Python3报错处理:UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: o
Posted 诸子流
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3报错处理:UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: o相关的知识,希望对你有一定的参考价值。
一、背景说明
最开始不愿意使用Python,一大原因是因为Python2默认使用ASCII编码处理中文可以说是一件痛苦的事情。仅从更换默认编码一项变换,就可以说Python3和Python2不算同一门语言。
Python3更换为默认使用Unicode(utf-8)编码,一直使用下来再没有遇到编码问题带来的困挠,似乎编码问题在Python3时代就该完全消失的。但这两天遇到了一个问题。
在调用一个库时,出现了一个异常报错类似如UnicodeEncodeError: \'ascii\' codec can\'t encode characters in position 0-1: ordinal not in range(128),几经排查之下发现只要该库返回结果包含中文,我这边使用print()打印该结果时就会出现该异常。
二、原因分析
2.1 数据要经过编码才能传输
我们知道数据在网络上传输时,需要先编码;平时我们可能并不注意,但现在要明确,编码的原因不在于网络而在于传输。
print()相当于把字符串从内存传输到了tty上,所以print()是需要encode()动作的;平时我们print()时一般都不需要encode(),只是因为当print()检测到传来的参数是不是byte类型时自动进行了编码。
2.2 print()使用何种编码
Python3默认使用的是utf-8,这可以通过sys.getdefaultencoding()进行确认。但这只是默认,当系统配置了LC_ALL、LC_CTYPE、LANG等环境变量时(三者优先级从高到低),Python3采用这些变量配置的编码;如果这些变量配置的是utf-8那Python3用的就还是utf-8,但如果不是utf-8那Python3所用的也就不是utf-8了。
当前使用的编码可通过sys.getfilesystemencoding()获取。
三、场景复现
为简单起见,我们这里直接以打印一个中文字符串作为演示,示例代码如下(我这里保存成test_encode.py):
import sys class TestEncode(): def __int__(self): pass def main_logic(self): # 打印语言默认编码 print(f"defaultencoding--{sys.getdefaultencoding()}") # 打印系统配置的编码 print(f"filesystemencoding--{sys.getfilesystemencoding()}") # 最后尝试打印中文 print("中文") if __name__ == "__main__": obj = TestEncode() obj.main_logic()
shell依次执行如下命令:
# 查看当前编码情况 locale # 确认在utf-8情况下打印中文无误 python3 test_encode.py # 设置LC_TYPE,C代表ASCII export LC_CTYPE="C" # 查看当前编码情况 locale # 再次运行,确认系统编码已改变,并出现编码错误 python3 test_encode.py
最终结果如下,在系统编码配置为utf-8时打印正常,在系统编码改为C(即ASCII)后打印报编码异常(不过我在root用户环境修改编码一直不成功,不懂我电脑有点问题还是什么原因):
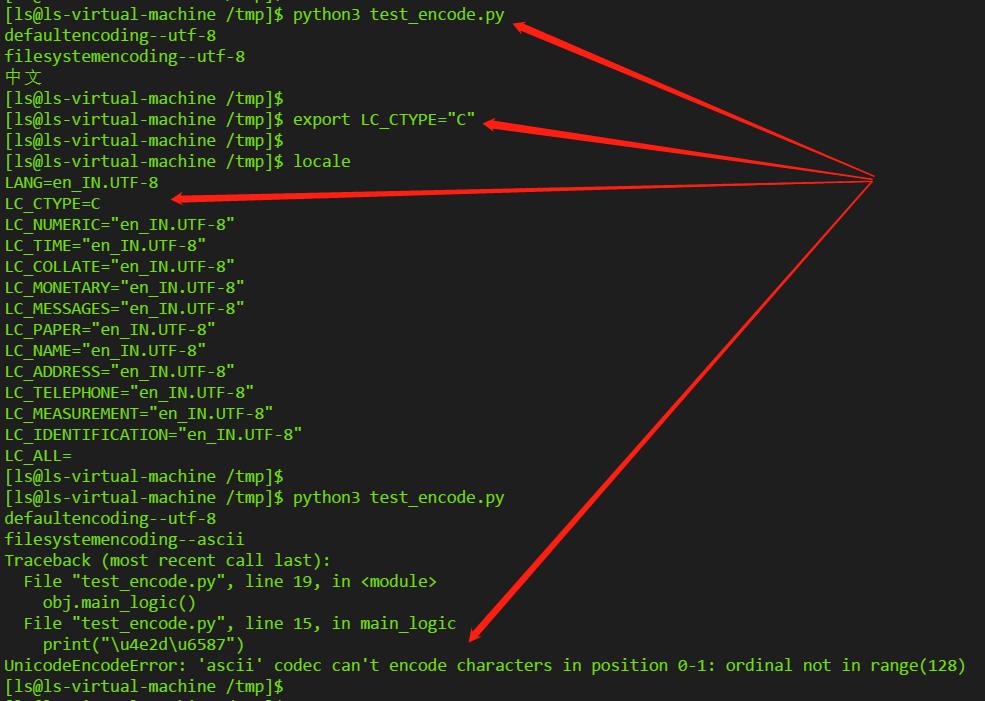
四、解决办法
方法一:设置系统所用编码为utf-8
既然问题是系统语言编码所致,那我们在运行前把LC_ALL等环境变量改为utf-8即可;实现的方式有多种,最简单的就是在运行前export。
export LC_ALL="en_US.utf8"
方法二:使用PYTHONIOENCODING
PYTHONIOENCODING=ascii python test_encode.py
方法三:先编好码再交给print()(不实用?)
其实回顾我们第二大节的分析,之后以需要找系统的编码是因为print()收到未经编码的内容,所以更直接的处理办法是我们先编好码再交给print()就好了。(不过交给print时是byte类型,最后print输出的也是byte类型?)
print("中文".encode(encoding="utf-8"))
方法四:直接在Python中重新设置标准输出编码
这种方法直接在Python代码中改,是与Python最契合的做法,脚本文件形式时特别推荐
import sys import codecs sys.stdout = codecs.getwriter("utf-8")(sys.stdout.detach()) print("中文")
参考:
https://blog.csdn.net/th_num/article/details/80685389
https://timothyqiu.com/archives/surrogateescape-in-python-3/
以上是关于Python3报错处理:UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: o的主要内容,如果未能解决你的问题,请参考以下文章
Python3报错处理:UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: o
ubuntu16.04 pip install scrapy 报错处理
python3.6使用chardet模块总是报错ValueError: Expected a bytes object, not a unicode object