如何使用ChatGPT API训练具有自定义知识库的AI聊天机器人
Posted BOTAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用ChatGPT API训练具有自定义知识库的AI聊天机器人相关的知识,希望对你有一定的参考价值。
在我们之前的文章中,我们演示了如何使用 ChatGPT API 构建 AI 聊天机器人,并分配一个角色来对其进行个性化设置。但是,如果您想根据自己的数据训练 AI,该怎么办?例如,您可能有一本书、财务数据或大量数据库,并且您希望轻松搜索它们。在本文中,我们为您带来了一个易于遵循的教程,介绍如何使用 LangChain 和 ChatGPT API 使用自定义知识库训练 AI 聊天机器人。我们正在部署LangChain,GPT Index和其他强大的库,以使用OpenAI的大型语言模型(LLM)训练AI聊天机器人。因此,让我们看看如何使用您自己的数据集训练和创建 AI 聊天机器人。
使用 ChatGPT API、LangChain 和 GPT 索引使用自定义知识库训练 AI 聊天机器人 (2023)
在本文中,我们更详细地解释了使用您自己的数据教授 AI 聊天机器人的步骤。从设置工具和软件到训练AI模型,我们以易于理解的语言包含了所有说明。强烈建议从上到下按照说明进行操作,不要跳过任何部分。
注意:本教程已于 6 月 <> 日更新,修复了错误。现在,运行代码时不应收到“BaseGPTIndex”或“llm_predictor”错误。
使用自己的数据训练 AI 之前的注意事项
1. 您可以在任何平台上训练 AI 聊天机器人,无论是 Windows、macOS、Linux 还是 ChromeOS。在本文中,我使用的是 Windows 11,但其他平台的步骤几乎相同。
2.本指南面向一般用户,说明用简单的语言进行说明。因此,即使您对计算机有粗略的了解并且不知道如何编码,您也可以在几分钟内轻松训练和创建Q&A AI聊天机器人。如果您关注我们之前的 ChatGPT 机器人文章,那么理解该过程会更容易。
3. 由于我们将根据自己的数据训练 AI 聊天机器人,因此建议使用具有良好 CPU 和 GPU 的功能强大的计算机。但是,您可以使用任何低端计算机进行测试,并且它可以正常工作。我使用Chromebook使用一本100页(~100MB)的书来训练AI模型。但是,如果要训练运行到数千页的大量数据,强烈建议使用功能强大的计算机。
4. 最后,数据集应该是英文的,以获得最佳结果,但根据 OpenAI 的说法,它也适用于流行的国际语言,如法语、西班牙语、德语等。因此,请继续尝试用您自己的语言进行尝试。
设置软件环境以训练 AI 聊天机器人
