OpenPPL PPQ量化:量化计算图的加载和预处理 源码剖析
Posted 沉迷单车的追风少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenPPL PPQ量化:量化计算图的加载和预处理 源码剖析相关的知识,希望对你有一定的参考价值。
目录

前言
上一篇博客从quantize_onnx_model()为切入点,详细剖析了量化一个onnx模型的流程。在设置QuantizationSettingFactory量化设置之后,首先要构建量化图、分割量化图。
ppq_ir = load_onnx_graph(onnx_import_file=onnx_import_file)
ppq_ir = dispatch_graph(graph=ppq_ir, platform=platform,
dispatcher=setting.dispatcher,
dispatching_table=setting.dispatching_table)加载计算图
load_onnx_graph()当中包含两个逻辑:(1)从模型地址从解析模型得到原始计算图;(2)预处理,统一计算图格式
def load_onnx_graph(onnx_import_file: str) -> BaseGraph:
"""
从一个指定位置加载 onnx 计算图,注意该加载的计算图尚未经过调度,此时所有算子被认为是可量化的
load onnx graph from the specified location
Args:
onnx_import_file (str): onnx 计算图的保存位置 the specified location
Returns:
BaseGraph: 解析 onnx 获得的 ppq 计算图对象 the parsed ppq IR graph
"""
# 解析模型
ppq_ir = load_graph(onnx_import_file, from_framework=NetworkFramework.ONNX)
# 预处理模型
return format_graph(graph=ppq_ir)解析模型
从模型地址中解析模型由load_graph()方法实现。除了模型文件的地址之外,我们需要知道是那一类模型,或者是原生的计算图。
PPQ分成了5类:
class NetworkFramework(Enum):
PPL = 1
ONNX = 2
CAFFE = 3
NXP = 4
NATIVE = 5其中PPL、NXP应该是预留的,暂时在代码中未见到使用。如果任何模型的量化都按照quantize_onnx_model()方法进行,是用不到CAFFE等其他方法的,因为都是先转换成ONNX模型再量化,所以量化的都是onnx模型。
和上一篇文章选择量化方法一样,这里由于会有5种可以选择的解析方法,所以初始化的时候也有不同的方法可以选择。根据传入的from_framework选择不同的解析方法:
parser = PFL.Parser(from_framework)ONNX模型解析
由OnnxParser类实现。
onnx模型解析能力依赖onnx库实现,可以参看官方手册:torch.onnx — PyTorch 1.13 documentation
直接调用onnx库load接口,已经把onnx计算图解析了,然后用解析后的原始计算图初始化『量化计算图』BaseGraph
graph = parser.build(file_path)这个parser方法命名可能是借鉴是onnx库的parse吧:

一共有三种parse:OnnxParser、CaffeParser、NativeImporter,先看看OnnxParser是如何实现的。
用onnx.load()方法加载模型,看onnx官方的介绍:onnx/ExternalData.md at 136a2c0e0757e3a71cfce7e8aa06e08a61c8ee5b · onnx/onnx · GitHub
这应该是以一个字典key-value格式存储的,这方面具体的细节以后再研究研究~

之前说过在量化的全流程中,所有信息都是由BaseGraph这个类保存和管理的。先用graph_pb.name新建一个量化图:
graph = BaseGraph(name=graph_pb.name, built_from=NetworkFramework.ONNX)接下来就是向这个新建的graph里面填充我们想要的东西,首先要设置每个opset的属性,这个属性里包括domain和version,注意这个设置是op粒度的。
graph._detail[GRAPH_OPSET_ATTRIB] = self.convert_opsets_to_str(opsets)
graph._detail['ir_version'] = model_pb.ir_version
onnx_import_opset = DEFAULT_OPSET_VERSION
for opset in graph._detail[GRAPH_OPSET_ATTRIB]:
if opset['domain'] == DEFAULT_OPSET_DOMAIN or opset['domain'] == '':
onnx_import_opset = opset['version']
break
然后遍历每个节点,然后进行初始化参数。所谓初始化参数initialize_params()就是把对应节点的is_parameter设置为TRUE,表示这个节点是有参数的:
def initialize_params(self, graph: BaseGraph, initializer: Dict[str, Any]) -> BaseGraph:
for var in graph.variables.values():
if var.name in initializer:
for dest_op in var.dest_ops:
assert isinstance(dest_op, Operation)
dest_op.parameters.append(var)
var.value = initializer[var.name]
var.is_parameter = True
return graph之前说过这里主要是载入并初始化量化计算图,还不涉及具体计算图优化。但是会做一步移除无需量化的节点:
self.de_inplace(graph)
如果底部和顶部的名称相同,这意味着该层的计算已到位。
至此,解析onnx的逻辑基本完成。
原生计算图解析
由NativeImporter类实现。
因为此时传入的模型已经被转换成了计算图,所以不需要像载入onnx模型那样做遍历、解析、修改属性等操作了:
class NativeImporter(GraphBuilder):
def __init__(self) -> None:
super().__init__()
def build(self, file_path: str, **kwargs) -> BaseGraph:
def load_elements_from_file(file, num_of_elements: int) -> list:
try: return [load(file) for _ in range(num_of_elements)]
except EOFError as e:
raise Exception('File format parsing error. Unexpected EOF found.')
with open(file_path, 'rb') as file:
signature, version, graph = load_elements_from_file(file, 3)
if signature != 'PPQ GRAPH DEFINITION':
raise Exception('File format parsing error. Graph Signature has been damaged.')
if str(version) > PPQ_CONFIG.VERSION:
print(f'\\033[31mWarning: Dump file is created by PPQ(str(version)), '
f'however you are using PPQ(PPQ_CONFIG.VERSION).\\033[0m')
assert isinstance(graph, BaseGraph), (
'File format parsing error. Graph Definition has been damaged.')
try:
for op in graph.operations.values():
input_copy, _ = op.inputs.copy(), op.inputs.clear()
for name in input_copy: op.inputs.append(graph.variables[name])
output_copy, _ = op.outputs.copy(), op.outputs.clear()
for name in output_copy: op.outputs.append(graph.variables[name])
for var in graph.variables.values():
dest_copy, _ = var.dest_ops.copy(), var.dest_ops.clear()
for name in dest_copy: var.dest_ops.append(graph.operations[name])
if var.source_op is not None:
var.source_op = graph.operations[var.source_op]
graph._graph_inputs = name: graph.variables[name] for name in graph._graph_inputs
graph._graph_outputs = name: graph.variables[name] for name in graph._graph_outputs
except Exception as e:
raise Exception('File format parsing error. Graph Definition has been damaged.')
return graph
量化计算图预处理
废了好大劲终于把一个onnx转换成我们需要的量化计算图BaseGraph,然而这只是开胃小菜,真正的大戏才刚刚开始~
format_graph()方法提供了预处理计算图功能。作者把规则写的很清楚:
在 PPQ 中,我们不希望出现 Constant 算子,所有 Constant 输入将被当作 parameter variable 连接到下游算子上
在 PPQ 中,我们不希望出现 Batchnorm 算子,所有 Batchnorm 将被合并。融合Conv+bn、ConvTranspose+bn、Gemm+bn。
在 PPQ 中,我们不希望出现权重共享的算子,所有被共享的权重将被复制分裂成多份
在 PPQ 中,我们不希望出现孤立算子,所有孤立算子将被移除
我补充几个作者没有写到注释里,但是代码中实际使用到的:
add算子融合:Conv + Add, ConvTranspose + Add, Gemm + Add三连均需融合。
单独batchnorm算子:替换成卷积
# 读取 Onnx 图时,将图中所有以 Constant 节点作为输入的变量转换为 Parameter Variable
FORMATTER_FORMAT_CONSTANT_INPUT = True
# 读取 Onnx 图时,合并图中的 Bias add 节点(Conv, ConvTranspose, Gemm)
FORMATTER_FUSE_BIAS_ADD = True
# 读取 Onnx 图时,合并图中的 Batchnorm 节点(Conv, ConvTranspose, Gemm)
FORMATTER_FUSE_BN = True
# 读取 Onnx 图时,将单独的 Batchnorm 替换为卷积
FORMATTER_REPLACE_BN_TO_CONV = True
# 读取 Onnx 图时,移除图中的 Identity 节点
FORMATTER_REPLACE_REMOVE_IDENTITY = True
# 读取 Onnx 图时,移除图中的孤立节点
FORMATTER_REPLACE_REMOVE_ISOLATED = Trueconstant算子优化
因为部分部署平台不支持 Constant Op 作为算子的输入,所以将图中所有以 Constant 节点作为输入的变量转换为 Parameter Variable。
我们遍历计算图,先记录需要移除的constant op,并把已经移除的constant op写入一个removing_ops列表:
removing_ops = []
for op in self.graph.operations.values():
if op.type == 'Constant':
assert len(op.outputs) == 1, (
f'Constant Operation op.name has more than 1 output, is there a network parsing error?')
