Pytorch2 如何通过算子融合和 CPU/GPU 代码生成加速深度学习
Posted 冷冻工厂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch2 如何通过算子融合和 CPU/GPU 代码生成加速深度学习相关的知识,希望对你有一定的参考价值。
动动发财的小手,点个赞吧!
PyTorch 中用于图形捕获、中间表示、运算符融合以及优化的 C++ 和 GPU 代码生成的深度学习编译器技术入门
计算机编程是神奇的。我们用人类可读的语言编写代码,就像变魔术一样,它通过硅晶体管转化为电流,使它们像开关一样工作,并允许它们实现复杂的逻辑——这样我们就可以在互联网上欣赏猫视频了。在编程语言和运行它的硬件处理器之间,有一项重要的技术——编译器。编译器的工作是将我们人类可读的语言代码翻译并简化为处理器可以理解的指令。
编译器在深度学习中发挥着非常重要的作用,可以提高训练和推理性能,提高能效,并针对多样化的 AI 加速器硬件。在这篇博文中,我将讨论为 PyTorch 2.0 提供支持的深度学习编译器技术。我将引导您完成编译过程的不同阶段,并通过代码示例和可视化讨论各种底层技术。
什么是深度学习编译器?
深度学习编译器将深度学习框架中编写的高级代码转换为优化的低级硬件特定代码,以加速训练和推理。它通过执行层和运算符融合、更好的内存规划以及生成目标特定的优化融合内核来减少函数调用开销,从而在深度学习模型中找到优化性能的机会。

与传统的软件编译器不同,深度学习编译器必须使用高度可并行化的代码,这些代码通常在专门的 AI 加速器硬件(GPU、TPU、AWS Trainium/Inferentia、Intel Habana Gaudi 等)上加速。为了提高性能,深度学习编译器必须利用硬件特定的功能,例如混合精度支持、性能优化的内核以及最小化主机 (CPU) 和 AI 加速器之间的通信。
在深度学习算法继续快速发展的同时,硬件 AI 加速器也在不断发展,以满足深度学习算法的性能和效率需求。
在这篇博文中,我将重点关注软件方面的事情,尤其是更接近硬件的软件子集——深度学习编译器。首先,让我们先看看深度学习编译器中的不同函数。
PyTorch 2.0 中的深度学习编译器
PyTorch 2.0 包括新的编译器技术,以提高模型性能和运行时效率,并使用一个简单的 API 来针对不同的硬件后端:torch.compile()。虽然其他博客文章和文章已经详细讨论了 PyTorch 2.0 的性能优势,但在这里我将重点关注调用 PyTorch 2.0 编译器时发生的事情。如果你正在寻找量化的性能优势,你可以找到来自 huggingface、timm 和 torchbench 的不同模型的性能仪表板。
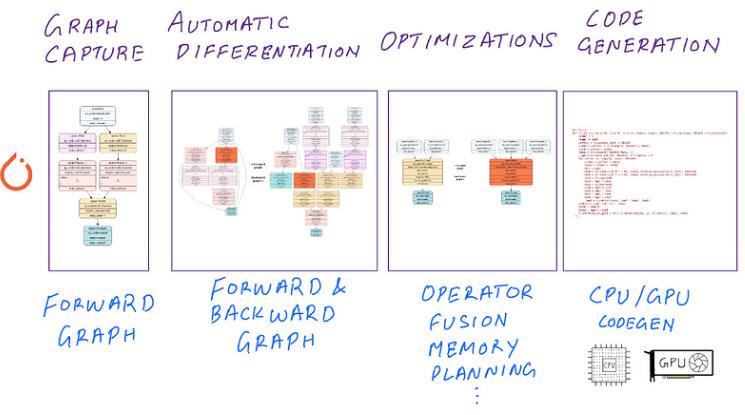
在高层次上,PyTorch 2.0 深度学习编译器的默认选项执行以下关键任务:
