王心凌彩虹的微笑是不是抄袭断背山中的某个插曲?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了王心凌彩虹的微笑是不是抄袭断背山中的某个插曲?相关的知识,希望对你有一定的参考价值。
看断背山的时候蓦然发现,Ennis和那个酒吧女郎跳舞时的音乐和王心凌彩虹的微笑一模一样,我无法想象美国那个年代的歌手抄袭王心凌的歌,即使Ang Lee除了纰漏,BBM也是2005年的事了。特此请教
如果可以的话,请提供此插曲下载地址,本人将感激不尽。
英文原版:
It's so easy(如此容易)
歌手:Linda Ronstadt
专辑:断臂山电影原声带
下载——
http://www.kavadream.com/file/music/Brokeback_Mountain/14.mp3
歌词:
It's so easy to fall in love
It's so easy to fall in love
People tell me love's for fools
Here I go breaking all the rules
Seems so easy
Yeah, so doggone easy
Oh it seems so easy
Yeah where you're concerned
My heart can learn
It's so easy to fall in love
It's so easy to fall in love
Look into your heart and see
What your lovebook has set aside for me
It seems so easy
Yeah, so doggone easy
Oh it seems so easy
Yeah where you're concerned
My heart can learn
Oh it's so easy to fall in love
It's so easy to fall in love
It seems so easy
Oh so doggone easy
Yeah it seems so easy
Oh where you're concerned
My heart can learn
Oh it's so easy to fall in love
It's so easy to fall in love
It's so easy to fall in love
It's so easy to fall in love
It's so easy to fall in love
Oh-ooh It's so easy to fall in love
参考资料:http://zhidao.baidu.com/question/38535695.html?si=2
本回答被提问者采纳 参考技术B Cyndi的彩虹的微笑原本就是翻唱啊 参考技术C 王心凌彩虹的微笑是否抄袭断背山中的某个插曲?美国那个年代的歌手抄袭王心凌的歌?
你说得有点问题啊?到底是谁抄袭谁啊!?
王心凌的「爱你」,我们用Python跳起来,这是“中年男粉”的实力
前言
最近着实被唤起当年的青葱回忆了,回忆的同时当然也不会忘记给大家整个趣味小例子,今天我们就整一个王心凌字符画吧~

字符画:字符画是一系列字符的组合,我们可以把字符看作是比较大块的像素,一个字符能表现一种颜色,字符的种类越多,可以表现的颜色也越多,图片也会更有层次感。如果我们想要手工绘制出字符画,首先要有扎实的美术基础,其次还要花费大量的时间和精力。但是我们可以使用Python,只需要几行代码,就能够将一张图片轻而易举地转化为一个字符画。
工具准备
- 开发工具:pycharm
- 开发环境:python3.7, Windows10
- 使用工具包:PIL, cv2, numpy
项目效果展示

项目思路解析
首先我们先将这个项目思路进行明确定位,把我们甜心教主的视频转换成字符画的视频,首先自备一段教主的视频,在将视频进行拆分,拆分成一张张单独的图片,因为我们转成字符画其实本质上就是转化成图片数据。
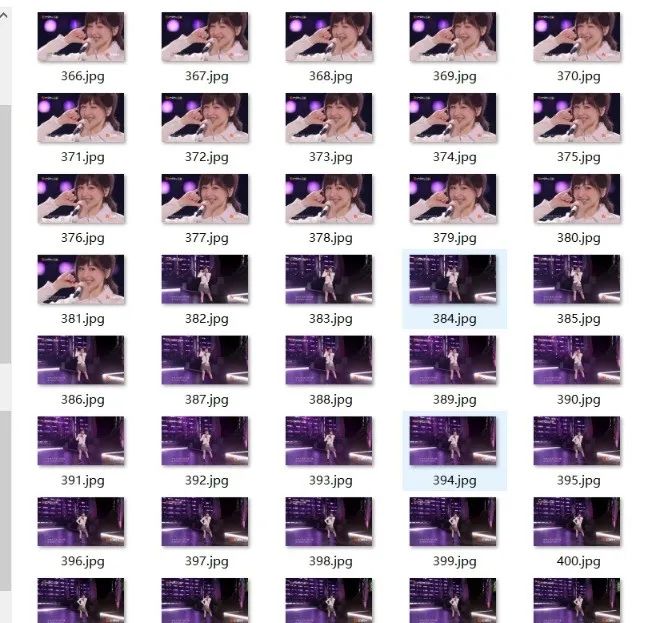
然后在对每一张图片进行灰度处理,我们做个相对来说简单一点的,灰度数据的话只有黑白,颜色更好把控,把图片数据转化成一个数组,通过k聚类算法把图像进行聚类划分,在将划分的图片数组根据亮度情况进行替换,根据亮度情况亮一点的用数字,稍稍暗一点的用1,白的用空白,将视频里的图片数据进行全部替换,在将替换好的图片组合成一个视频
第一步视频拆分成视频
首先使用cv2.VideoCapture进行视频进行抽帧,将抽帧好的图片使用read方式进行读取,把读取好的数据保存在文件夹里,使用数字来保存图片名,也方便我们在之后进行提取图片数据进行使用
将视频转换为图片 并进行计数,返回总共生成了多少张图片!