像我们上一篇文章一样,你应该知道Python和Pip必须与几个库一起安装。在本文中,我们将从头开始设置所有内容,以便新用户也可以了解设置过程。为了给你一个简短的想法,我们将安装Python和Pip。之后,我们将安装Python库,其中包括OpenAI,GPT Index,Gradio和PyPDF2。在此过程中,您将了解每个库的功能。同样,不要担心安装过程,这非常简单。关于这一点,让我们直接进入。
安装蟒蛇
1.首先,您需要在计算机上安装Python(Pip)。打开此链接并下载适用于您的平台的安装文件。
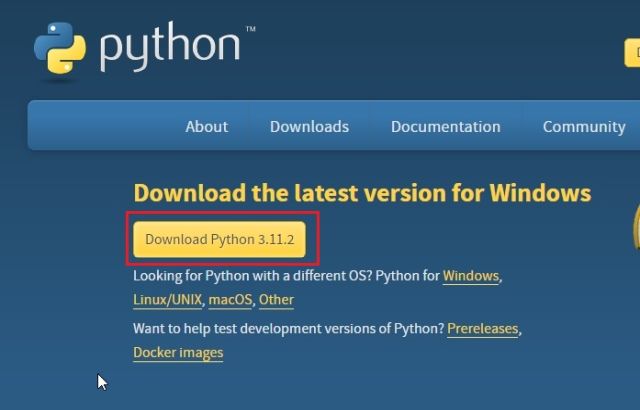
2. 接下来,运行安装文件并确保启用“将 Python.exe 添加到 PATH 复选框。这是极其重要的一步。之后,单击“立即安装”并按照常规步骤安装 Python。
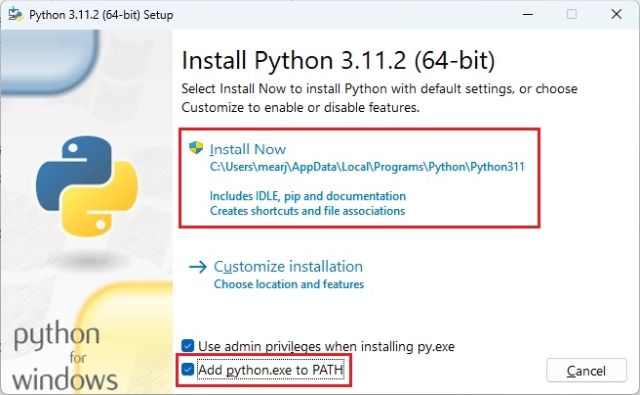
3. 要检查 Python 是否正确安装,请打开计算机上的终端。我在Windows上使用Windows终端,但您也可以使用命令提示符。到达此处后,运行以下命令,它将输出 Python 版本。在 Linux 和 macOS 上,您可能必须使用 python3 --version 而不是 .python --version
python --version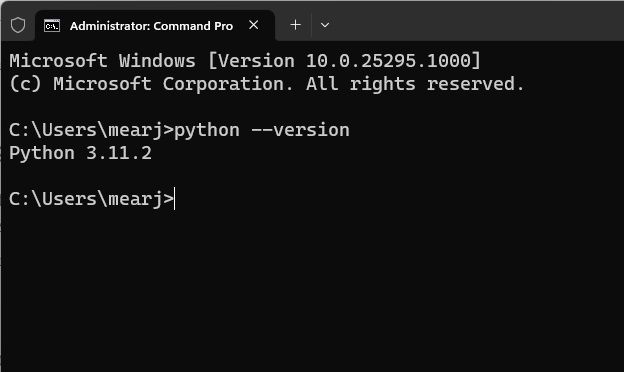
升级点
当你安装Python时,Pip同时安装在你的系统上。因此,让我们将其升级到最新版本。对于那些不知道的人,Pip是Python的包管理器。基本上,它允许您从终端安装数千个 Python 库。使用 Pip,我们可以安装 OpenAI、gpt_index、gradio 和 PyPDF2 库。以下是要遵循的步骤。
1. 在计算机上打开您选择的终端。我使用的是Windows终端,但您也可以使用命令提示符。现在,运行以下命令以更新 Pip。同样,您可能必须在Linux和macOS上使用和。python3pip3
python -m pip install -U pip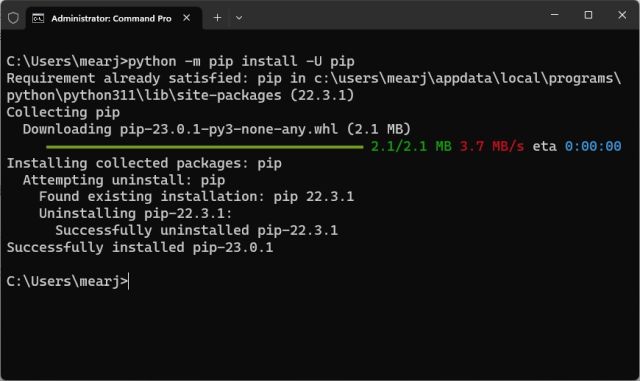
2. 要检查 Pip 是否已正确安装,请运行以下命令。它将输出版本号。如果您遇到任何错误,请按照我们的专用指南了解如何在Windows上安装Pip以修复与PATH相关的问题。
pip --version
安装 OpenAI、GPT Index、PyPDF2 和 Gradio 库
一旦我们设置了Python和Pip,就该安装必要的库了,这些库将帮助我们训练具有自定义知识库的AI聊天机器人。以下是要遵循的步骤。