- 图形捕获:模型和函数的计算图形表示。 PyTorch 技术:TorchDynamo、Torch FX、FX IR
- 自动微分:使用自动微分和降低到原始运算符的反向图形跟踪。 PyTorch 技术:AOTAutograd、Aten IR
- 优化:前向和后向图级优化和运算符融合。 PyTorch 技术:TorchInductor(默认)或其他编译器
- 代码生成:生成硬件特定的 C++/GPU 代码。 PyTorch 技术:TorchInductor、OpenAI Triton(默认)其他编译器
通过这些步骤,编译器会转换您的代码并生成逐渐“降低”的中间表示 (IR)。降低是编译器词典中的一个术语,指的是通过编译器的自动转换和重写将一组广泛的操作(例如 PyTorch API 支持的)映射到一组狭窄的操作(例如硬件支持的)。 PyTorch 2.0 编译器流程:
如果您不熟悉编译器术语,请不要让所有这些吓到您。我也不是编译器工程师。继续阅读,事情会变得清晰,因为我将使用一个简单的示例和可视化来分解这个过程。
遍历 torch.compile() 编译器过程
为了简单起见,我将定义一个非常简单的函数并通过 PyTorch 2.0 编译器进程运行它。您可以将此函数替换为深度神经网络模型或 nn.Module 子类,但与复杂的数百万参数模型相比,此示例应该可以帮助您更好地了解引擎盖下发生的事情。
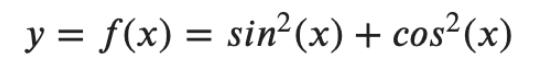
该函数的 PyTorch 代码:
def f(x):
return torch.sin(x)**2 + torch.cos(x)**2
如果你在高中三角学课上注意过,你就会知道我们函数的值对于所有实值 x 总是为 1。这意味着它是导数,常数的导数,并且必须等于零。这将有助于验证函数及其派生函数的作用。
现在,是时候调用 torch.compile() 了。首先让我们说服自己编译这个函数不会改变它的输出。对于相同的 1x1000 随机向量,我们函数的输出与 1s 向量之间的均方误差对于编译函数和未编译函数(在一定的误差容限下)都应该为零。
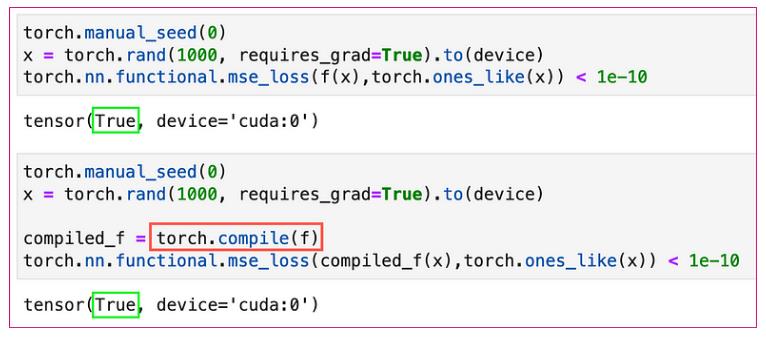
我们所做的只是添加一行额外的代码 torch.compile() 来调用我们的编译器。现在让我们来看看每个阶段的幕后情况。
图形捕获:PyTorch 模型或函数的计算图形表示
编译器的第一步是确定编译什么。输入 TorchDynamo。 TorchDynamo 拦截您的 Python 代码的执行并将其转换为 FX 中间表示 (IR),并将其存储在称为 FX Graph 的特殊数据结构中。你问这看起来像什么?很高兴你问。下面,我们将看一下我们用来生成它的代码,但这里是转换和输出:
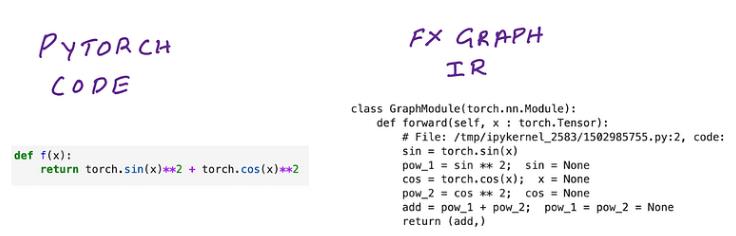