def video_to_pic(vp):
# vp = cv2.VideoCapture(video_path)
number = 0
if vp.isOpened():
r, frame = vp.read()
if not os.path.exists('cache_pic'):
os.mkdir('cache_pic')
os.chdir('cache_pic')
else:
r = False
while r:
number += 1
cv2.imwrite(str(number) + '.jpg', frame)
r, frame = vp.read()
print('\\n由视频一共生成了张图片!'.format(number))
os.chdir("..")
return number
将图片转换字符画
循环取出文件夹里面所有的图片数据进行转换,首先通过cv2进行图片读取,获取到他的图片数据通道,获取到图片数据的3通道rgb的数据信息,在将数据进行灰度处理,我们需要用他的颜色用来区分他的数据样式,所以只能灰度来实现,在使用numpy进行数据转换,将获取到的矩阵数据进行降维,转换成一个类似列表的数据信息,使用kmeans算法对图像数据进行分类,设置他的矩阵中心数,最大迭代数,以及试错等级,k聚类算法可以自行了解,会给我们返回labels(类别)、centroids(矩心) compactness(密度值),将矩心进行数据转换成整数,我们可以更好的替换符号,对矩心进行排序,矩心大的说明颜色越暗,矩心小的越淡,在根据亮度数据将数据进行替换成一个新的画布,将我们的符号替换到画布上去,到这里我们就能吧单独的图片替换成字符画了
def img2strimg(frame, K=3):
# 读取矩阵的长度 有时返回两个值,有时三个值
height, width, *_ = frame.shape
# print(frame.shape)
# 颜色空间转化 图片对象, 灰度处理
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# print(frame_gray)
# 转换数据类型,将数据降维
frame_array = np.float32(frame_gray.reshape(-1))
# print(frame_array)
# 得到labels(类别)、centroids(矩心) compactness(密度值)。
# 如第一行6个像素labels=[0,2,2,1,2,0],则意味着6个像素分别对应着 第1个矩心、第3个矩心、第3、2、3、1个矩心。
compactness, labels, centroids = cv2.kmeans(frame_array, K, None, (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0), 10, cv2.KMEANS_RANDOM_CENTERS)
print(labels)
