学习-17
Posted av404
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习-17相关的知识,希望对你有一定的参考价值。
1. 什么是Jenkins?
Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件项目可以进行(持续集成)
2. 为什么要使用jenkins
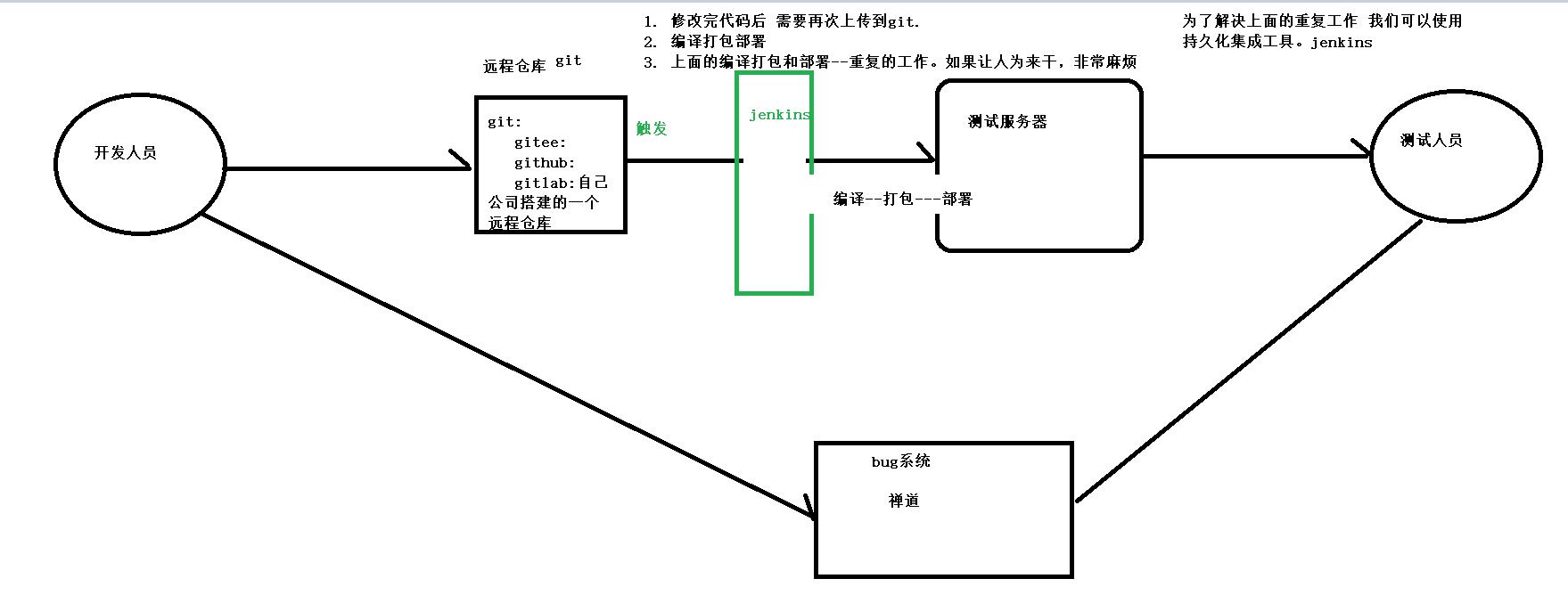
3. 如何安装jenkins