重要的是要注意,Torch FX 图只是 IR 的容器,并没有真正指定它应该包含哪些运算符。在下一节中,我们将看到 FX 图形容器再次出现,并带有一组不同的 IR。如果比较功能代码和 FX IR,两者之间的差别很小。事实上,它与您编写的 PyTorch 代码相同,但以 FX 图形数据结构所需的格式进行布局。它们在执行时都将提供相同的结果。
如果您调用 torch.compile() 时不带任何参数,它将使用运行整个编译器堆栈的默认设置,其中包括名为 TorchInductor 的默认硬件后端编译器。但是,如果我们现在讨论 TorchInductor 就会跳到前面,所以让我们暂时搁置这个话题,等我们准备好后再回来讨论。首先我们需要讨论图形捕获,我们可以通过拦截来自 torch.compile() 的调用来实现。下面是我们将如何做到这一点: torch.compile() 也允许你提供自己的编译器,但因为我不是编译器工程师,而且我对如何编写编译器一无所知,所以我会提供一个伪造的编译器函数来捕获 TorchDynamo 生成的 FX 图形 IR。
下面是我们的假编译器后端函数,称为 inspect_backend 到 torch.compile(),在该函数中我做了两件事:
- 打印 TorchDynamo 捕获的 FX IR 代码
- 保存 FX 图形可视化
def inspect_backend(gm, sample_inputs):
code = gm.print_readable()
with open("forward.svg", "wb") as file:
file.write(FxGraphDrawer(gm,\'f\').get_dot_graph().create_svg())
return gm.forward
torch._dynamo.reset()
compiled_f = torch.compile(f, backend=inspect_backend)
x = torch.rand(1000, requires_grad=True).to(device)
out = compiled_f(x)
上述代码片段的输出是 FX IR 代码和显示函数 sin2(x)+cos2(x) 的图表
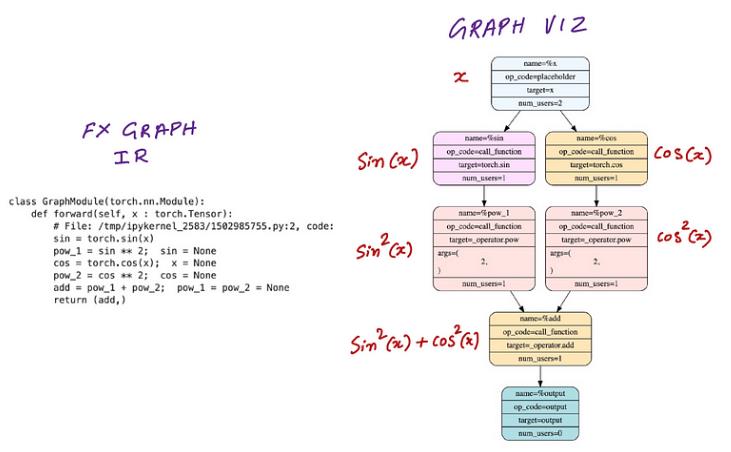
请注意,我们的假编译器 inspect_backend 函数仅在我们使用一些数据调用已编译函数时调用,即当我们调用 compiled_model(x) 时。在上面的代码片段中,我们只评估函数或在深度学习术语中,进行“前向传播”。在下一节中,我们将利用 PyTorch 的自动微分引擎 torch.autograd 来计算导数和“向后传递”图。
自动微分:正向和反向计算图
TorchDynamo 为我们提供了作为 FX 图的前向传递函数评估,但是向后传递呢?为了完整起见,我将偏离我们的主要主题,谈谈为什么我们需要根据函数的权重来评估函数的梯度。如果您已经熟悉数学优化的工作原理,请跳过本节。
什么是深度学习优化编译器?