centroids = np.uint8(centroids) # 转换成整形
# labels的数个矩心以随机顺序排列,所以需要简单处理矩心.
# 返回一个折叠成一维的数组
centroids = centroids.flatten()
# 排序
centroids_sorted = sorted(centroids)
# 获得不同centroids的明暗程度,0最暗
centroids_index = np.array([centroids_sorted.index(value) for value in centroids])
# 亮度设置
bright = [abs((3 * i - 2 * K) / (3 * K)) for i in range(1, 1 + K)]
bright_bound = bright.index(np.min(bright))
# 背景阴影设置
shadow = [abs((3 * i - K) / (3 * K)) for i in range(1, 1 + K)]
shadow_bound = shadow.index(np.min(shadow))
# 返回一个折叠成一维的数组
labels = labels.flatten()
print(labels)
# 将labels转变为实际的明暗程度列表,0最暗。
labels = centroids_index[labels]
print(labels)
# 列表解析,每2*2个像素挑选出一个,组成(height*width*灰)数组。
labels_picked = [labels[rows * width:(rows + 1) * width:2] for rows in range(0, height, 2)]
canvas = np.zeros((3 * height, 3 * width, 3), np.uint8)
canvas.fill(255) # 创建长宽为原图三倍的白色画布。
# 因为 字体大小为0.45时,每个数字占6*6个像素,而白底画布为原图三倍
# 所以 需要原图中每2*2个像素中挑取一个,在白底画布中由6*6像素大小的数字表示这个像素信息。
y = 0
for rows in labels_picked:
x = 0
for cols in rows:
if cols <= shadow_bound:
# 添加文字 图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细
cv2.putText(canvas, str(random.randint(2, 9)), (x, y), cv2.FONT_HERSHEY_PLAIN, 0.45, 0.1)
elif cols <= bright_bound:
cv2.putText(canvas, "-", (x, y),cv2.FONT_HERSHEY_PLAIN, 0.4, 0, 1)
x += 6
y += 6
return canvas
合成视频
将全部的图片数据在进行合成一个新的视频,视频数据尽量不要太大,帧数越细的话,生成的视频越大,可能好几个G
def jpg_to_video(char_image_path, FPS):
video_fourcc = cv2.VideoWriter_fourcc(*"MP42") # 设置视频编码器,这里使用使用MP42编码器,可以生成更小的视频文件
char_img_path_list = [char_image_path + r'/.jpg'.format(i) for i in range(1, number + 1)] # 生成目标字符图片文件的路径列表
char_img_test = Image.open(char_img_path_list[1]).size # 获取图片的分辨率
if not os.path.exists('video'):
os.mkdir('video')
video_writter = cv2.VideoWriter('video/new_char_video.avi', video_fourcc, FPS, char_img_test)
sum = len(char_img_path_list)
count = 0
for image_path in char_img_path_list:
img = cv2.imread(image_path)
video_writter.write(img)
end_str = '100%'
count = count + 1
process_bar(count / sum, start_str='', end_str=end_str, total_length=15)
video_writter.release()
print('\\n')
print('=======================')
print('The video is finished!')
print('=======================')
简易源码分享
# from platypus import
import os
from PIL import Image, ImageFont, ImageDraw
import cv2
import random
import numpy as np
import threading
# 将视频转换为图片 并进行计数,返回总共生成了多少张图片!
def video_to_pic(vp):
# vp = cv2.VideoCapture(video_path)
number = 0
if vp.isOpened():
r, frame = vp.read()
if not os.path.exists('cache_pic'):
os.mkdir('cache_pic')
os.chdir('cache_pic')
else:
r = False
while r:
number += 1
cv2.imwrite(str(number) + '.jpg', frame)
r, frame = vp.read()
print('\\n由视频一共生成了张图片!'.format(number))
os.chdir("..")
return number
def star_to_char(number, save_pic_path):
if not os.path.exists('cache_char'):
os.mkdir('cache_char')
img_path_list = [save_pic_path + r'/.jpg'.format(i) for i in range(1, number + 1)] # 生成目标图片文件的路径列表
task = 0
for image_path in img_path_list:
img_width, img_height = Image.open(image_path).size # 获取图片的分辨率
task += 1
# img_to_char(image_path, img_width, img_height, task)
print('/ is finished.'.format(task, number))
print('=======================')
print('All image was finished!')
