23 网络数据在内核中流转
Posted xuan01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了23 网络数据在内核中流转相关的知识,希望对你有一定的参考价值。
一次具体的网络收发过程:
发送过程:
应用程序准备好数据,调用用户态下的库函数,调用系统API接口函数,进入到内核态;内核态对应的系统服务函数会复制应用程序的数据到内核的内存空间中,然后将数据移交给网络协议栈,在网络协议栈中将数据层层打包;最后,包装好的数据会交给网卡驱动,网卡驱动程序负责将打包好的数据写入网卡并让其发送出去;
接收过程:
网卡接收到数据,通过DMA方式复制到指定的内存,接着发送中断,以便通知网卡驱动,由网卡驱动处理中断复制数据;然后网络协议收到网卡驱动传过来的数据,层层解包,获取真正的数据;最后将这个数据发送到用户态监听的应用进程;

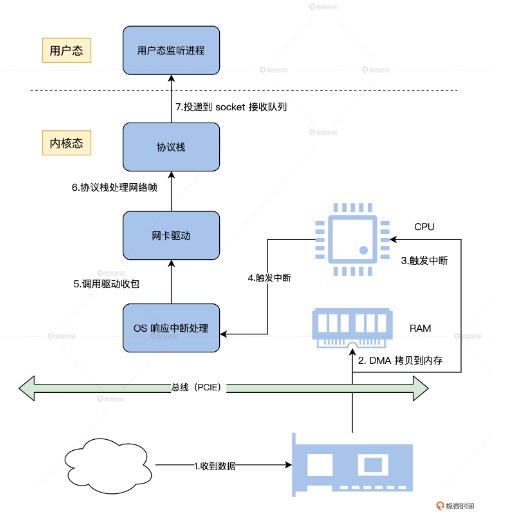
LwIP架构:light weight IP
TCP/IP协议的轻量级开源项目;C语言实现的,一共有两套接口层,向上提供给用户,向下提供给系统;保持TCP协议主要功能 的基础上减少对 RAM的占用;同时,还支持ipv6 标准实现;
LwIP结构分为四层:OS层,API层,核心层,硬件驱动层;
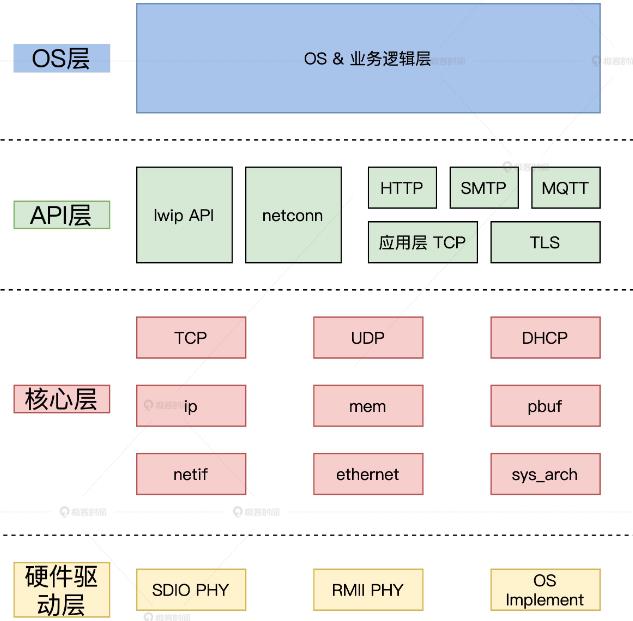
第一层:通过netconn 或 lwip_api 使用 lwip 的各种功能函数;
第二层:api层是netconn的功能代码所在的层;
第三层:lwip的核心层存放了TCP/IP协议的核心代码;实现TCP、UDP功能,还实现了 DNS、ICMP、IGMP等协议;同时也实现 了内存管理、网络接口功能;sys_arch模块便于移植到不同的OS上;
第四层:硬件驱动层提供PHY芯片驱动,用来匹配 lwip 的使用;lwip会调用该层的代码将组装好的 数据包发送到网络;同时从网络接收数据包并进行分析,实现通信功能;
lwip的三套应用程序编程接口:
RAW/Callback API、顺序 API 和 Socket API;
lwip 执行流程:
数据发送:
把lwip 作为 cosmos 的一个内核组件来工作;由 lwip 接收来自内核上层发来的数据,内核上层先调用lwip的netconn层的接口函数 netconn_write 函数,数据正式流进lwip 组件层;
接着,netconn层调用 lwip 组件的tcp层的接口函数tcp_write ,在tcp层对数据首次进行打包,然后tcp层将打包好的数据通过io_output 函数,向下传递给lwip组件的IP层,进行打包;
最后,IP层将打包的数据发送给网卡驱动接口层netif ,调用实际的网卡驱动程序,将数据发送出去;


数据接收:
应用程序首先调用 lwip 的netconn 层的 netconn_recv接口,然后由 netconn 层调用sys_arch_mbox_fetch 函数,进入监听等待相关的mbox;
接着,数据会进入网卡,驱动程序相关的函数负责把它复制到内存;再然后是调用ethernet_input 函数,进入ethernet 层;调用ip4_input 函数,数据在lwip组件ip层对数据解包,进行相应的处理,还会调用tcp_input 函数,进入lwip 组件的tcp 层对数据解包;
最后,调用 sys_mbox_trypost 函数把数据放入特定的 mbox,等待监听的应用程序得到数据;
协议栈移植:
有两种:无操作系统模式、有操作系统模式(sys_arch 层的接口函数);
带操作系统的移植就是无操作系统的基础上添加操作系统的模拟层;
操作系统主要基于操作系统的 IPC机制(Inter-process Communication,进程间通信),对网络连接进行了抽象,保证内核与应用层API的通讯,好处是lwip 内核线程可以只负责数据包的TCP/IP的封装和拆封,不用进行数据的应用层处理,极大提高系统对网络数据包的处理效率;
有操作系统的模式:
完整的移植网络栈,需要移植30多个函数实现;这些变量和函数主要面向信号量,互斥体和邮箱,包括创建删除、释放和获取等操作;
在lwip中,用户代码通过邮箱与协议栈内部交互,邮箱本质上是指向数据的指针;API 将指针传递给内核,内核通过这个指针访问数据,然后进行处理;内核也是通过邮箱将数据传递给用户代码的;

linux 内核网络数据包接收流程
转:https://segmentfault.com/a/1190000008836467
