22 URL到网卡:网络数据流动
Posted xuan01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了22 URL到网卡:网络数据流动相关的知识,希望对你有一定的参考价值。
输入URL,从一个请求到响应都发生了什么事?
常规网络交互过程:1、从客户端发起网络请求,用户态的应用程序会生成HTTP请求报文,并通过DNS协议查找到对应的远端 IP地址;2、在套接字生成以后进入内核态,游览器会委托操作系统内核协议栈中的上半部分,即TCP/UDP协议发起连接请求;3、然后由协议栈下半部分的ip协议进行封装,使数据包具有远程定位能力;4、经过MAC层处理,找到接收方的目标MAC地址;5、最终数据包在经过网卡转化成电信号经过交换机、路由器发送到服务端,服务端经过处理拿到数据,再通过各种网络协议把数据响应给客户端;6、客户端拿到数据;7、客户端与服务端之间反复交换数据,客户端的页面就会发生变换;
网络分层和网络协议:
通过网络分层简化问题难度;网络数据传输过程中,不同的设备之间的传输数据的格式,需要定义一个数据标准,因此有了网络协议;
发起请求阶段(应用层):
应用层是工作在操作系统的用户态;
用户输入:在游览器中输入URL:
输入时,游览器会根据我们的输入内容,先匹配对应的URL以及关键词,给出输入建议,同时检查URL的合法性,并且在URL前后补全URL;每个网络栏的地址都符合 通用URI 的语法;
URI = scheme:[//authority]path[?query][#fragment]
URI = 方案:[//授权]路径[?查询][#片段ID]
游览器会从URL中提取出网络的地址,也叫主机名;可以为域名或IP地址;解析之后,生成HTTP请求;
网络请求前:查看游览器缓存:
HTTP报文生成之后,会先检查本地缓存,若访问过当前的URL,会先进入缓存查询;缓存有:路由器缓存、DNS 缓存、浏览器缓存、Service Worker、Memory Cache、Disk Cache、Push Cache、系统缓存等;若游览器缓存没有命中缓存,游览器会做一个系统调用获得系统缓存中的记录,通过域名获取IP地址,返回hostent 结构;
若没有访问过,就会跳过缓存这一步;
域名解析:DNS
游览器会委托操作系统将HTTP报文发送到对应的服务端;这之前需要查找到服务端的IP地址;为方便记忆,将IP映射为域名;
DNS服务器是一个分布式数据库:维护IP和域名的映射关系;
在域名中,层级关系是从左到右、从低到高排列的树形结构,最高一级的根节点为root节点;即根域名服务器;因为所有的域名的顶级域名都一样,因此省略;完整的 应该是 cosmos.com. ,后面的. 相当于.root ;
客户端因此只要请求到一个DNS服务器,就可以一层层递归和迭代查找所有的DNS服务器;
DNS域名解析的过程:DNS解析 > 浏览器DNS缓存 > hosts文件 > 本地DNS服务器 > ISP DNS服务器;
操作系统协议栈(传输层和网络层):
TCP/IP 协议栈最广泛;协议栈的上半部分负责和应用层通过套接字(Socket)进行交互;它可以是TCP协议或UDP协议;
应用层会委托协议栈的上半部分完成收发数据的工作;下半部分负责把数据发送到指定方的IP协议,由IP协议连接下层的网卡驱动;
可靠性传输:建立TCP连接:
游览器通过DNS解析拿到cosmos的IP地址后,取出URL的端口,HTTP默认为80,HTTPS 默认为443;随即游览器委托协议栈向对应的IP地址发器TCP连接请求;
建立TCP三次握手操作:


发送的是TCP分组;也是一次网络通信;TCP包头用于向下层表明这是一个tcp数据包;首先是源端口号和目标端口号,接着是一串有序数字,保证TCP报文有序被接受,解决网络包乱序问题;之后是确认号,防止数据包丢失;紧接着是一些状态位,维护双方连接的状态;后面还有一个窗口,用于流量控制;
TCP层封装好数据包,向下层IP层发送;
目的地定位:IP层:
IP协议是TCP/IP协议栈的核心; 网络数据包进入网络层后,IP层协议函数要对网络数据包进行:数据包的校验和检验;防火墙对数据包过滤;IP选项处理;数据分片和重组;接收、发送和前送;
IP层被设计成 IP寻址、路由和分包组包;IP地址并不是以主机数目进行配置的,而是根据网卡数来进行;把IP地址及相关信息组装为一个IP头,把它放在网络数据的前面形成IP包;最后将IP包发送给ip层下一层组件MAC层;

点对点传输:MAC(链路层)
网卡mac地址就是计算机网卡的物理地址;固化到网卡中,唯一且无重复;
由IP包加上mac头;mac头包括发送方的mac头,和接收方的mac头;用于两个物理地址点对点传输;此外还有一个头部字段为协议类型,有IP和ARP两种;

发送方的mac地址只需要读取当前设备网卡的mac地址就可以获取;而接收方的mac头则需要通过ARP协议在网络中携带IP地址,在一个网络中发送广播信息,这样就能获取网络的IP地址对应的mac地址;然后给IP头加上mac头就可以成为mac数据包;