1. 打开终端并运行以下命令以安装 OpenAI 库。我们将使用它作为LLM(大语言模型)来训练和创建AI聊天机器人。我们还将从OpenAI导入LangChain框架。请注意,Linux 和 macOS 用户可能必须使用 pip3而不是 pip
pip install openai
2. 接下来,让我们安装 GPT 索引,也称为骆驼索引。它允许LLM连接到作为我们知识库的外部数据。在这里,我们正在安装与下面的代码兼容的旧版本的gpt_index。这将确保您在运行代码时不会收到任何错误。如果您已经安装了gpt_index,请再次运行以下命令,它将覆盖最新的命令。
pip install gpt_index==0.4.24
3. 之后,安装 PyPDF2 来解析 PDF 文件。如果您想以PDF格式提供数据,此库将帮助程序轻松读取数据。除此之外,通过运行以下命令安装PyCryptodome。再次这样做是为了避免在解析PDF文件时出现任何错误。
pip install PyPDF2
pip install PyCryptodome4. 最后,安装 Gradio 库。这是为了创建一个简单的 UI 来与训练有素的 AI 聊天机器人进行交互。我们现在已经完成了训练 AI 聊天机器人所需的所有库的安装。
pip install gradio
下载代码编辑器
最后,我们需要一个代码编辑器来编辑一些代码。在Windows上,我会推荐Notepad++。只需通过随附的链接下载并安装程序即可。如果您熟悉功能强大的 IDE,也可以在任何平台上使用 VS Code。除了VS Code,您还可以在macOS和Linux上安装Sublime Text(下载)。
对于ChromeOS,您可以使用出色的插入符号应用程序(下载)来编辑代码。我们几乎完成了软件环境的设置,是时候获取OpenAI API密钥了。
免费获取 OpenAI API 密钥
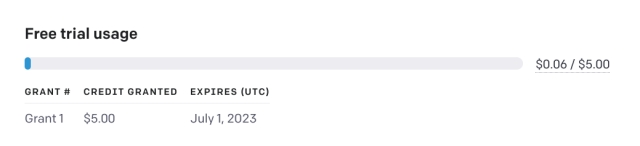
现在,要基于自定义知识库训练和创建AI聊天机器人,我们需要从OpenAI获取API密钥。API密钥将允许您使用OpenAI的模型作为LLM来研究您的自定义数据并得出推论。目前,OpenAI正在向新用户提供免费API密钥,前三个月有价值5美元的免费信用额度。如果您之前创建了 OpenAI 帐户,您的帐户中可能有 18 美元的免费信用额度。免费信用额度用完后,您将需要支付 API 访问权限。但就目前而言,所有用户都可以免费使用它。
1.前往 platform.openai.com/signup 并创建一个免费帐户。如果您已经有一个OpenAI帐户,只需登录即可。