本文将介绍在Linux系统中,数据包是如何一步一步从网卡传到进程手中的。
如果英文没有问题,强烈建议阅读后面参考里的两篇文章,里面介绍的更详细。
本文只讨论以太网的物理网卡,不涉及虚拟设备,并且以一个UDP包的接收过程作为示例.
本示例里列出的函数调用关系来自于kernel 3.13.0,如果你的内核不是这个版本,函数名称和相关路径可能不一样,但背后的原理应该是一样的(或者有细微差别)
网卡到内存
网卡需要有驱动才能工作,驱动是加载到内核中的模块,负责衔接网卡和内核的网络模块,驱动在加载的时候将自己注册进网络模块,当相应的网卡收到数据包时,网络模块会调用相应的驱动程序处理数据。
下图展示了数据包(packet)如何进入内存,并被内核的网络模块开始处理:
+-----+
| | Memroy
+--------+ 1 | | 2 DMA +--------+--------+--------+--------+
| Packet |-------->| NIC |------------>| Packet | Packet | Packet | ...... |
+--------+ | | +--------+--------+--------+--------+
| |<--------+
+-----+ |
| +---------------+
| |
3 | Raise IRQ | Disable IRQ
| 5 |
| |
↓ |
+-----+ +------------+
| | Run IRQ handler | |
| CPU |------------------>| NIC Driver |
| | 4 | |
+-----+ +------------+
|
6 | Raise soft IRQ
|
↓
-
1: 数据包从外面的网络进入物理网卡。如果目的地址不是该网卡,且该网卡没有开启混杂模式,该包会被网卡丢弃。
-
2: 网卡将数据包通过DMA的方式写入到指定的内存地址,该地址由网卡驱动分配并初始化。注: 老的网卡可能不支持DMA,不过新的网卡一般都支持。
-
3: 网卡通过硬件中断(IRQ)通知CPU,告诉它有数据来了
-
4: CPU根据中断表,调用已经注册的中断函数,这个中断函数会调到驱动程序(NIC Driver)中相应的函数
-
5: 驱动先禁用网卡的中断,表示驱动程序已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知CPU了,这样可以提高效率,避免CPU不停的被中断。
-
6: 启动软中断。这步结束后,硬件中断处理函数就结束返回了。由于硬中断处理程序执行的过程中不能被中断,所以如果它执行时间过长,会导致CPU没法响应其它硬件的中断,于是内核引入软中断,这样可以将硬中断处理函数中耗时的部分移到软中断处理函数里面来慢慢处理。
内核的网络模块
软中断会触发内核网络模块中的软中断处理函数,后续流程如下
+-----+
17 | |
+----------->| NIC |
| | |
|Enable IRQ +-----+
|
|
+------------+ Memroy
| | Read +--------+--------+--------+--------+
+--------------->| NIC Driver |<--------------------- | Packet | Packet | Packet | ...... |
| | | 9 +--------+--------+--------+--------+
| +------------+
| | | skb
Poll | 8 Raise softIRQ | 6 +-----------------+
| | 10 |
| ↓ ↓
+---------------+ Call +-----------+ +------------------+ +--------------------+ 12 +---------------------+
| net_rx_action |<-------| ksoftirqd | | napi_gro_receive |------->| enqueue_to_backlog |----->| CPU input_pkt_queue |
+---------------+ 7 +-----------+ +------------------+ 11 +--------------------+ +---------------------+