用于深度学习的优化编译器善于发现代码中的性能差距,并通过转换代码以减少代码属性(例如目标后端的内存访问、内核启动、数据布局优化)来解决这些问题。 TorchInductor 是带有 torch.compile() 的默认优化编译器,它可以为使用 OpenAI Triton 的 GPU 和使用 OpenMP pragma 指令的 CPU 生成优化内核。
本文由mdnice多平台发布
MXNet 图优化与算子融合
MXNet 图优化与算子融合Graph Optimization and Quantization based on subgraph and MKL-DNN
Purpose
MKL-DNN引入了两个高级特性:融合计算和降精度核。这些特性可以显著地提高各种深度学习拓扑在CPU上的推理性能。
然而,MXNet由于图表示的局限性和以往缺乏图的优化,仍然不能从中受益。幸运的是,MXNet的新子图特性使这些改进现在成为可能。
本文说明基于子图的解决方案,以利用MKL-DNN在MXNet中的功能。一般来说,解决方案将MKL-DNN算子划分为子图,然后在子图中用融合的内核(如果可能)替代这些MKL-DNN算子。可以通过使用MKL-DNN的降精度核(如INT8核)来选择量化流,加速模型的推理过程。
Milestone
本文三个步骤可被视为本项目的里程碑,并用于跟踪过程。
•完成后,将子图分支转换为主分支
•完成,MKL-DNN融合实现到子图分支
•完成后,将量化流实现提交到主分支
Workflow
步骤1. 将MKL-DNN算子划分到子图中
这是子图的主要用途之一。可以列出所有支持的运算符MKL-DNN,并将其传递给DefaultSubgraphProperty。应用图划分后,所有MKL-DNN算子都将分组到子图节点中,子图边界上的数据格式将自动在MKL-DNN内部格式和NDArray默认格式之间转换。根据执行模式,子图边界有点不同。
1. Symbolic mode
子图将尽量覆盖相邻的MKL-DNN算子。
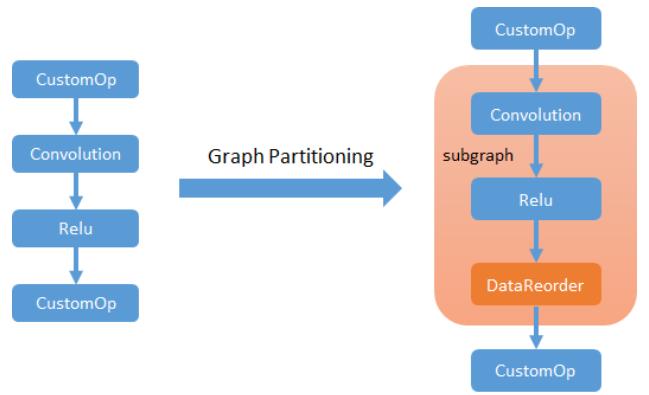
2. Imperative mode
命令式
每个MKL-DNN操作符将在一个独立的子图中执行,以确保MKL-DNN内部格式不会暴露在子图之外。

Step 2. MKL-DNN operator fusion
MKL-DNN算子融合
MKL-DNN库支持在一次执行中,运行多个特定的模式算子。比如卷积+relu。可以定义新的SubgraphSelector子图选择器,捕获这种操作符模式,并生成新的MKL-DNN特定算子来替换原来的算子。
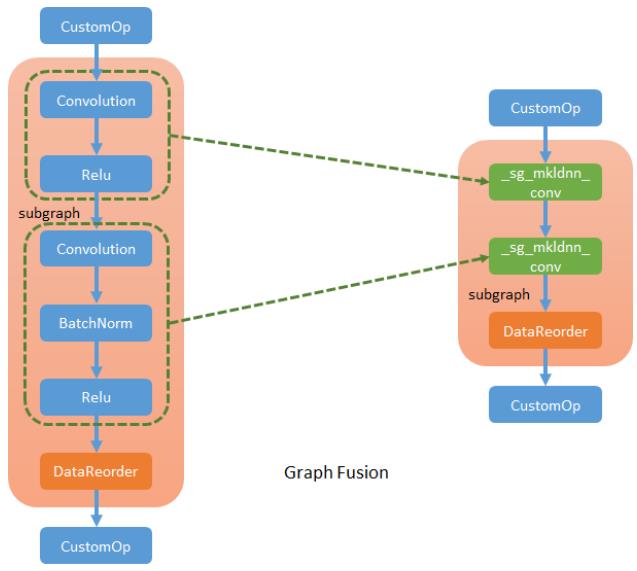
新的融合算子是独立算子,表示定义的MKL-DNN库算子。例如,在MKL-DNN库中,卷积可以支持在卷积之后执行relu的post算子。因此,对于卷积+relu融合,将创建一个MKL-DNN卷积(命名为_sg_MKL-DNN_conv),并将relu描述为后算子。
NNVM_REGISTER_OP(_sg_MKL-DNN_conv)
.set_attr<FStatefulComputeEx>("FStatefulComputeEx<cpu>", SgMKL-DNNConvOpForward)
In general, new fused operators follow the abstraction of MKL-DNN library, and subgraph fusion pass is the lowering process to convert NNVM common graph to MKL-DNN graph. Fusion pass only happens inside the subgraph created by step1, so won’t affect MXNet default operators.
