- 自动进行 Leader 选举
目标三:顺序一致性(事务操作的顺序)
- 每个事务请求,都会转发给 Leader 处理
- 每个事务,会分配全局唯一的递增id(zxid,64位:epoch + 自增 id)
目标四:最终一致性
- 通过提议投票方式,保证事务提交的可靠性
- 提议投票方式,只能保证 Client 收到事务提交成功后,半数以上节点能够看到最新数据
ZooKeeper 出现之前
ZK 出现之前,分布式系统常用两种方式,实现多进程协作:
- 分布式锁管理器
- 分布式数据库
ZK 更专注于进程协作,而不提供任何锁接口和通用的存储数据接口。(疑问:ZK 也可以提供啊,我们不使用就行了)
应用服务器,常见的 2 种需求:
- Master-Slave Leader 选举:要求提供Master节点选举功能
- 进程响应跟踪 崩溃检测:要求提供进程存活状态的跟踪
- 分布式锁:互斥排它锁
ZK 为上述 2 种策略提供了基础 API。
ZooKeeper 不适用的场景:
- 海量数据存储:ZK 本质是
特殊的 FS,但 ZK 用于存储元数据,需要单独存储应用数据
感受:
其实我投简历的时候,都不太敢投递阿里。因为在阿里一面前已经过了字节的三次面试,投阿里的简历一直没被捞,所以以为简历就挂了。
特别感谢一面的面试官捞了我,给了我机会,同时也认可我的努力和态度。对比我的面经和其他大佬的面经,自己真的是运气好。别人8成实力,我可能8成运气。所以对我而言,我要继续加倍努力,弥补自己技术上的不足,以及与科班大佬们基础上的差距。希望自己能继续保持学习的热情,继续努力走下去。
也祝愿各位同学,都能找到自己心动的offer。
分享我在这次面试前所做的准备(刷题复习资料以及一些大佬们的学习笔记和学习路线),都已经整理成了电子文档,需要的朋友可以【点赞+关注】戳这里即可免费获取
基础上的差距。希望自己能继续保持学习的热情,继续努力走下去。
也祝愿各位同学,都能找到自己心动的offer。
分享我在这次面试前所做的准备(刷题复习资料以及一些大佬们的学习笔记和学习路线),都已经整理成了电子文档,需要的朋友可以【点赞+关注】戳这里即可免费获取

以上是关于java在线运行工具,终于搞明白了的主要内容,如果未能解决你的问题,请参考以下文章
用手画了11张图终于搞明白了Git工作流,我怀疑你用的是假 Git
用手画了11张图终于搞明白了Git工作流,我怀疑你用的是假 Git