| | 13
14 | + - - - - - - - - - - - - - - - - - - - - - - +
↓ ↓
+--------------------------+ 15 +------------------------+
| __netif_receive_skb_core |----------->| packet taps(AF_PACKET) |
+--------------------------+ +------------------------+
|
| 16
↓
+-----------------+
| protocol layers |
+-----------------+
-
7: 内核中的ksoftirqd进程专门负责软中断的处理,当它收到软中断后,就会调用相应软中断所对应的处理函数,对于上面第6步中是网卡驱动模块抛出的软中断,ksoftirqd会调用网络模块的net_rx_action函数
-
8: net_rx_action调用网卡驱动里的poll函数来一个一个的处理数据包
-
9: 在pool函数中,驱动会一个接一个的读取网卡写到内存中的数据包,内存中数据包的格式只有驱动知道
-
10: 驱动程序将内存中的数据包转换成内核网络模块能识别的skb格式,然后调用napi_gro_receive函数
-
11: napi_gro_receive会处理GRO相关的内容,也就是将可以合并的数据包进行合并,这样就只需要调用一次协议栈。然后判断是否开启了RPS,如果开启了,将会调用enqueue_to_backlog
-
12: 在enqueue_to_backlog函数中,会将数据包放入CPU的softnet_data结构体的input_pkt_queue中,然后返回, 如果input_pkt_queue满了的话,该数据包将会被丢弃,queue的大小可以通过net.core.netdev_max_backlog来 配置
-
13: CPU会接着在自己的软中断上下文中处理自己input_pkt_queue里的网络数据(调用__netif_receive_skb_core)
-
14: 如果没开启RPS,napi_gro_receive会直接调用__netif_receive_skb_core
-
15: 看是不是有AF_PACKET类型的socket(也就是我们常说的原始套接字),如果有的话,拷贝一份数据给它。tcpdump抓包就是抓的这里的包。
-
16: 调用协议栈相应的函数,将数据包交给协议栈处理。
-
17: 待内存中的所有数据包被处理完成后(即poll函数执行完成),启用网卡的硬中断,这样下次网卡再收到数据的时候就会通知CPU
enqueue_to_backlog函数也会被netif_rx函数调用,而netif_rx正是lo设备发送数据包时调用的函数
协议栈
IP层
由于是UDP包,所以第一步会进入IP层,然后一级一级的函数往下调:
|
|
↓ promiscuous mode &&
+--------+ PACKET_OTHERHOST (set by driver) +-----------------+
| ip_rcv |-------------------------------------->| drop this packet|
+--------+ +-----------------+
|
|
↓
+---------------------+
| NF_INET_PRE_ROUTING |
+---------------------+
|
|
↓
+---------+
| | enabled ip forword +------------+ +----------------+
| routing |-------------------->| ip_forward |------->| NF_INET_FOWARD |
| | +------------+ +----------------+
+---------+ |
| |
| destination IP is local ↓
↓ +---------------+
+------------------+ | dst_output_sk |
| ip_local_deliver | +---------------+
+------------------+
|
|
↓
+------------------+