print('=======================')
return 0
def img2strimg(frame, K=3):
# 读取矩阵的长度 有时返回两个值,有时三个值
height, width, *_ = frame.shape
# print(frame.shape)
# 颜色空间转化 图片对象, 灰度处理
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# print(frame_gray)
# 转换数据类型,将数据降维
frame_array = np.float32(frame_gray.reshape(-1))
# print(frame_array)
# 得到labels(类别)、centroids(矩心) compactness(密度值)。
# 如第一行6个像素labels=[0,2,2,1,2,0],则意味着6个像素分别对应着 第1个矩心、第3个矩心、第3、2、3、1个矩心。
compactness, labels, centroids = cv2.kmeans(frame_array, K, None, (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0), 10, cv2.KMEANS_RANDOM_CENTERS)
print(labels)
centroids = np.uint8(centroids) # 转换成整形
# labels的数个矩心以随机顺序排列,所以需要简单处理矩心.
# 返回一个折叠成一维的数组
centroids = centroids.flatten()
# 排序
centroids_sorted = sorted(centroids)
# 获得不同centroids的明暗程度,0最暗
centroids_index = np.array([centroids_sorted.index(value) for value in centroids])
# 亮度设置
bright = [abs((3 * i - 2 * K) / (3 * K)) for i in range(1, 1 + K)]
bright_bound = bright.index(np.min(bright))
# 背景阴影设置
shadow = [abs((3 * i - K) / (3 * K)) for i in range(1, 1 + K)]
shadow_bound = shadow.index(np.min(shadow))
# 返回一个折叠成一维的数组
labels = labels.flatten()
print(labels)
# 将labels转变为实际的明暗程度列表,0最暗。
labels = centroids_index[labels]
print(labels)
# 列表解析,每2*2个像素挑选出一个,组成(height*width*灰)数组。
labels_picked = [labels[rows * width:(rows + 1) * width:2] for rows in range(0, height, 2)]
canvas = np.zeros((3 * height, 3 * width, 3), np.uint8)
canvas.fill(255) # 创建长宽为原图三倍的白色画布。
# 因为 字体大小为0.45时,每个数字占6*6个像素,而白底画布为原图三倍
# 所以 需要原图中每2*2个像素中挑取一个,在白底画布中由6*6像素大小的数字表示这个像素信息。
y = 0
for rows in labels_picked:
x = 0
for cols in rows:
if cols <= shadow_bound:
# 添加文字 图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细
cv2.putText(canvas, str(random.randint(2, 9)), (x, y), cv2.FONT_HERSHEY_PLAIN, 0.45, 0.1)
elif cols <= bright_bound:
cv2.putText(canvas, "-", (x, y),cv2.FONT_HERSHEY_PLAIN, 0.4, 0, 1)
x += 6
y += 6
return canvas
def jpg_to_video(char_image_path, FPS):
video_fourcc = cv2.VideoWriter_fourcc(*"MP42") # 设置视频编码器,这里使用使用MP42编码器,可以生成更小的视频文件
char_img_path_list = [char_image_path + r'/.jpg'.format(i) for i in range(1, number + 1)] # 生成目标字符图片文件的路径列表
char_img_test = Image.open(char_img_path_list[1]).size # 获取图片的分辨率
if not os.path.exists('video'):
os.mkdir('video')
video_writter = cv2.VideoWriter('video/new_char_video.avi', video_fourcc, FPS, char_img_test)
sum = len(char_img_path_list)
count = 0
if __name__ == '__main__':
video_path = '王心凌.mp4'
save_pic_path = 'cache_pic'
save_charpic_path = 'cache_char'
vp = cv2.VideoCapture(video_path)
number = video_to_pic(vp)
for i in range(1, number):
fp = r"cache_pic/.jpg".format(i)
img = cv2.imread(fp) # 返回图片数据 (高度, 宽度,通道数)
print(img)
# 若字符画结果不好,可以尝试更改K为3。若依然无法很好地表现原图,请换图尝试。-_-||
str_img = img2strimg(img)
cv2.imwrite("cache_char/.jpg".format(i), str_img)
# number = 1692
# print(number)
FPS = vp.get(cv2.CAP_PROP_FPS)
star_to_char(number, save_pic_path)
jpg_to_video(save_charpic_path, FPS)
有想学习Python的朋友的,给大家分享一份系统的从入门到精通的学习方法!

最后大家一起来说说,当年你们最喜欢王心凌那首歌?欢迎大家在留言区吱一声,常来捧场留言,混个脸熟!
以上是关于王心凌彩虹的微笑是不是抄袭断背山中的某个插曲?的主要内容,如果未能解决你的问题,请参考以下文章