一般来说,新的融合算子遵循MKL-DNN库的抽象,子图融合pass是NNVM common图到MKL-DNN图的降阶过程。融合pass只发生在由step1创建的子图中,不会影响MXNet默认算子。
Step 3. Quantization
MKL-DNN支持卷积神经网络中大多数精度较低的基元,尤其是融合基元。MXNet INT8推理包括两个步骤:
1. INT8模型,量化参数,收集校准数据准备
只执行此步骤一次。为了在FP32模型的基础上建立INT8模型,在MKL-DNN支持的情况下,在子图内部运行QuantizeGraph pass,用INT8算子代替FP32算子,并在适当的位置插入dequantize解量化算子。
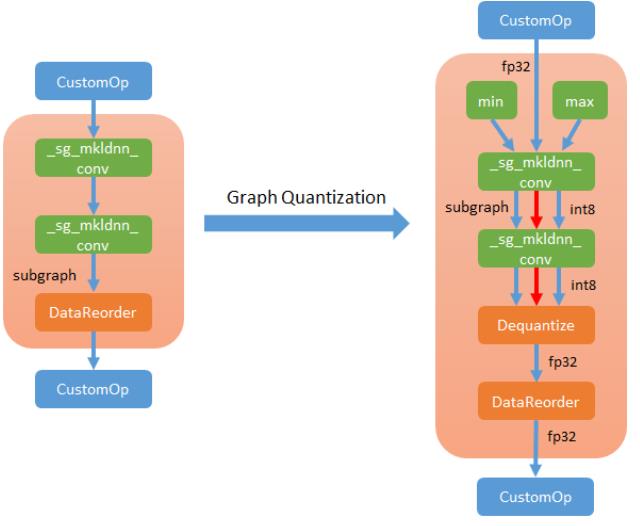
2. Run INT8 inference
当INT8符号和参数准备好进行inference时,用户可以对与以前相同的新输入数据进行推理。
Accuracy Validation
在使用MKL-DNN时,无论量化程度如何,子图解本身都不会引入精度损失,反而会增强框架的稳定性。
|
NETWORK |
FP32 |
FP32 with Fusion |
||
|
Top1 |
Top5 |
Top1 |
Top5 |
|
|
Resnet-152 by MKL-DNN |
77.16 |
92.98 |
77.16 |
92.98 |
|
Inception by MKL-DNN |
72.36 |
90.58 |
72.36 |
90.58 |
在量化允许的情况下,MKL-DNN与采用熵模式校准的FP32相比,可以在不到0.5%的精度损失范围内获得巨大的性能改进。
Accuracy data from the internal branch are shown in below table .