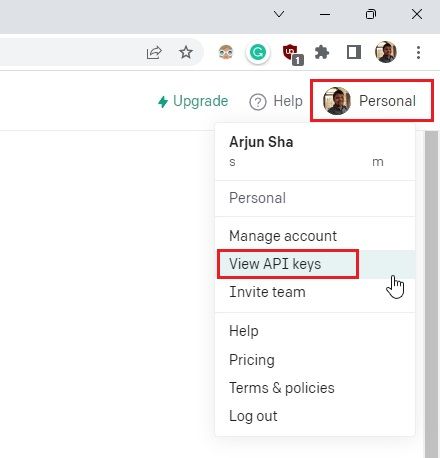
2. 接下来,单击右上角的个人资料,然后从下拉菜单中选择“查看 API 密钥”。
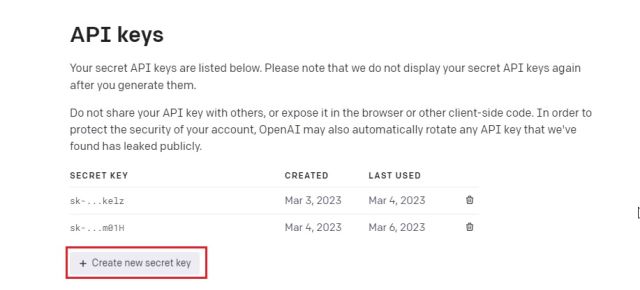
3.在这里,单击“创建新的密钥”并复制API密钥。请注意,以后无法复制或查看整个 API 密钥。因此,强烈建议立即将 API 密钥复制并粘贴到记事本文件中。
4.接下来,转到 platform.openai.com/account/usage 并检查您是否有足够的信用额度。如果您已经用尽了所有免费信用额度,则可以从此处购买OpenAI API。如果您想获得更多免费积分,您可以使用新的手机号码创建一个新的 OpenAI 帐户并获得免费的 API 访问权限(最高价值 5 美元的免费代币)。这将防止您在运行代码时遇到错误 429(您超出了当前配额,请检查您的计划和计费详细信息)。
5. 最后,不要公开分享或展示 API 密钥。这是一个私钥,仅用于访问您的帐户。您还可以删除 API 密钥并创建多个私钥(最多五个)。
使用自定义知识库训练和创建 AI 聊天机器人
现在我们已经设置了软件环境并从 OpenAI 获取了 API 密钥,让我们训练 AI 聊天机器人。在这里,我们将使用“gpt-3.5-turbo”模型,因为它比其他模型更便宜、更快。如果您想使用最新的“gpt-4”模型,您必须有权访问 GPT 4 API,您可以通过在此处加入候补名单获得该 API。有了这些,让我们跳到说明。
添加文档以训练 AI 聊天机器人
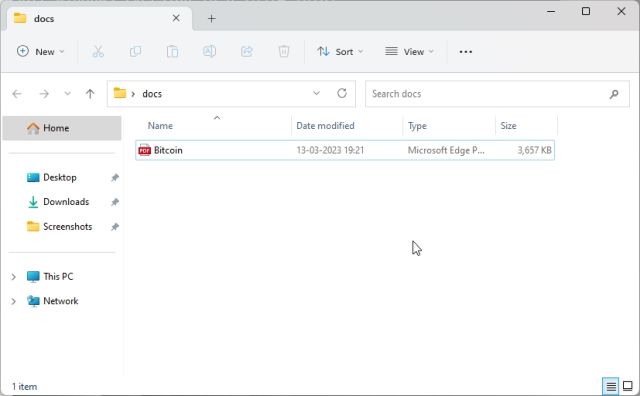
1. 首先,在桌面等可访问位置创建一个名为 docs 的新文件夹。您也可以根据自己的喜好选择其他位置。但是,请保留文件夹名称。

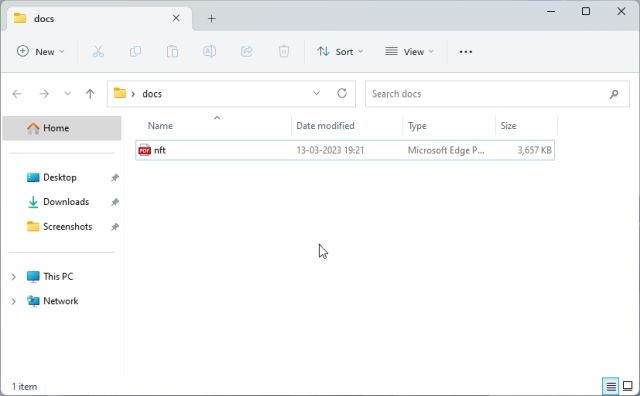
2. 接下来,将您希望用于训练 AI 的文档移动到“文档”文件夹中。您可以添加多个文本或PDF文件(甚至是扫描的文件)。如果您在Excel中有一个大表格,则可以将其导入为CSV或PDF文件,然后将其添加到“docs”文件夹中。您甚至可以添加SQL数据库文件,如此Langchain AI推文中所述。除了上述文件格式之外,我没有尝试过很多文件格式,但您可以自己添加和检查。对于这篇文章,我添加了一篇关于 PDF 格式的 NFT 的文章。
注意:如果您有大型文档,则处理数据需要更长的时间,具体取决于您的 CPU 和 GPU。此外,它将快速使用您的免费 OpenAI 代币。因此,一开始,从一个小文档(30-50 页或 < 100MB 文件)开始了解该过程。
使代码准备就绪