removing_ops.append(op)然后遍历removing_ops列表。之前说初始化参数的时候说过,通过设置每一个Operation的_is_parameter=Ture可以实现参数化。然后设置value,最后才做真正的移除算子。设置value后记得把value转换成tensor,调用convert_to_tensor()方法即可。
for const_op in removing_ops:
assert isinstance(const_op, Operation)
constant_value = const_op.attributes['value']
output_var = const_op.outputs[0]
output_var._is_parameter = True
output_var.value = constant_value
self.graph.remove_operation(removing_op=const_op) def remove_constant_input(self) -> None:
"""部分部署平台不支持 Constant Op 作为算子的输入
在这种情况下我们使用这个 pass 把它们切换成 Parameter Variable
Some backend platform doesn't support Constant
Op, we use this pass to replace it by forcing its value to be a
parameter variable."""
removing_ops = []
for op in self.graph.operations.values():
if op.type == 'Constant':
assert len(op.outputs) == 1, (
f'Constant Operation op.name has more than 1 output, is there a network parsing error?')
removing_ops.append(op)
for const_op in removing_ops:
assert isinstance(const_op, Operation)
constant_value = const_op.attributes['value']
output_var = const_op.outputs[0]
output_var._is_parameter = True
output_var.value = constant_value
self.graph.remove_operation(removing_op=const_op)
batchnorm算子优化
首先复习一下batchnorm是什么?
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正太分布而不是正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
BN的优点
- BN将Hidden Layer的输入分布从饱和区拉到了非饱和区,减小了梯度弥散,提升了训练速度,收敛过程大大加快,还能增加分类效果。
- Batchnorm本身上也是一种正则的方式(主要缓解了梯度消失),可以代替其他正则方式如dropout等。
- 调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。
BN的缺陷
batch normalization依赖于batch的大小,当batch值很小时,计算的均值和方差不稳定。
需要记住batchnorm的公式,后面融算子的时候需要用:
另外batchnorm在NLP的模型中用的比较少,NLP中用的更多的是layernorm。layernorm是针对一层网络所有的神经元做数据归一化,因此对batch_size的大小并不敏感。
batchnorm和conv算子融合的原理可以参看这篇博客:卷积与BatchNorm融合方法 - 知乎

能读懂上面这个融合原理下面的代码就很好理解了,我们依旧是只融合Conv+bn、ConvTranspose+bn、Gemm+bn。
大致的逻辑是计算新的系数和偏置项,然后删除旧节点插入新节点。
def fuse_bn(self):
search_engine = SearchableGraph(graph=self.graph)
paths = search_engine.path_matching(
sp_expr=lambda x: x.type in 'Conv', 'Gemm', 'ConvTranspose',
rp_expr=lambda x, y: False,
ep_expr=lambda x: x.type == 'BatchNormalization',
direction='down')
for path in paths:
path = path.tolist()
assert len(path) == 2, ('Oops seems we got something unexpected.')