3.1 下载jenkins的安装包
https://get.jenkins.io/war-stable/2.164.1/
3.2 把该文件放入到linux系统并运行
nohup java -jar /usr/local/jenkins.war --httpPort=8777 > /usr/local/jenkins.log 2>&1 &
nohup: 当服务器休眠时 改软件还在运行 java -jar: 执行war或jar文件--httpPort: http的端口号 &: 后台运行

3.3 访问jenkins
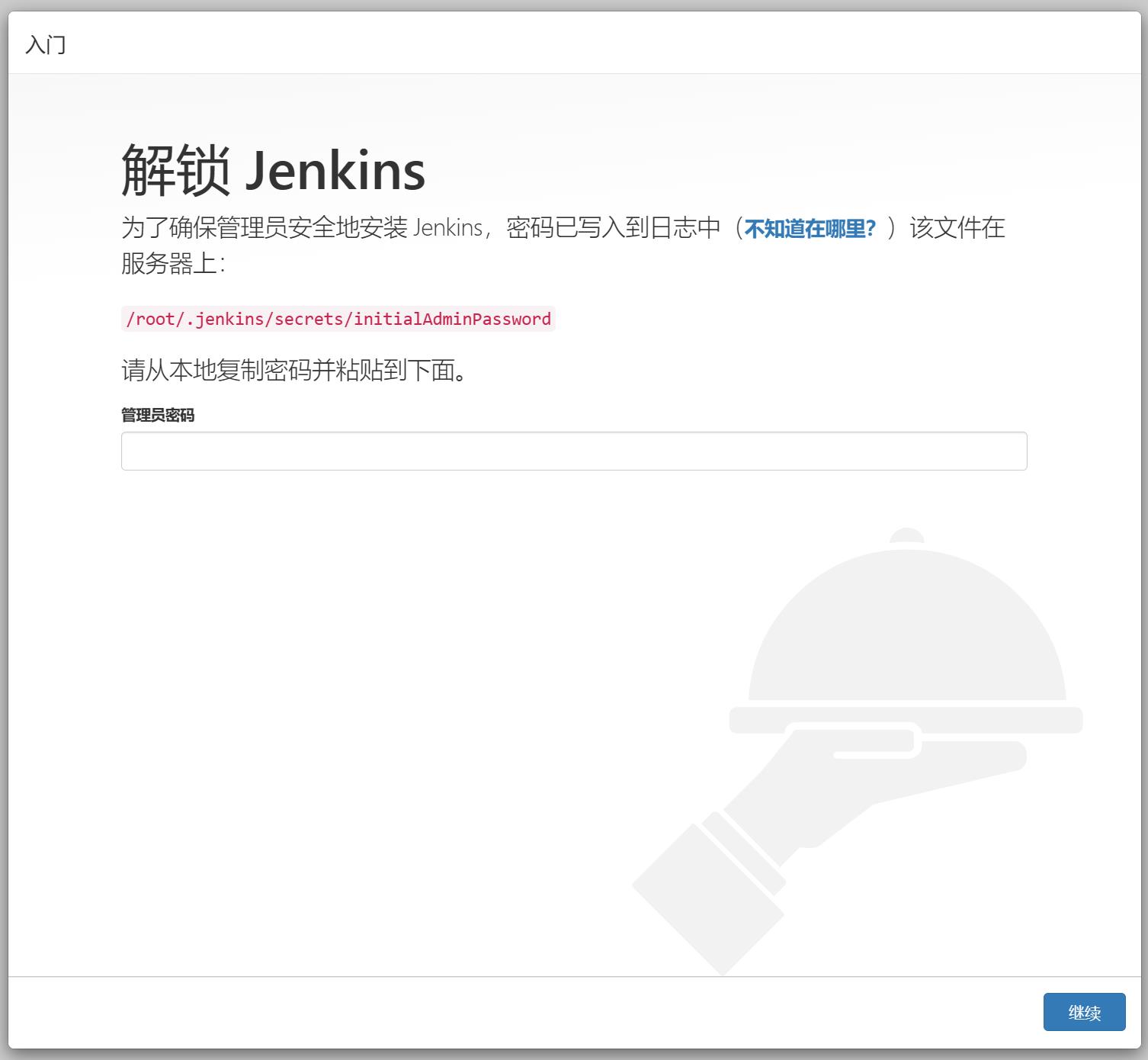
cat /root/.jenkins/secrets/initialAdminPassword

选择【安装推荐的插件】
