python爬虫处理在线预览的pdf文档
Posted geeker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫处理在线预览的pdf文档相关的知识,希望对你有一定的参考价值。
引言
最近在爬一个网站,然后爬到详情页的时候发现,目标内容是用pdf在线预览的
比如如下网站:
https://camelot-py.readthedocs.io/en/master/_static/pdf/foo.pdf

根据我的分析发现,这样的在线预览pdf的采用了pdfjs加载预览,用爬虫的方法根本无法直接拿到pdf内的内容的,对的,你注意到了我说的【根本无法直接拿到】中的直接两个字,确实直接无法拿到,怎么办呢?只能把pdf先下载到本地,然后用工具转了,经过我查阅大量的相关资料发现,工具还是有很多:
1.借用第三方的pdf转换网站转出来
2.使用Python的包来转:如:pyPdf,pyPdf2,pyPdf4,pdfrw等工具
这些工具在pypi社区一搜一大把:
但是效果怎么样就不知道了,只能一个一个去试了,到后面我终于找到个库,非常符合我的需求的库 ——camelot
camelot可以读取pdf文件中的数据,并且自动转换成pandas库(数据分析相关)里的DataFrame类型,然后可以通过DataFrame转为csv,json,html都行,我的目标要的就是转为html格式,好,废话不多说,开始搞
开始解析
1.安装camelot:
pip install camelot-py
pip install cv2 (因为camelot需要用到这个库)
2.下载pdf:因为在线的pdf其实就是二进制流,所以得按照下载图片和视频的方式下载,然后存到本地的一个文件里,这个步骤就不多说了
3.解析:
import camelot
file = \'temp.pdf\'
table = camelot.read_pdf(file,flavor=\'stream\')
table[0].df.to_html(\'temp.html\')
以上的temp.html就是我希望得到的数据了,然后根据我的分析发现,在read_pdf方法里一定带上参数 【flavor=\'stream\'】,不然的话就报这个错:
RuntimeError: Please make sure that Ghostscript is installed
原因就是,read_pdf默认的flavor参数是lattice,这个模式的话需要安装ghostscript库,然后你需要去下载Python的ghostscript包和ghostscript驱动(跟使用selenium需要下载浏览器驱动一个原理),而默认我们的电脑肯定是没有安装这个驱动的,所以就会报上面那个错。我试着去装了这个驱动和这个包,去read_pdf时其实感觉没有本质区别,是一样的,所以带上参数flavor=\'stream\'即可,当然如果你硬要用lattice模式的话,安装完ghostscript包和ghostscript驱动之后,记得在当前py文件用 【import ghostscript】导入下这个包,不然还是会报如上错误
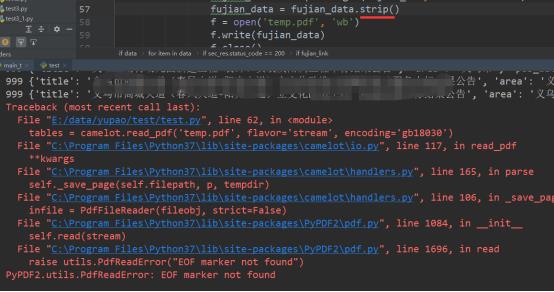
继续走,发现能拿到我想要的数据了,非常nice,然后突然的,报了如下错误:
PyPDF2.utils.PdfReadError: EOF marker not found

当时就是卧槽,这什么情况,我开始去研究EOF marker是什么意思,但是我直接打开这个pdf文件又是正常的

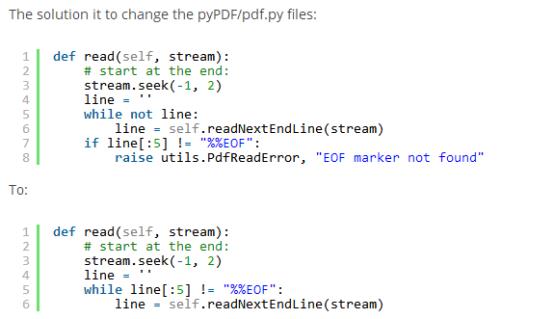
非常诡异,网上查阅了一堆,大概意思就是说,没有EOF结束符,这个东西在之前我做js开发的时候遇到过,js的语句体{},少了最后的【}】,
我又去了解了下EOF到底在二进制文件指的什么,然后看到老外的这个帖子:
我用同样的方法查看数据的前五个字符和后五个字符:

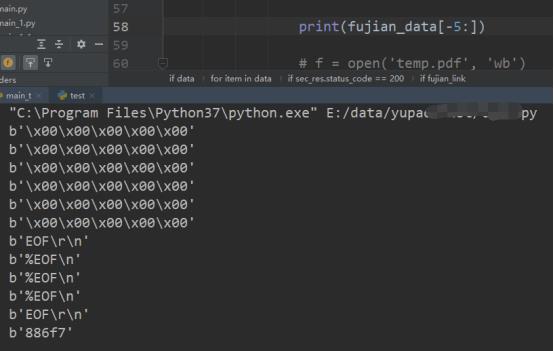
好像有了眉目,我以文本的方式打开了我下载到本地的一个pdf,在%%EOF结尾之后还有很多的null
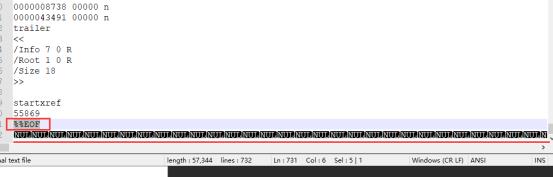
难道是NULL的问题?我手动删掉null之后,单独对这个修改过的pdf用pdf查看器打开,正常打开,没有问题,我接着用代码针对这个文件执行read_pdf,发现非常神奇的不会报错了,那还真是结尾的NULL元素了。
然后我在从网上读取到pdf之后的二进制部分用字符串的strip()方法,以为用strip可以去除那些null,结果发现还是如此
-------------------------------------
那就只有先锁定 %%EOF 所在位置,然后切片操作了,部分代码如下,果然问题解决,但同时又报了一个新的错,这个就是个编码问题了,相信搞爬虫的朋友们对这个问题非常熟悉了
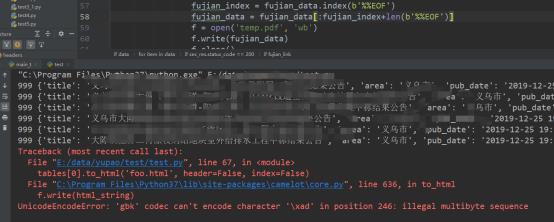
先暂时不管这个问题,我又改了下目标网站的指定页码


pdfminer.psparser.SyntaxError: Invalid dictionary construct: [/\'Type\', /\'Font\', /\'Subtype\', /\'Type0\', /\'BaseFont\', /b"b\'", /"ABCDEE+\\\\xcb\\\\xce\\\\xcc\\\\xe5\'", /\'Encoding\', /\'Identity-H\', /\'DescendantFonts\', <PDFObjRef:11>, /\'ToUnicode\', <PDFObjRef:19>]
发现问题越来越严重了,我鼓捣了一番之后,又查了一堆资料,将utf-8改成gb18030还是报错,我发现我小看这个问题了,接着查阅,然后发现github上camelot包的issues也有人提了这个报错,
https://github.com/atlanhq/camelot/issues/161


然后这里有个人说可以修复下pdf文件:
我查了下,需要安装一个软件mupdf,然后在终端用命令 修复
mutool clean 旧的.pdf 新的.pdf
首先这并不是理想的解决方法,在python代码中,是可以调用终端命令,用os和sys模块就可以,但是万一因为终端出问题还不好找原因,所以我并没有去修复,之后我发现我这个决定是对的
接着看,发现issue里很多人都在反馈这个问题,最后看到这个老哥说的

大概意思就是说pypdf2无法完美的处理中文文档的pdf,而camelot对pdf操作就基于pypdf2,卧槽,这个就难了。
然后我又查到这篇文章有说到这个问题:https://blog.csdn.net/kmesky/article/details/102695520
那只能硬改源码了,改就改吧,毕竟这也不是我第一次改源码了
注意:如果你不知道的情况下,千万不要改源码,这是一个大忌,除非你非常清楚你要做什么
修改源码:
1.format.py
C:\\Program Files\\Python37\\Lib\\site-packages\\pandas\\io\\formats\\format.py该文件的第846行
由这样:

改成这样:
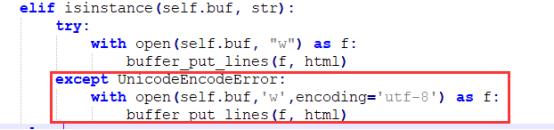
2.generic.py
File "D:\\projects\\myproject\\venv\\lib\\site-packages\\PyPDF2\\generic.py", 该文件的第484行
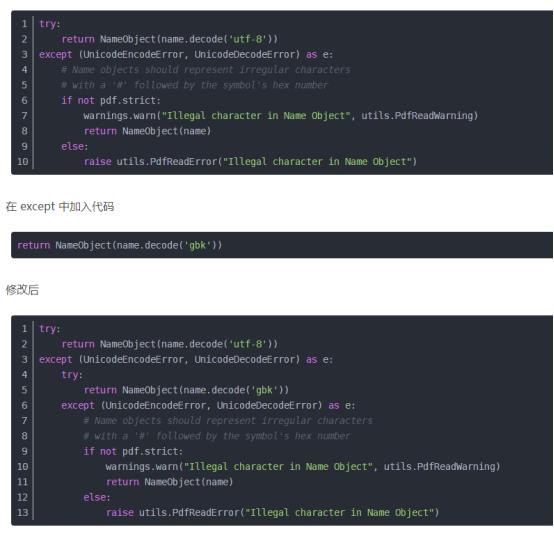
3.utils.py
Lib/site-packages/PyPDF2/utils.py 第238行

4.运行
再运行:之前那些错误已经没有了
但同时又有了一个新的错
其实这个超出索引范围的报错的根本是上面的警告:UserWarning:page-1 is image-based,camelot only works on text-based pages. [streams.py:443]

因为源数据pdf的内容是个图片,不再是文字,而camelot只能以文本形式提取数据,所以数据为空,所以 table[0]会报索引超出范围
针对图片的处理,我网上查阅了一些资料,觉得这篇文章写的不错,可以提取pdf中的图片
https://blog.csdn.net/qq_15969343/article/details/81673302
但是,我的目标是希望拿到pdf中的内容,然后转成html格式,在之前,我已经由在线pdf->本地pdf->提取表格->表格转html,这是第一种。
如果要提取图片的话,那步骤就是第二种:在线pdf->本地pdf->提取图片->ocr提取表格->验证对错->表格转html,这样就会多些步骤,想想,我为了拿到一个网站的数据,每个网页就要做这些操作,而且还要判断是图片就用用第二种,是表格就用第一种,两个方法加起来的话,爬一个网站的数据要做的操作的就多了,虽然这些都属于IO操作型,但是到后期开启多线程,多进程时,与那些直接就能从源网页提取的相比就太耗时间了。
这样不是不行,是真的耗时间,所以我暂时放弃对图片的提取了,只提取table,先对pdf二进制数据判断是否是图片,是图片就跳过了
原理就是,根据上面那片博客里的:

打开二进制源码验证:
第一个,它确实是图片的:


第二个,它是表格:
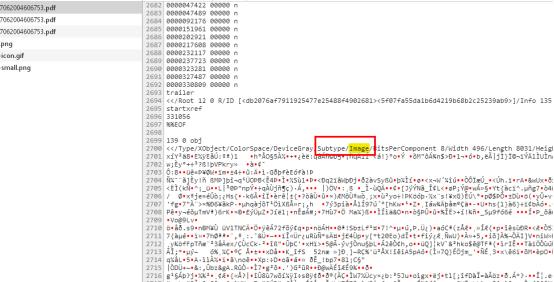
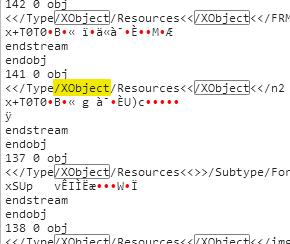
不过经过我的验证,发现这个方法正确率不能百分之百,少部分的即使是表格还是有/Image和/XObject相关的字符串
那没办法了,有多少是多少吧
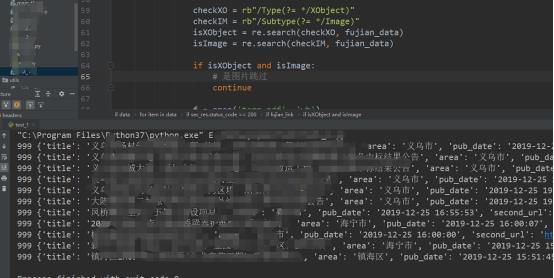
部分代码实现:
fujian_data = requests.get(fujian_url, headers=headers).content
fujian_index = fujian_data.index(b\'%%EOF\')
fujian_data = fujian_data[:fujian_index + len(b\'%%EOF\')]
checkXO = rb"/Type(?= */XObject)"
checkIM = rb"/Subtype(?= */Image)"
isXObject = re.search(checkXO, fujian_data)
isImage = re.search(checkIM, fujian_data)
if isXObject and isImage:
# 是图片跳过
pass
f = open(\'temp.pdf\', \'wb\')
f.write(fujian_data)
f.close()
tables = camelot.read_pdf(\'temp.pdf\', flavor=\'stream\')
if os.path.exists(\'temp.pdf\'):
os.remove(\'temp.pdf\') # 删除本地的pdf
tables[0].df.to_html(\'foo.html\', header=False, index=False)
至此完毕,当然,你也可以用camelot 的to_csv 和 to_json方法转成你希望的,具体就自己研究了
2020年2月14号补充:
以上的方法确实可以处理在线的pdf文档了(非图片式),但是,还有个遗留的问题,就是以上只能处理单页的pdf,如果是多页的pdf还是不行,比如如下,
像这种不止一页的数据的,按以上的方法提取出来的内容是不完整的。
那么怎么办呢?首先得确定这个pdf是多少页对吧,但是目前有没有什么方法来获取pdf的页码呢?我查了下camelot模块的方法,暂时没找到,网上一查,有人说得通过pdfminer模块来操作,然后我修改的代码如下:
import camelot
import requests
import re
import js2py
import execjs
import json
from urllib.parse import urljoin
from lxml.html import tostring
from bs4 import BeautifulSoup
from html import unescape
from lxml import etree
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
import re
def read_pdf_text(filePath):
# 以二进制读模式打开
file = open(filePath, \'rb\')
# 用文件对象来创建一个pdf文档分析器
praser = PDFParser(file)
# 创建一个PDF文档对象存储文档结构,提供密码初始化,没有就不用传该参数
doc = PDFDocument(praser, password=\'\')
# 检查文件是否允许文本提取
if doc.is_extractable:
# 创建PDf 资源管理器 来管理共享资源,#caching = False不缓存
rsrcmgr = PDFResourceManager(caching=False)
# 创建一个PDF设备对象
laparams = LAParams()
# 创建一个PDF页面聚合对象
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解析器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 获取page列表
# 循环遍历列表,每次处理一个page的内容
results = \'\'
for page in PDFPage.create_pages(doc):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
for x in layout:
if hasattr(x, "get_text"):
results += x.get_text()
# 如果x是水平文本对象的话
# if (isinstance(x, LTTextBoxHorizontal)):
# text = re.sub(replace, \'\', x.get_text())
# if len(text) != 0:
# print(text)
if results:
# print(results)
return results
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36\',
}
url =’\' # 保密
data = \'\' # 保密
req = requests.post(url, headers=headers, data=data)
res = req.json()
data = res.get(\'UserArea\').get(\'InfoList\')
for item in data:
current_data = dict()
title = item.get(\'ShowBiaoDuanName\')
link = item.get(\'FilePath\')
pub_date = item.get(\'SHR_Date\')
second_url = re.findall(r"<a href=\'(.*)\'>", link)
if second_url:
second_url = second_url[0]
sec_res = requests.get(second_url, headers=headers).content
f = open(\'temp.pdf\', \'wb\')
f.write(sec_res)
f.close()
local_data = read_pdf_text(\'temp.pdf\')
print(local_data)
打印输出结果(部分截图):