computing_op, bn_op = path
assert isinstance(computing_op, Operation) and isinstance(bn_op, Operation)
if (len(self.graph.get_downstream_operations(computing_op)) != 1 or
len(self.graph.get_upstream_operations(bn_op)) != 1):
ppq_warning(f'PPQ can not merge operation computing_op.name and bn_op.name, '
'this is not suppose to happen with your network, '
'network with batchnorm inside might not be able to quantize and deploy.')
continue
assert len(bn_op.parameters) == 4, 'BatchNorm should have 4 parameters, namely alpha, beta, mean, var'
alpha = bn_op.parameters[0].value
beta = bn_op.parameters[1].value
mean = bn_op.parameters[2].value
var = bn_op.parameters[3].value
epsilon = bn_op.attributes.get('epsilon', 1e-5)
if computing_op.num_of_parameter == 1:
w = computing_op.parameters[0].value # no bias.
assert isinstance(w, torch.Tensor), 'values of parameters are assumed as torch Tensor'
if computing_op.type == 'ConvTranspose':
b = torch.zeros(w.shape[1] * computing_op.attributes.get('group', 1))
elif computing_op.type == 'Gemm' and computing_op.attributes.get('transB', 0) == 0:
b = torch.zeros(w.shape[1])
else:
b = torch.zeros(w.shape[0])
else:
w, b = [var.value for var in computing_op.parameters[: 2]] # has bias.
if computing_op.type == 'Conv':
# calculate new weight and bias
scale = alpha / torch.sqrt(var + epsilon)
w = w * scale.reshape([-1] + [1] * (w.ndim - 1))
b = alpha * (b - mean) / torch.sqrt(var + epsilon) + beta
elif computing_op.type == 'Gemm':
# calculate new weight and bias
scale = alpha / torch.sqrt(var + epsilon)
if computing_op.attributes.get('transB', 0):
w = w * scale.reshape([-1, 1])
else:
w = w * scale.reshape([1, -1])
b = alpha * (b - mean) / torch.sqrt(var + epsilon) + beta
elif computing_op.type == 'ConvTranspose':
scale = alpha / torch.sqrt(var + epsilon)
group = computing_op.attributes.get('group', 1)
scale = scale.reshape([group, 1, -1, 1, 1])
w = w.reshape([group, -1, w.shape[1], w.shape[2], w.shape[3]]) * scale
w = w.reshape([w.shape[0] * w.shape[1], w.shape[2], w.shape[3], w.shape[4]])
b = alpha * (b - mean) / torch.sqrt(var + epsilon) + beta
else:
raise TypeError(
f'Unexpected op type computing_op.type. '
f'Can not merge computing_op.name with bn_op.name')
# create new op and variable
merged_op = Operation(computing_op.name, op_type=computing_op.type,
attributes=computing_op.attributes.copy())
weight_var = Variable(computing_op.name + '_weight', w, True, [merged_op])
bias_var = Variable(computing_op.name + '_bias', b, True, [merged_op])
# replace & dirty work
input_var = computing_op.inputs[0]
output_var = bn_op.outputs[0]
input_var.dest_ops.remove(computing_op)
input_var.dest_ops.append(merged_op)
output_var.source_op = merged_op
# delete old operations
computing_op.inputs.pop(0)
bn_op.outputs.clear()
self.graph.remove_operation(computing_op)
# insert new
self.graph.append_operation(merged_op)
merged_op.inputs.extend([input_var, weight_var, bias_var])
merged_op.outputs.extend([output_var])
self.graph.append_variable(weight_var)
self.graph.append_variable(bias_var)单独batchnorm算子替换成卷积
因为单独的batchnorm在上一步骤batchnorm融合时,无法被检索到(因为图搜索的起点被指定为conv、convtranspose、gemm)。小伙伴们观察一下batchnorm的公式,也是一次函数的关系,和卷积运算是一样的,所以把单独的batchnorm替换成卷积运算有理有据。
具体的做法依旧是先取出batchnorm中的参数,然后运算得到新卷积的系数和偏置,解决删除旧节点插入新节点。
def replace_batchnorm_to_conv(self, dimension: int = 2):
""" Replace Batchnorm to 1D Convolution. """
for op in self.graph.operations.values():
if op.type == 'BatchNormalization':
ppq_warning(f'Isolated BatchNormalization(op.name) was detected, '
f'PPQ will replace it to 1*1 Convolution(dimensionD).')