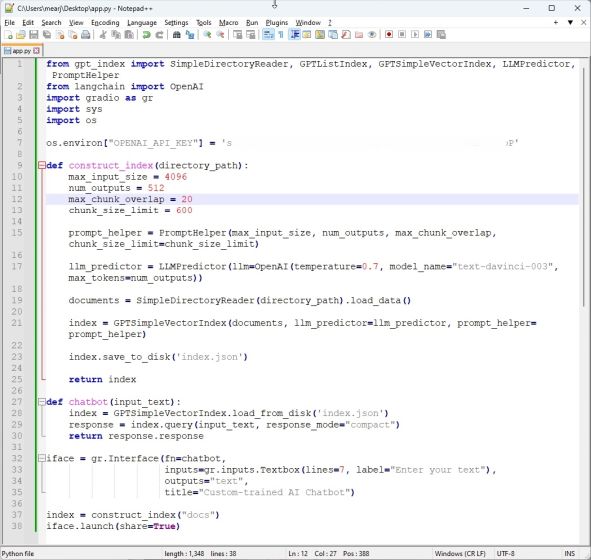
1.现在,启动Notepad++(或您选择的代码编辑器)并将以下代码粘贴到新文件中。再一次,我从Google Colab上的armrrs中得到了很大的帮助,并调整了代码,使其与PDF文件兼容,并在顶部创建了一个Gradio界面。
from gpt_index import SimpleDirectoryReader, GPTListIndex, GPTSimpleVectorIndex, LLMPredictor, PromptHelper
from langchain.chat_models import ChatOpenAI
import gradio as gr
import sys
import os
os.environ["OPENAI_API_KEY"] = \'Your API Key\'
def construct_index(directory_path):
max_input_size = 4096
num_outputs = 512
max_chunk_overlap = 20
chunk_size_limit = 600
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0.7, model_name="gpt-3.5-turbo", max_tokens=num_outputs))
documents = SimpleDirectoryReader(directory_path).load_data()
index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index.save_to_disk(\'index.json\')
return index
def chatbot(input_text):
index = GPTSimpleVectorIndex.load_from_disk(\'index.json\')
response = index.query(input_text, response_mode="compact")
return response.response
iface = gr.Interface(fn=chatbot,
inputs=gr.components.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Custom-trained AI Chatbot")
index = construct_index("docs")
iface.launch(share=True)2. 这是代码编辑器中代码的外观。