发现其实文字的话是可以正常提取,但是一旦有表格的话提取出来的并不理想,又绕回来了,还是得用上camelot?
我又回到刚才那个问题,得通过什么工具获取到页码,然后用for循环结合camelot就可以了,根据上面的pdfminer,发现确实能获取到页码,但是感觉代码量有点多啊,我就获取个页面都要这么多行,我又换了个工具—— PyPDF2,而且camelot就是在PyPDF2之上操作的
好,怎么获取呢?
# 获取页码数
reader = PdfFileReader(file_path)
# 不解密可能会报错:PyPDF2.utils.PdfReadError: File has not been decrypted
if reader.isEncrypted:
reader.decrypt(\'\')
pages = reader.getNumPages()
就这几行就可以了,实际其实就两行,中间那个是为了判断pdf是否有加密的
那么结合camelot来操作:
import camelot
import requests
import re
import js2py
import execjs
from urllib.parse import urljoin
from lxml.html import tostring
from bs4 import BeautifulSoup
from html import unescape
from lxml import etree
from PyPDF2 import PdfFileReader
def camelot_contrl_pdf(file_path):
# 单页处理
# 获取页码数
reader = PdfFileReader(file_path)
# 不解密可能会报错:PyPDF2.utils.PdfReadError: File has not been decrypted
if reader.isEncrypted:
reader.decrypt(\'\')
pages = reader.getNumPages()
if not pages:
return
content = \'\'
for page in range(pages):
tables = None
f = None
local_data = None
page = str(page + 1)
try:
tables = camelot.read_pdf(file_path, pages=page, flavor=\'stream\')
except Exception:
pass
if tables:
tables[0].df.to_html(\'foo.html\', header=False, index=False)
if os.path.exists(\'foo.html\'):
try:
f = open(\'foo.html\', encoding=\'utf-8\')
local_data = f.read()
except Exception:
try:
f = open(\'foo.html\', encoding=\'gbk\')
local_data = f.read()
except Exception:
pass
if local_data:
content += local_data
if f:
f.close()
if content:
return content
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36\',
}
url = \'\' # 保密
req = requests.get(url, headers=headers, verify=False)
res = req.content.decode(\'utf-8\')
html = etree.HTML(res)
data = html.xpath(\'//table[@class="table"]/tbody/tr\')
second_link_f = \'\' # 保密
for item in data:
second_url = \'\'.join(link) if link else \'\'
sec_req = requests.get(second_url, headers=headers, verify=False)
sec_res = sec_req.content.decode(\'gbk\')
sec_html = etree.HTML(sec_res)
fujian_url = sec_html.xpath(\'//iframe/@src\')
fujian_url = \'\'.join(fujian_url) if fujian_url else \'\'
if fujian_url:
thr_link = re.findall(r\'file=(.*)\', fujian_url)
if thr_link:
thr_link = thr_link[0]
thr_url = urljoin(second_link_f, thr_link)
print(thr_url)
thr_res = requests.get(thr_url, headers=headers).content
if not thr_res or b\'%%EOF\' not in thr_res:
continue
fujian_index = thr_res.index(b\'%%EOF\')
thr_res = thr_res[:fujian_index + len(b\'%%EOF\')]
# checkXO = rb"/Type(?= */XObject)"
# checkIM = rb"/Subtype(?= */Image)"
# isXObject = re.search(checkXO, thr_res)
# isImage = re.search(checkIM, thr_res)
# if isXObject and isImage:
# # 是图片跳过
# continue
f = open(\'temp.pdf\', \'wb\')
f.write(thr_res)
f.close()
local_data = camelot_contrl_pdf(\'temp.pdf\')
if local_data:
soup = BeautifulSoup(local_data, \'html.parser\')
if os.path.exists(\'temp.pdf\'):
os.remove(\'temp.pdf\') # 删除本地的pdf
if soup:
[s.extract() for s in soup("style")]
[s.extract() for s in soup("title")]
[s.extract() for s in soup("script以上是关于python爬虫处理在线预览的pdf文档的主要内容,如果未能解决你的问题,请参考以下文章
求:JavaWEB实现Excel,Word ,PDF 等文档在线预览思路和源码Jar