assert len(op.parameters) == 4, "BatchNorm should have 4 parameters, namely alpha, beta, mean, var"
alpha = op.parameters[0].value
beta = op.parameters[1].value
mean = op.parameters[2].value
var = op.parameters[3].value
epsilon = op.attributes.get("epsilon", 1e-5)
with torch.no_grad():
w = alpha / torch.sqrt(var + epsilon)
w = w.reshape([-1, 1] + [1] * dimension)
b = alpha * (-mean) / torch.sqrt(var + epsilon) + beta
op.type = 'Conv'
op.attributes.clear()
op.attributes['kernel_shape'] = [1] * dimension
op.attributes['strides'] = [1] * dimension
op.attributes['dilations'] = [1] * dimension
op.attributes['pads'] = [0, 0] * dimension
op.attributes['group'] = w.numel()
# remove last 2 variable, make conv has exact 3 input
self.graph.remove_variable(op.inputs[-1])
self.graph.remove_variable(op.inputs[-1])
with torch.no_grad():
op.inputs[1].value = w
op.inputs[2].value = badd算子融合
只融合Conv + Add, ConvTranspose + Add, Gemm + Add这三类算子。
可以这么理解:
conv的公式是:z = w * x + a
add的公式是:y = z + b
融合起来就是:y = w * x + (a + b)
相当于只有常数项(偏置项)发生了改变!所以改变原来算子中的偏置项bias即可:
def fuse_bias_add(self):
"""
Fuse Pattern like Conv + Add, ConvTranspose + Add, Gemm + Add
This fusion will require a constant input as bias.
"""
graph = self.graph
for op in [_ for _ in graph.operations.values()]:
if op.type in 'Conv', 'ConvTranspose', 'Gemm':
# check if current op has only 1 downstream op
channel_dimension = 1 # NCHW, NCHWD, NCH
if op.type == 'Gemm': channel_dimension
if len(graph.get_downstream_operations(op)) == 1:
down = graph.get_downstream_operations(op)[0]
if down.type == 'Add':
if down.num_of_parameter != 1: continue
bias = down.parameters[0]
if op.type not in 'Gemm':
# check if it is a bias add
if not bias.value.dim() == op.parameters[0].value.dim(): continue
if not bias.value.squeeze().dim() == 1: continue
if bias.value.shape[channel_dimension] == 1: continue
bias.value = bias.value.squeeze() # conv bias can only be 1d
else:
# Gemm bias can be any shape.
# see https://github.com/onnx/onnx/blob/main/docs/Changelog.md#Gemm-11
pass
# ready for fusion
if op.num_of_input == 3: # already has a bias
pass
else:
graph.create_variable(is_parameter=True, value=bias.value, dest_ops=[op])
graph.remove_operation(removing_op=down, keep_coherence=True)cast算子
cast算子的作用是数据类型转换,PPQ需要把原生的数据类型转换到自己定义的数据类型ppq.core.DataType上,映射表如下:
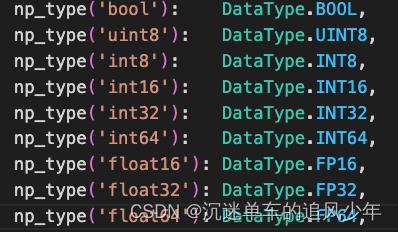
opset1算子
官方注释是这么写的:
Slice: opset1 格式跟其他的不太一样,这个 pass 将 opset1 的 slice 强行转换为 opset 11
emmmm注释和代码没看懂,先mark~
CLIP算子
clip算子的作用是将输入的所有元素进行剪裁,使得输出元素限制在[min, max]内。

预处理这个算子的原因是对于不同的模型格式, clip 算子将有两种不同的输入格式,需要统一。
对于不同的模型格式, clip 算子将有两种不同的输入格式:
for different models, possibly clip op has the following input formats
1. min, max 参数由 第二、第三个输入变量给出
min, max parameter will be given by the second and third input variable