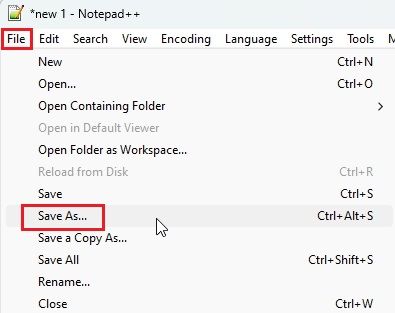
3.接下来,单击顶部菜单中的“文件”,然后从下拉菜单中选择“另存为...”。
4.之后,设置文件名并从下拉菜单中将“保存类型”更改为“所有类型”。然后,将文件保存到您创建“docs”文件夹的位置(在我的情况下,它是桌面)。您可以根据自己的喜好更改名称,但请确保附加。app.py.py
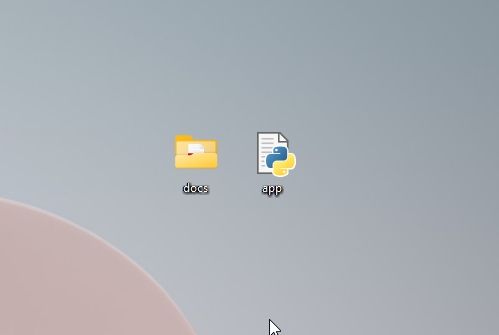
5.确保“docs”文件夹和“app.py”位于同一位置,如下面的屏幕截图所示。“app.py”文件将位于“docs”文件夹之外,而不是内部。
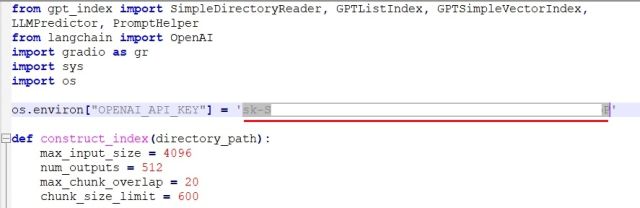
6. 再次回到记事本++中的代码。在这里,替换为上面OpenAI网站上生成的那个。Your API Key
7.最后,按“Ctrl + S”保存代码。现在可以运行代码了。
使用自定义知识库创建聊天 AI 机器人
1.首先,打开终端并运行以下命令以移至桌面。这是我保存“docs”文件夹和“app.py”文件的地方。如果您将这两个项目保存在另一个位置,请通过终端移动到该位置。
cd Desktop
2.现在,运行以下命令。Linux 和 macOS 用户可能必须使用 .python3
python app.py
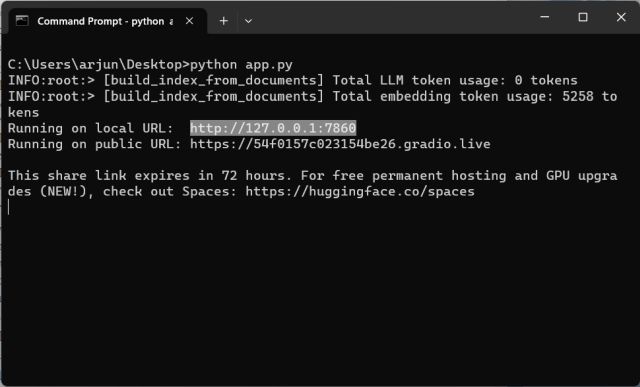
3.现在,它将开始使用OpenAI LLM模型分析文档并开始索引信息。根据文件大小和计算机的功能,处理文档需要一些时间。完成后,将在桌面上创建一个“index.json”文件。如果终端没有显示任何输出,请不要担心,它可能仍在处理数据。供您参考,处理 10MB 文档大约需要 30 秒。
4.LLM处理完数据后,您将找到一个本地URL。复制它。
5.现在,将复制的URL粘贴到Web浏览器中,就可以了。您经过定制训练的 ChatGPT 驱动的 AI 聊天机器人已准备就绪。首先,您可以询问AI聊天机器人该文档的内容。
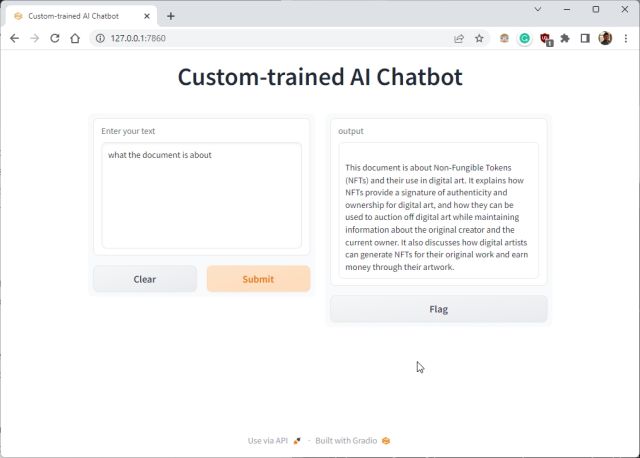
6. 您可以提出进一步的问题,ChatGPT 机器人将根据您提供给 AI 的数据进行回答。因此,这就是您可以使用自己的数据集构建定制训练的AI聊天机器人的方法。您现在可以根据所需的任何类型的信息训练和创建 AI 聊天机器人。可能性是无穷无尽的。
7.您还可以复制公共URL并与您的朋友和家人共享。该链接将持续 72 小时,但您还需要保持计算机处于打开状态,因为服务器实例正在您的计算机上运行。
8. 要停止自定义训练的 AI 聊天机器人,请在终端窗口中按“Ctrl + C”。如果不起作用,请再次按“Ctrl + C”。