电信号的出口:网卡(物理层)
将数据包转化为电信号;mac数据包交给网卡驱动程序,而网卡驱动程序会将mac数据包写入网卡的缓冲区(网卡上的内存);网卡会在mac数据包的起止位置加入起止帧和校验序列;最后将加入起止帧和校验序列的mac数据包转化为电信号,发送出去;
客户端服务端的持续数据交换(应用层):
数据通过网卡离开了计算机,进入到局域网,通过局域网中的设备,集线器、交换机和路由器等,数据会进入到互联网,最终到达目标服务器。
服务器就会先取下数据包的 MAC 头部,查看是否匹配自己 MAC 地址。然后继续取下数据包的 IP 头,数据包中的目标 IP 地址和自己的 IP 地址匹配,再根据 IP 头中协议项,知道自己上层是 TCP 协议。之后,还要继续取下数据包 TCP 的头。完成一系列的顺序校验和状态变更后,TCP 头部里面还有端口号,此时我们的 HTTP 的 server 正在监听这个端口号,就把数据包再发给对应的 HTTP 进程。HTTP 进程从服务器中拿到对应的资源(HTML 文件),再交给操作系统对数据进行处理。然后再重复上面的过程,层层携带 TCP、IP、MAC 头部。接下来数据从网卡出去,到达客户端,再重复刚才的过程拿到相应数据。客户端拿到对应的 HTML 资源,浏览器就可以开始解析渲染了,这步操作完成后,用户最终就能通过浏览器看到相应的页面;

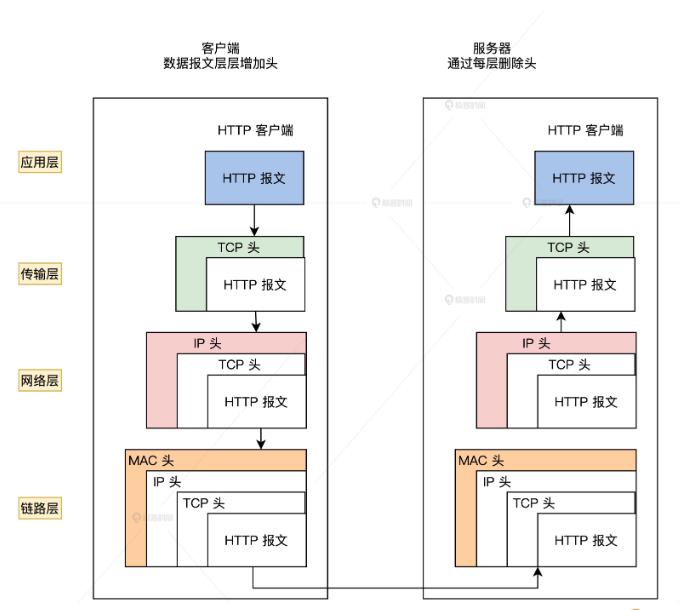
此时,客户端与服务端之间通过tcp协议维护了一个连接状态;若需要关闭,则进行四次挥手;
网络数据包收发流程:e1000网卡和DMA
一、硬件布局
每个网卡(MAC)都有自己的专用DMA Engine,如上图的 TSEC 和 e1000 网卡intel82546。
上图中的红色线就是以太网数据流,DMA与DDR打交道需要其他模块的协助,如TSEC,PCI controller
以太网数据在 TSEC<-->DDR PCI_Controller<-->DDR 之间的流动,CPU的core是不需要介入的
只有在数据流动结束时(接收完、发送完),DMA Engine才会以外部中断的方式告诉CPU的core
二、DMA Engine
上面是DMA Engine的框图,以接收为例:
1.在System memory中为DMA开辟一端连续空间,用来BD数组 (一致性dma内存)
BD是给DMA Engine使用的,所以不同的设备,BD结构不同,但是大致都有状态、长度、指针3个成员。
2.初始化BD数组,status为E,length为0
在System memory中再开辟一块一块的内存,可以不连续,用来存放以太网包
将这些内存块的总线地址赋给buf(dma映射)
3.当MAC接收以太网数据流,放在了Rx FIFO中
4.当一个以太网包接收完全后,DMA engine依次做以下事情
fetch bd:开始一个个的遍历BD数组,直到当前BD状态为Empty为止
update bd:更新BD状态为Ready
move data:把数据从Rx FIFO中搬移到System Memory中dma映射的部分
generate interrupt:数据搬移完了,产生外部中断给cpu core
5.cpu core处理外部中断,此时以太网数据已经在System memory中dma映射的部分了
解除dma映射,更新bd状态为Empty
再开辟一端内存,将这块内存的总线地址赋给bd的指针字段
三、内核中DMA相关API
void *dma_alloc_cohrent(struct device *dev, size_t size, dma_addr_t *dma_handle, int flag);
功能:分配一致性dma内存,返回这块内存的虚拟地址EA, 这块内存的物理地址保存在 dma_handle
dev: NULL也行
size: 分配空间的大小
dma_handle: 用来保存内存的总线地址(物理地址)
注意:一致性DMA映射,BD所占内存就是靠dma_alloc_cohrent来分配的。
dma_addr_t *dma_map_single(struct device *dev, void *buffer, size_t size, enum dma_data_direction);
功能:将一块连续的内存 buffer 映射为DMA内存来使用。映射后,CPU不能再操作这块 buffer
返回:这块buffer的总线地址(物理地址)
dev: NULL也行
buffer: 一块连续内存的虚拟地址EA
size: 连续内存的大小
dma_data_direction: dma数据流的方向
注意:流式DMA映射,以太网包所占内存先通过kmalloc来分配,然后通过dma_map_single来映射给bd的
四、e1000驱动中的DMA
网卡驱动中使用DMA的套路差不多都一样,以e1000驱动为例讲一下(TSEC驱动的dma见这里)
4.1 加载e1000网卡驱动