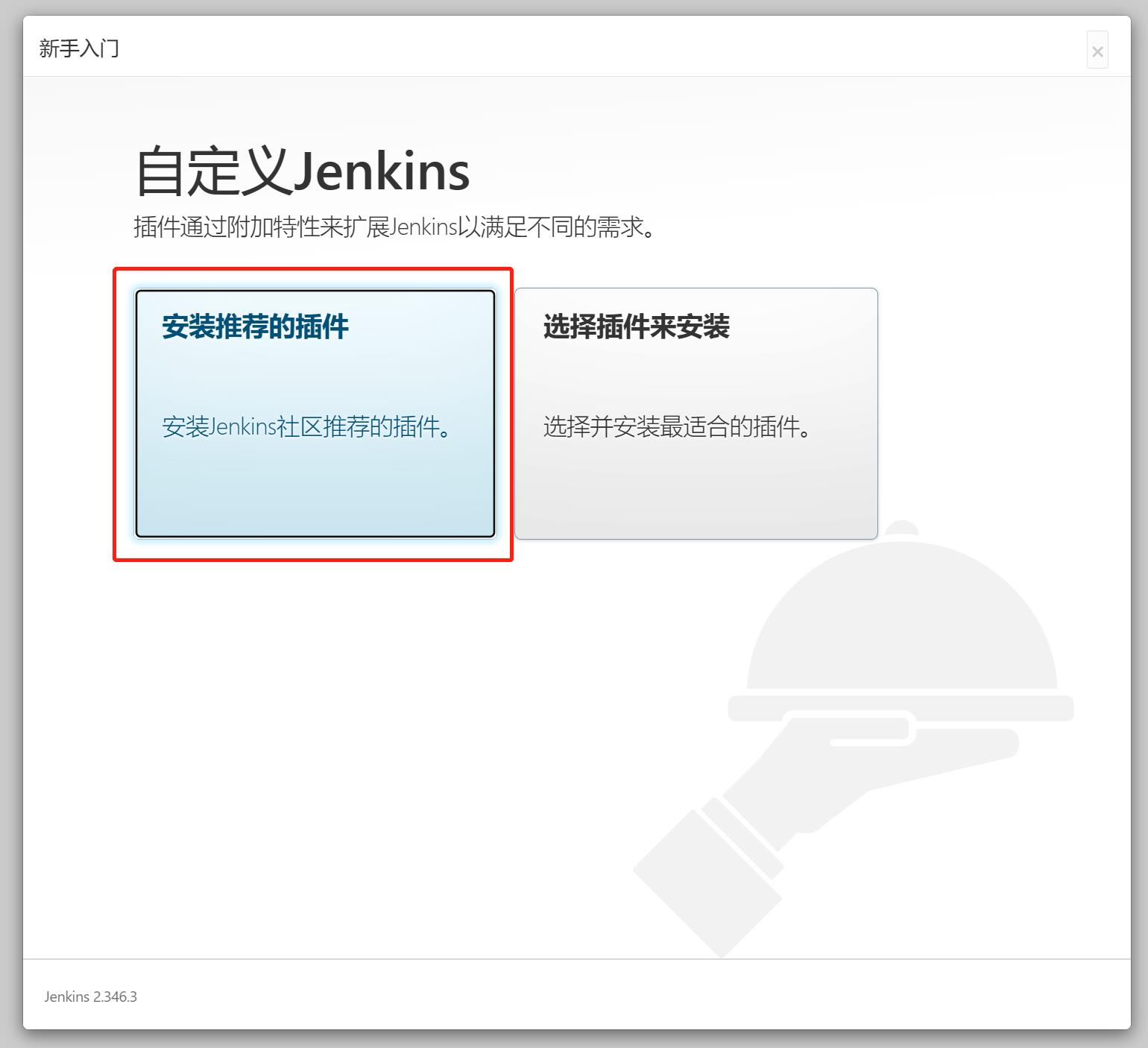
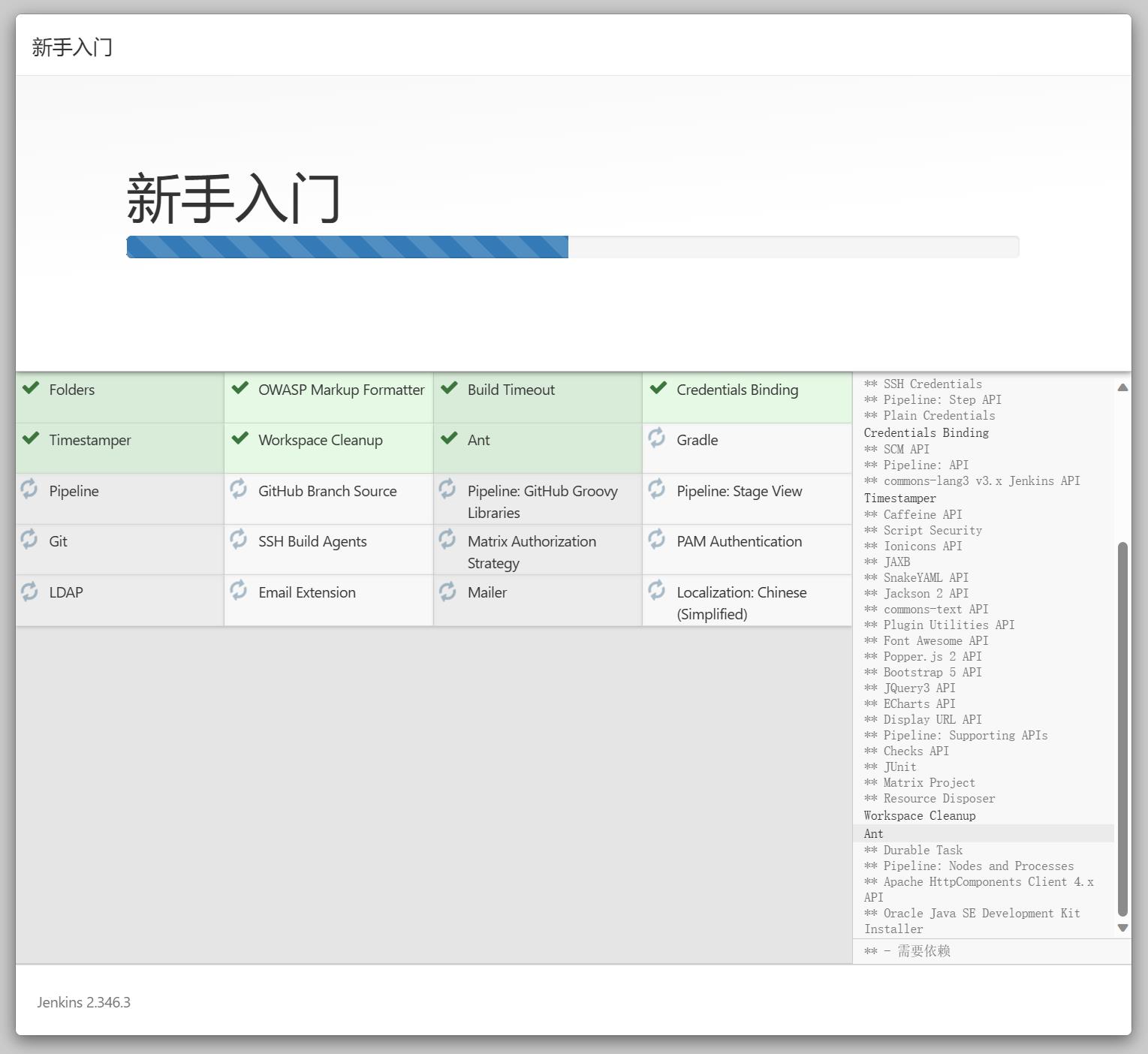
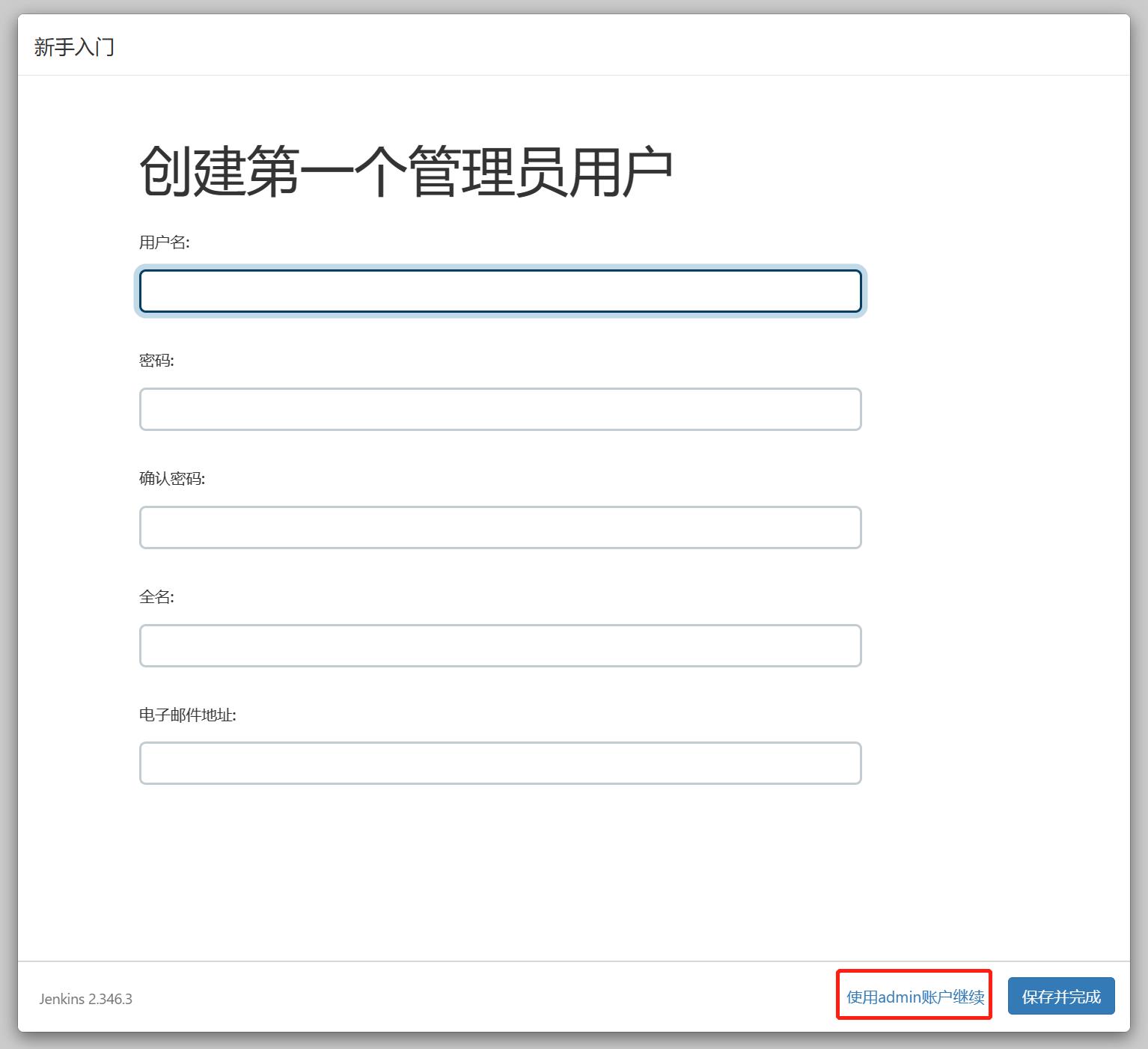