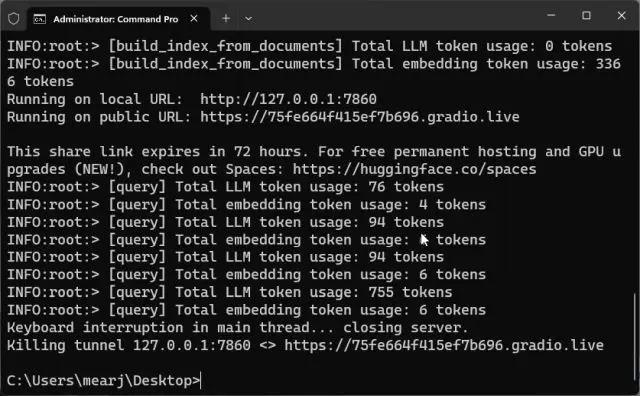
9. 要重新启动 AI 聊天机器人服务器,只需再次移动到桌面位置并运行以下命令。请记住,本地 URL 将是相同的,但公共 URL 将在每次服务器重新启动后更改。
python app.py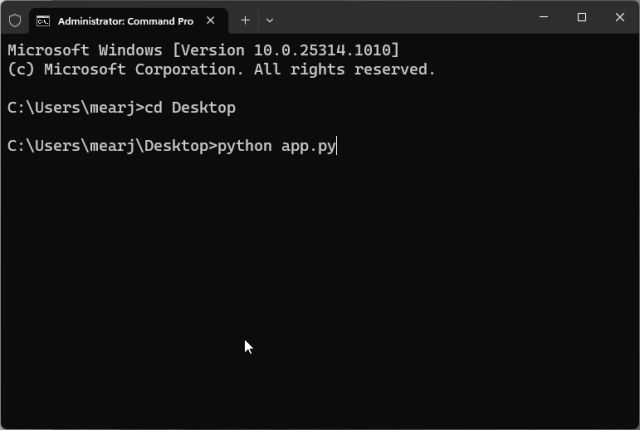
10. 如果您想使用新数据训练 AI 聊天机器人,请删除“docs”文件夹中的文件并添加新文件。您也可以添加多个文件,但请确保提供干净的数据以获得一致的响应。
11. 现在,在终端中再次运行代码,它将创建一个新的“index.json”文件。在这里,旧的“index.json”文件将被自动替换。
python app.py
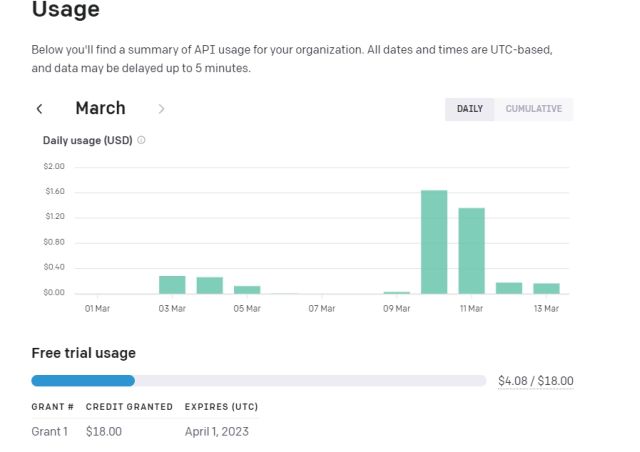
12. 要跟踪您的代币,请前往 OpenAI 的在线仪表板并检查还剩下多少免费信用。
13. 最后,除非您想更改 API 密钥或 OpenAI 模型以进行进一步自定义,否则您无需触摸代码。
使用您自己的数据构建自定义 AI 聊天机器人
因此,这就是使用自定义知识库训练AI聊天机器人的方法。我用这段代码在医学书籍、文章、数据表和旧档案报告中训练人工智能,而且它完美无缺。因此,继续使用OpenAI的大型语言模型和ChatGPY创建自己的AI聊天机器人。无论如何,这都是来自我们的。
本文来自博客园,作者微信:165501809,转载请注明原文链接:https://www.cnblogs.com/botai/p/Train-AI-With-CustomKnowledge.html
开发自己私有chatGPT训练微调openai模型
微调
了解如何为应用程序自定义模型。
介绍
通过微调,您可以通过提供以下内容从通过 API 提供的模型中获得更多收益:
- 比提示设计更高质量的结果
- 能够训练比提示所能容纳的更多示例
- 由于提示时间较短,可以节省token
- 更低的延迟请求
GPT-3 已经对来自开放互联网的大量文本进行了预训练。当给出一个只有几个例子的提示时,它通常可以直观地判断你正在尝试执行什么任务并生成一个合理的完成。这通常被称为“少镜头学习”。
微调通过训练比提示所能容纳的更多的示例来改进少数镜头学习,让您在大量任务上获得更好的结果。对模型进行微调后,无需再在提示中提供示例。这样可以节省成本并实现更低的延迟请求。
概括地说,微调涉及以下步骤:
- 准备和上传训练数据
- 训练新的微调模型
- 使用微调模型
请访问我们的定价页面,详细了解如何对微调的模型训练和使用计费。
哪些模型可以微调?