e1000_probe(){ //主要是初始化钩子函数
netdev = alloc_etherdev(sizeof(struct e1000_adapter));
netdev->open = &e1000_open; //重要
netdev->stop = &e1000_close;
netdev->hard_start_xmit = &e1000_xmit_frame;
netdev->get_stats = &e1000_get_stats;
netdev->set_multicast_list = &e1000_set_multi;
netdev->set_mac_address = &e1000_set_mac;
netdev->change_mtu = &e1000_change_mtu;
netdev->do_ioctl = &e1000_ioctl;
e1000_set_ethtool_ops(netdev);
netdev->tx_timeout = &e1000_tx_timeout;
netdev->watchdog_timeo = 5 * HZ;
#ifdef CONFIG_E1000_NAPI
netif_napi_add(netdev, &adapter->napi, e1000_clean, 64); //重要
#endif
}
4.1 启动e1000网卡
e1000_open() //当用户敲ifconfig up命令时,最终调用网卡驱动的open函数
-->e1000_setup_all_rx_resources(adapter)
-->e1000_setup_rx_resources(adapter, &adapter->rx_ring[i])
//给rx bd分配一致性dma内存
rxdr->desc = pci_alloc_consistent(pdev, rxdr->size, &rxdr->dma);
-->e1000_configure(adapter)
-->e1000_configure_rx(adapter)
adapter->clean_rx = e1000_clean_rx_irq;
adapter->alloc_rx_buf = e1000_alloc_rx_buffers;
-->调用 adapter->alloc_rx_buf钩子函数,即 e1000_alloc_rx_buffers
--> skb = netdev_alloc_skb(netdev, bufsz); //调用kmalloc新建一个skb
buffer_info->dma = pci_map_single(pdev,
skb->data,
adapter->rx_buffer_len,
PCI_DMA_FROMDEVICE); //给skb->data建立DMA映射
rx_desc->buffer_addr = cpu_to_le64(buffer_info->dma);//初始化bd的buf指针
-->e1000_request_irq(adapter);
//挂rx 中断ISR函数为 e1000_intr()
最终bd数据结构应该是下面这个样子
4.2 e1000的中断
注意:e1000产生rx中断时,以太网数据包已经在系统内存中,即在skb->data里面
下面的中断处理过程就简略了,详细的看这里
do_IRQ()
{
中断上半部
调用e1000网卡的rx中断函数 e1000_intr()
触发软中断 (使用NAPI的话)
中断下半部
依次调用软中断的所有handler
在net_rx_action中最终调用e1000的napi_struct.poll()钩子函数,即e1000_clean
e1000_clean()最终调用 e1000_clean_rx_irq()
}
e1000_clean_rx_irq()
{
rx_desc = E1000_RX_DESC(*rx_ring, i); //获取rx bd
status = rx_desc->status;
skb = buffer_info->skb;
buffer_info->skb = NULL;
pci_unmap_single(pdev, //解除skb->data的DMA映射
buffer_info->dma,
buffer_info->length,
PCI_DMA_FROMDEVICE);
length = le16_to_cpu(rx_desc->length);
length -= 4; //以太网包的FCS校验就不要了
skb_put(skb, length);
skb->protocol = eth_type_trans(skb, netdev);
netif_receive_skb(skb); //skb进入协议栈
}
转载自http://blog.chinaunix.net/uid-24148050-id-1667017.html
以上是关于22 URL到网卡:网络数据流动的主要内容,如果未能解决你的问题,请参考以下文章