|
|
FP32 |
INT8 |
|||||
|
|
|
No Calibration |
Calibration using 5 batches |
Calibration Method |
|||
|
NETWORK |
Top1 |
Top5 |
Top1 |
Top5 |
Top1 |
Top5 |
|
|
Resnet-152 by GPU |
77.19 |
93.01 |
75.56 |
92.32 |
75.58 |
92.24 |
Threshold by min/max |
|
75.65 |
92.35 |
Threshold by entropy loss |
|||||
|
Resnet-152 by MKL-DNN |
77.16 |
92.98 |
76.59 |
92.71 |
76.44 |
92.69 |
Threshold by min/max |
|
76.76 |
92.79 |
Threshold by entropy loss |
|||||
|
Inception-bn by GPU |
72.38 |
90.61 |
71.98 |
90.26 |
71.78 |
90.26 |
Threshold by min/max |
|
71.98 |
90.36 |
Threshold by entropy loss |
|||||
|
Inception-bn by MKL-DNN |
72.36 |
90.58 |
72.21 |
90.50 |
72.16 |
90.43 |
Threshold by min/max |
|
72.19 |
90.45 |
Threshold by entropy loss |
|||||
Performance
On performance part, both fusion and quantization can provide the huge improvement on various kinds of topologies.
Below is the inference performance data(images/sec) from the internal branch based on SKX-8180 1 socket with batch size 64.
在性能方面,融合和量化都可以为各种拓扑结构提供巨大的改进。
以下是基于批处理大小为64的SKX-8180 套接字的内部分支的推理性能数据(图像/秒)。
|
Topology |
Base |
With Fusion |
With Fusion + Quantization |
|
resnet50-v1 |
208.17 |
348.80 |
568.25 |
|
resnet50-v2 |
198.87 |
256.10 |
|
|
vgg-16 |
92.11 |
101.00 |
150.92 |
|
inception-bn |
475.74 |
658.75 |
836.94 |
|
inception-v3 |
175.97 |
227.29 |
327.39 |
|
inception-v4 |
88.99 |
109.15 |
|
|
inception-resnet-v2 |
104.13 |
124.75 |
|
|
mobilenet 1.0 |
668.71 |
1380.64 |
1788.95 |
|
squezenet |
708.63 |
849.27 |
975.90 |
测试用例量化解决方案仍在开发中。准备好后会分享更多的数据。
测试需要包括两个部分。第一个是图形转换测试。需要确保:
|
Step |
Criterion |
|
1 |
所有MKL-DNN算子按执行方式划分为一个或多个子图。 |
|
2 |
可以捕获所需的模式并创建所需的融合算子。 |
|
3 |
量化过程可以将期望的算子转换为具有正确数据连接的量化版本。 |
另一个是MKL-DNN特定融合算子的单元测试。测试应涵盖所有融合场景,以确保融合算子能够提供准确的结果。
Q & A
•用户将如何调用该功能-要使用的工作流、命令和API是什么?
此功能将在其成熟后启用。
•计划进行哪些API增强(或更改)?有关于向后兼容性的问题吗?
此更改应用了方案提供的API,没有向后兼容性问题。
•调度的单元和集成测试是什么?完整模型的E2E测试是好的,需要一些小测试,可以通过PR检查和常规回归来执行。
将进行完整的测试,包括单元测试和模型级测试。增加单元测试,检查生成的图形和融合运算器输出的正确性。
模型级测试将检查新变化的训练和推理精度。
•添加非CV测试用例。
测试了RNN,GAN,RL网络。例如,通过sockeye模型(GNMT、transformers)验证性能和功能。
•是否正确地假设用户选择完全独立于底层后端的算子?
不完全是。在这个阶段,后端流不会随子图而改变。
通过在runtime生成变量(USE \\u MKLDNN,USE \\u CUDNN)和ctx(gpu,cpu)来指定用户的后端。
•这是否意味着如果要卷积,例如,mxnet将自动在cpu、GPU和mkldnn之间进行选择?如果是的话,这到底是怎么做到的?
不,按照当前的MXNet后端使用情况,用户不能在不同的后端之间切换单个算子。
•认为重要的是,必须明确区分算子及其不同的实现。最后,用户应该能够定义一个网络图,有责任找到执行它的最佳方式。
同意。最后,应该达到这个状态,但这不是这一步的目标。
以上是关于Pytorch2 如何通过算子融合和 CPU/GPU 代码生成加速深度学习的主要内容,如果未能解决你的问题,请参考以下文章
基于改进的多算子融合的图像识别系统设计matlab优化算法十四