微调目前仅适用于以下基本型号:davinci curie babbage ada text-davinci-003。
安装
我们建议使用我们的 OpenAI 命令行界面 (CLI)。要安装它,请运行
pip install --upgrade openai
(以下说明适用于版本 0.9.4 及更高版本。此外,OpenAI CLI 需要 python 3。
通过在 shell 初始化脚本(例如 .bashrc、zshrc 等)中添加以下行或在微调命令之前的命令行中运行它来设置环境变量:OPENAI_API_KEY
准备训练数据
训练数据是你教 GPT-3去说。
您的数据必须是 JSONL 文档,其中每行都是对应于训练示例的一对提示完成。您可以使用我们的 CLI 数据准备工具轻松地将数据转换为此文件格式。
"prompt": "<prompt text>", "completion": "<ideal generated text>"
"prompt": "<prompt text>", "completion": "<ideal generated text>"
"prompt": "<prompt text>", "completion": "<ideal generated text>"
...
CLI 数据准备工具
我们开发了一个工具来验证、提供建议和重新格式化您的数据:
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
此工具接受不同的格式文件,唯一要求它们包含提示和完成列/键。您可以传递 CSV、TSV、XLSX、JSON 或 JSONL 文件,它会在指导您完成建议的更改过程后,将输出保存到 JSONL 文件中,以便进行微调。
创建微调模型
以下假设你已按照上述说明准备了训练数据。
使用 OpenAI CLI 启动微调作业:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
BASE_MODEL是基础模型的名称(ada, babbage, curie, davinci)。您可以使用后缀参数自定义你的微调模型的名称。
运行上述命令会执行以下几项操作:
- 使用文件 API 上传文件(或使用已上传的文件)
- 创建微调作业
- 流式传输事件,直到作业完成(这通常需要几分钟,但如果队列中有许多作业或数据集很大,则可能需要数小时)
每个微调作业都从基础模型开始,默认是curie。模型的选择会影响模型的性能和运行微调模型的成本。
开始微调作业后,可能需要一些时间才能完成。你的作业可能排在我们系统上的其他作业后面,训练我们的模型可能需要几分钟或几小时,具体取决于模型和数据集大小。如果事件流因任何原因中断,您可以通过运行以下命令来恢复它:
openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>
作业完成后,它会显示微调模型的名称。
除了创建微调作业之外,您还可以列出现有作业、检索作业状态或取消作业。
# List all created fine-tunes
openai api fine_tunes.list
# Retrieve the state of a fine-tune. The resulting object includes
# job status (which can be one of pending, running, succeeded, or failed)
# and other information
openai api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID>
# Cancel a job
openai api fine_tunes.cancel -i <YOUR_FINE_TUNE_JOB_ID>
使用微调模型
OpenAI CLI:
openai api completions.create -m <FINE_TUNED_MODEL> -p <YOUR_PROMPT>
curl
curl https://api.openai.com/v1/completions \\
-H "Authorization: Bearer $OPENAI_API_KEY" \\
-H "Content-Type: application/json" \\
-d '"prompt": YOUR_PROMPT, "model": FINE_TUNED_MODEL'
Python:
import openai
openai.Completion.create(
model=FINE_TUNED_MODEL,
prompt=YOUR_PROMPT)
Node.js
const response = await openai.createCompletion(
model: FINE_TUNED_MODEL
prompt: YOUR_PROMPT,
);
以上是关于如何使用ChatGPT API训练具有自定义知识库的AI聊天机器人的主要内容,如果未能解决你的问题,请参考以下文章
新知chatGPT 使用笔记——chatGPT API的使用
如何在 Asp.NET Core WEB API 中使用 .Net (C#) 在 Payload 中创建具有自定义 JSON 声明的 JWT 令牌