| NF_INET_LOCAL_IN |
+------------------+
|
|
↓
+-----------+
| UDP layer |
+-----------+-
ip_rcv: ip_rcv函数是IP模块的入口函数,在该函数里面,第一件事就是将垃圾数据包(目的mac地址不是当前网卡,但由于网卡设置了混杂模式而被接收进来)直接丢掉,然后调用注册在NF_INET_PRE_ROUTING上的函数
-
NF_INET_PRE_ROUTING: netfilter放在协议栈中的钩子,可以通过iptables来注入一些数据包处理函数,用来修改或者丢弃数据包,如果数据包没被丢弃,将继续往下走
-
routing: 进行路由,如果是目的IP不是本地IP,且没有开启ip forward功能,那么数据包将被丢弃,如果开启了ip forward功能,那将进入ip_forward函数
-
ip_forward: ip_forward会先调用netfilter注册的NF_INET_FORWARD相关函数,如果数据包没有被丢弃,那么将继续往后调用dst_output_sk函数
-
dst_output_sk: 该函数会调用IP层的相应函数将该数据包发送出去,同下一篇要介绍的数据包发送流程的后半部分一样。
-
ip_local_deliver:如果上面routing的时候发现目的IP是本地IP,那么将会调用该函数,在该函数中,会先调用NF_INET_LOCAL_IN相关的钩子程序,如果通过,数据包将会向下发送到UDP层
UDP层
|
|
↓
+---------+ +-----------------------+
| udp_rcv |----------->| __udp4_lib_lookup_skb |
+---------+ +-----------------------+
|
|
↓
+--------------------+ +-----------+
| sock_queue_rcv_skb |----->| sk_filter |
+--------------------+ +-----------+
|
|
↓
+------------------+
| __skb_queue_tail |
+------------------+
|
|
↓
+---------------+
| sk_data_ready |
+---------------+
-
udp_rcv: udp_rcv函数是UDP模块的入口函数,它里面会调用其它的函数,主要是做一些必要的检查,其中一个重要的调用是 __udp4_lib_lookup_skb,该函数会根据目的IP和端口找对应的socket,如果没有找到相应的socket,那么该数据包将会被丢 弃,否则继续
-
sock_queue_rcv_skb: 主要干了两件事,一是检查这个socket的receive buffer是不是满了,如果满了的话,丢弃该数据包,然后就是调用sk_filter看这个包是否是满足条件的包,如果当前socket上设置了filter,且该包不满足条件的话,这个数据包也将被丢弃(在Linux里面,每个socket上都可以像tcpdump里面一样定义filter,不满足条件的数据包将会被丢弃)
-
__skb_queue_tail: 将数据包放入socket接收队列的末尾
-
sk_data_ready: 通知socket数据包已经准备好
调用完sk_data_ready之后,一个数据包处理完成,等待应用层程序来读取,上面所有函数的执行过程都在软中断的上下文中。
socket
应用层一般有两种方式接收数据,一种是recvfrom函数阻塞在那里等着数据来,这种情况下当socket收到通知后,recvfrom就会被唤 醒,然后读取接收队列的数据;另一种是通过epoll或者select监听相应的socket,当收到通知后,再调用recvfrom函数去读取接收队列 的数据。两种情况都能正常的接收到相应的数据包。
结束语
了解数据包的接收流程有助于帮助我们搞清楚我们可以在哪些地方监控和修改数据包,哪些情况下数据包可能被丢弃,为我们处理网络问题提供了一些参考, 同时了解netfilter中相应钩子的位置,对于了解iptables的用法有一定的帮助,同时也会帮助我们后续更好的理解Linux下的网络虚拟设 备。
在接下来的几篇文章中,将会介绍Linux下的网络虚拟设备和iptables。
以上是关于23 网络数据在内核中流转的主要内容,如果未能解决你的问题,请参考以下文章