微信公众号:码农充电站pro
个人主页:https://codeshellme.github.io
当你选择了一种语言,意味着你还选择了一组技术、一个社区。
—— Joshua Bloch
目录

1,什么是计算机编码
编码
信息从一种形式转换到另一种形式的过程,就叫做编码。说白了,编码就是信息的一种转换过程。
比如,信息的加密解密,这就是信息的一种转换过程,它是信息的明文与密文之间的转换过程。
还有不同国家文字的翻译,这是语言之间的一种转换过程。
那么,编码也是一种信息的转换过程。
计算机编码
计算机编码是信息的人类可读形式与计算机可读形式之间的一种转换过程。
实际上,计算机是一种人造的,很“笨”的机器,它只认识0和1 这样的二进制数据,也称为机器码。
提示:计算机优势在于它的计算速度很快。
那么,计算机要想能够存储/展现我们人类可读的,丰富多彩的信息(比如文字,图片,音频,视频等),这就涉及到了计算机编码。
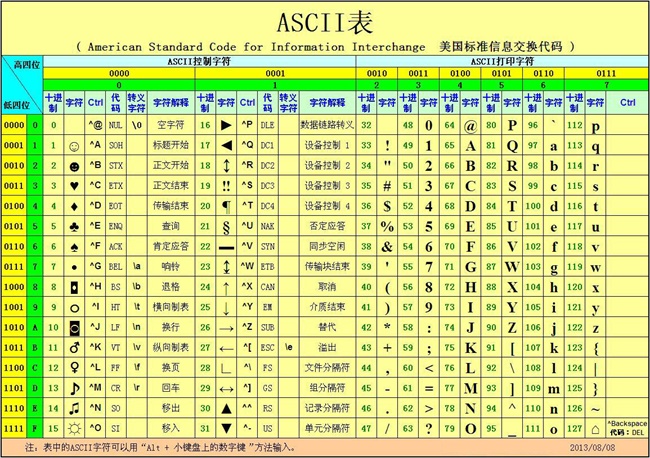
ASCII 码
ASCII 码(美国信息交换标准码),是最早的,也是较为简单的一种计算机编码。其主要用于表示英文字符,数字和一些标点符号。
比如,二进制数字01000001 (十进制为65)就表示大写字母A。
GB2312
ASCII 码 虽能表示英文,但是无法表示其它语言,比如中文,韩文等。
为了表示中文,中国国家标准总局发布了GB2312(信息交换用汉字编码字符集),专门用于表示中文信息。
比如,十六进制D6D0 表示汉字中。
Unicode 码
世界上有很多的国家,每个国家都需要表示自己的文字,这就有了各种各样的计算机编码。每个国家都有自己的编码,这就不方便统一,也没有通用性。
为了统一不同国家的编码,表示不同国家的文字,诞生了Unicode 码,俗称万国码。Unicode 码为每种语言中的每个字符设定了统一且唯一的二进制编码。
比如,十六进制4E2D 表示汉字中。
UTF8
Unicode 码 实际上是一个字符集,它只规定了二进制与各个字符之间的对应关系,并没有规定如何在磁盘上存储(用几个字节来表示)。
提示:
字节是计算机存储的最小单位
1024 字节为1 K
1024 K 为1 M
1024 M 为1 G
UTF32是Unicode 码 的一种实现,一般用4个字节表示一个字符,这样比较浪费存储空间。因为,一个英文字符只用1 个字节就可表示,一个常用汉字用2 个字节就可表示。
为了节省存储空间,UTF8 一般用1 到4 个字节表示一个字符,比如英文字符用1 个字节,常用汉字用2 个字节。
注意:
UTF8是Unicode 码的一种实现,比较常用。UTF8使用变长字节来表示字符,意思就是,使用的字节数是可变的。
2,Python3 源文件编码
在Python2.x 中,Python 源代码文件默认以ASCII 码格式编码。因此,在Python2.x中,默认情况下,是不支持中文的。如果强制写中文,则会出现以下错误:
SyntaxError: Non-ASCII character ...
如果想在Python2.x源代码文件中输入中文字符,可以使用UTF8编码,需要在代码文件的开头添加:
# -*- coding: UTF-8 -*-
或者:
# coding=utf-8
在Python3.x 中,Python 源代码文件会统一采用Unicode 编码,默认以UTF8格式编码,就不需要在代码开头添加上面的代码。
3,Python3 字符串与编码
str 类型
上一节介绍了Python 字符串的相关操作,这里我们介绍一下Python 字符串与编码。
Python3 中的字符串类型<class \'str\'>统一采用Unicode 编码,因此支持多种语言。
>>> print(\'中文\') # 中文
中文
>>>
>>> print(\'english\') # 英文
english
bytes 类型
当str 类型需要磁盘存储或者网络传输时,就需要转换为bytes 类型。
bytes 是一个二进制类型,它需要在str 之前加上b:
>>> type(b\'abc\')
<class \'bytes\'>
bytes 中只能包含ASCII 字符,若有非ASCII 字符,则会报错:
>>> s = b\'中国\'
File "<stdin>", line 1
SyntaxError: bytes can only contain ASCII literal characters.
str 转为 bytes
str 类型转换为bytes 类型,需要使用str 中的encode 方法,参数utf8 是编码格式:
>>> s = \'中国\'
>>> s.encode(\'utf8\')
b\'\\xe4\\xb8\\xad\\xe5\\x9b\\xbd\'
bytes 转为 str
bytes 类型转换为str 类型,需要使用bytes 中的decode 方法,参数utf8 是编码格式:
>>> s = b\'\\xe4\\xb8\\xad\\xe5\\x9b\\xbd\'
>>> s.decode(\'utf8\')
\'中国\'
注意:当
str类型与bytes类型互转时,推荐使用UTF8编码
str 与Unicode 互转
将str 转换为Unicode:
>>> \'中国\'.encode(\'unicode-escape\')
b\'\\\\u4e2d\\\\u56fd\'
将Unicode 转换为str:
>>> b\'\\\\u4e2d\\\\u56fd\'.decode(\'unicode-escape\')
\'中国\'
4,ord() 与 chr()
ord() 函数用于获取一个字符的十进制整数表示,chr() 是 ord() 的反操作:
>>> ord(\'a\')
97
>>> chr(97)
\'a\'
>>> ord(\'中\')
20013
>>> chr(20013)
\'中\'
(完。)
推荐阅读:
Python 简明教程 --- 4,Python 变量与基本数据类型
Python 简明教程 --- 5,Python 表达式与运算符
Python 简明教程 --- 8,Python 字符串函数
欢迎关注作者公众号,获取更多技术干货。