2. min, max 参数由 attribute 给出
min, max parameter will be given by the attribute
此函数统一 clip 算子行为:所有 clip 算子的 min, max 参数第二第三个变量给出
this func unifies behaviors of clip op: min, max parameter will be given by input vars
针对可能存在的 min, max 为空的情况,将其直接置为 2 << 30(保证处理后非空)
当 min, max 参数由 第二、第三个输入变量给出时,其中一个为空时直接返回 ValueError
ValueError will be raised when any of min, max parameters is null
def format_clip(self) -> None:
"""
对于不同的模型格式, clip 算子将有两种不同的输入格式:
for different models, possibly clip op has the following input formats
1. min, max 参数由 第二、第三个输入变量给出
min, max parameter will be given by the second and third input variable
2. min, max 参数由 attribute 给出
min, max parameter will be given by the attribute
此函数统一 clip 算子行为:所有 clip 算子的 min, max 参数第二第三个变量给出
this func unifies behaviors of clip op: min, max parameter will be given by input vars
针对可能存在的 min, max 为空的情况,将其直接置为 2 << 30(保证处理后非空)
当 min, max 参数由 第二、第三个输入变量给出时,其中一个为空时直接返回 ValueError
ValueError will be raised when any of min, max parameters is null
"""
interested_ops = []
for _, operation in self.graph.operations.items():
if operation.type == 'Clip' and ('min' in operation.attributes or 'max' in operation.attributes):
interested_ops.append(operation)
for op in interested_ops:
assert isinstance(op, Operation)
min = op.attributes.get('min', - 2 << 30)
max = op.attributes.get('max', + 2 << 30)
min_var = Variable(name=op.name + '_min', value=min, is_parameter=True, dest_ops=[op])
max_var = Variable(name=op.name + '_max', value=max, is_parameter=True, dest_ops=[op])
self.graph.append_variable(min_var)
self.graph.append_variable(max_var)
op.inputs.append(min_var)
op.inputs.append(max_var)
if 'min' in op.attributes: op.attributes.pop('min')
if 'max' in op.attributes: op.attributes.pop('max')Pad算子
onnx中的pad算子类比torch中的padding,给定一个包含要填充的数据(data)的张量,一个包含轴(pad)的起始和结束pad值的数量的张量,(可选)一个模式,以及(可选)常量值,生成一个填充的张量(输出)。
这个算子的具体用法请看官方手册:onnx/Operators.md at main · onnx/onnx · GitHub
同CLIP算子,这里预处理依旧是统一格式,不再赘述。
resize算子
做了个版本兼容,不赘述。
Identity算子
不知道为什么要移除Identity算子,其实我不太懂Identity算子的具体作用,在python里是用于做身份校验的,但是onnx的官方手册描述并不清晰?
官方手册描述:https://github.com/onnx/onnx/blob/main/docs/Operators.md#identity
分裂参数变量
将所有参数变量进行分裂(只允许一个 dest_op )
如果有变量的并且dest_ops大于一的话,那么新建一个op,将其分裂。
def format_parameter(self) -> None:
""" Split parameter that has more than 1 dest ops """
for var in [_ for _ in self.graph.variables.values()]:
if var.is_parameter and len(var.dest_ops) > 1:
for op in var.dest_ops:
created = self.graph.create_variable(
value=var.value.clone(), is_parameter=True)
op.inputs[op.inputs.index(var)] = created
created.dest_ops.append(op)
var.dest_ops.clear()
self.graph.remove_variable(var)后记
废了九牛二虎之力终于讲完了计算图的解析与预处理,可以类比AI编译器中的前端处理。但是最精彩的计算图切割和调度还没讲,咱们下期见!
参考
以上是关于OpenPPL PPQ量化:量化计算图的加载和预处理 源码剖析的主要内容,如果未能解决你的问题,请参考以下文章