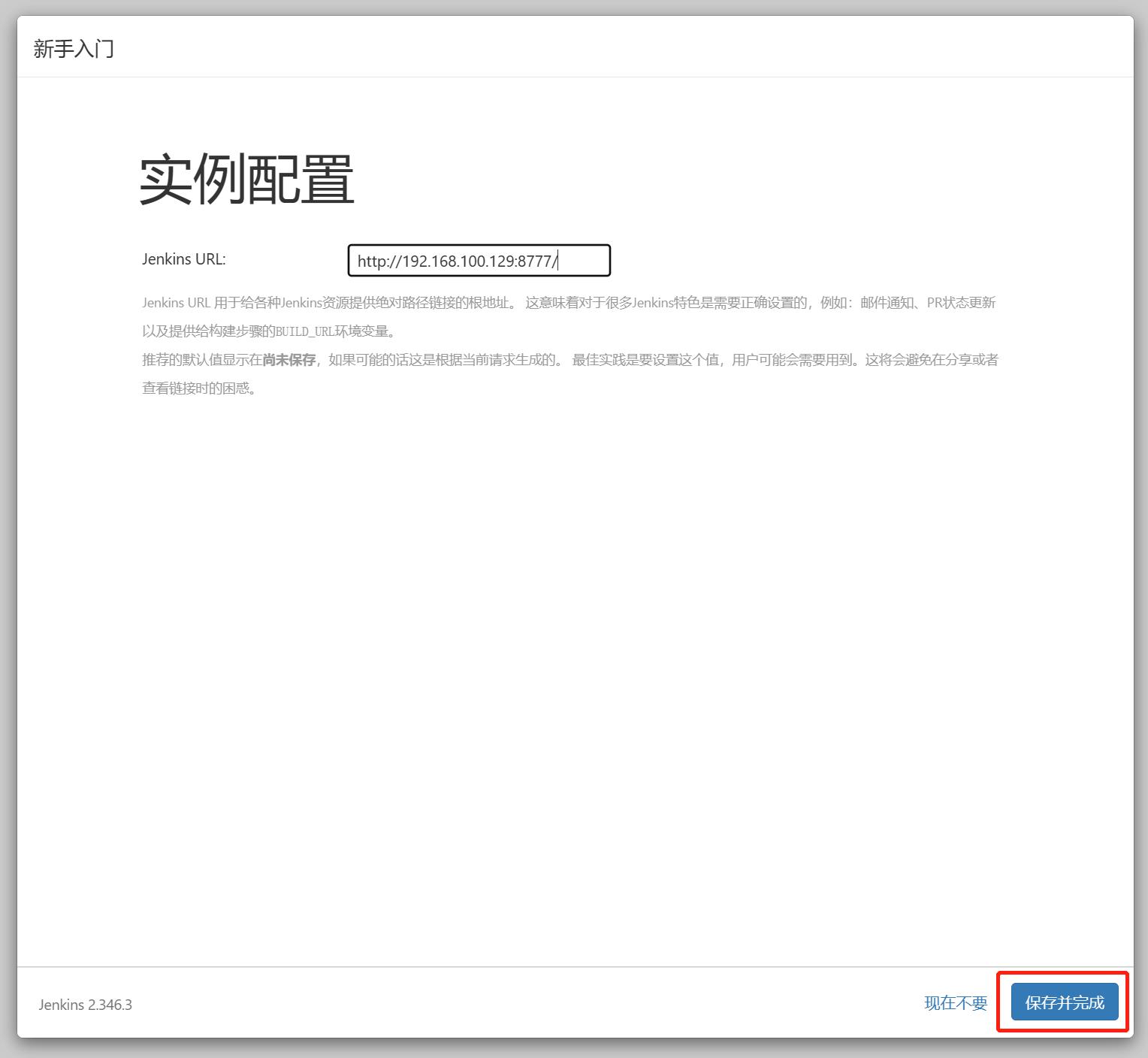
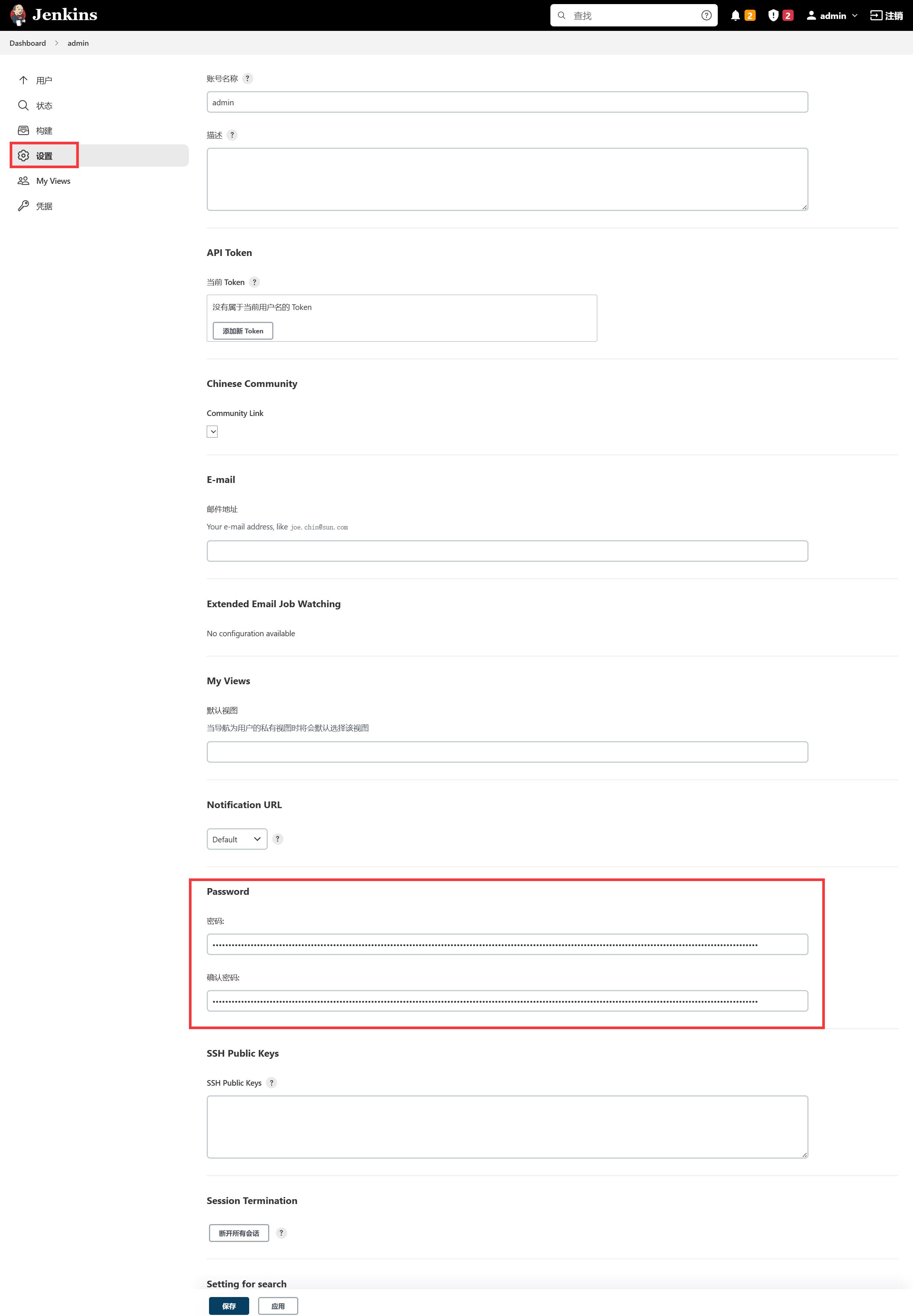
3.4 修改密码
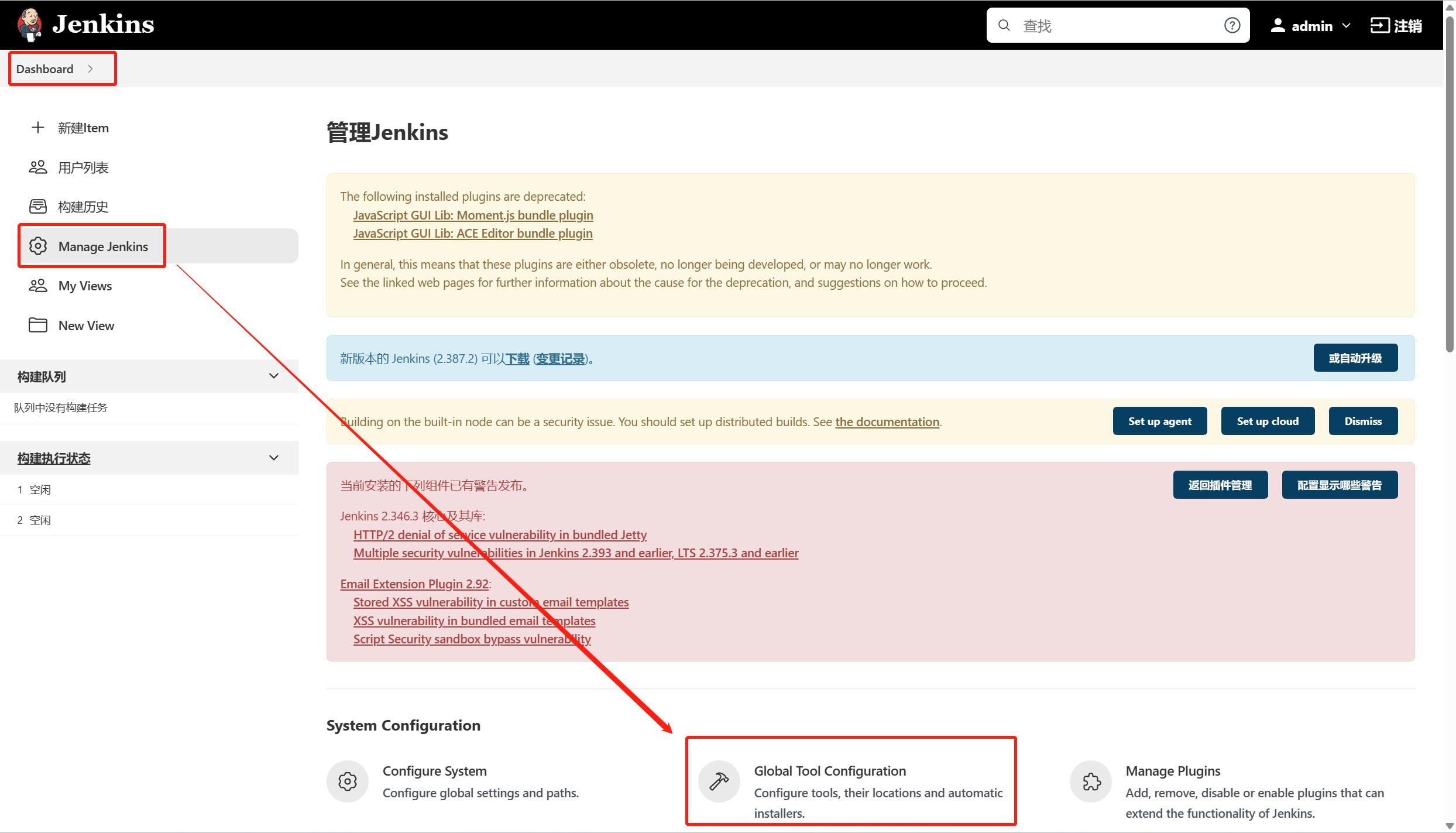
4. jenkins集成jdk
因为我们的项目通过jenkins从gitee拉取后需要编译。---javac. 所以
jenkins需要集成jdk
(1)在jenkins所在的服务器安装jdk并配置环境变量

(2)集成jdk

5. jenkins集成git
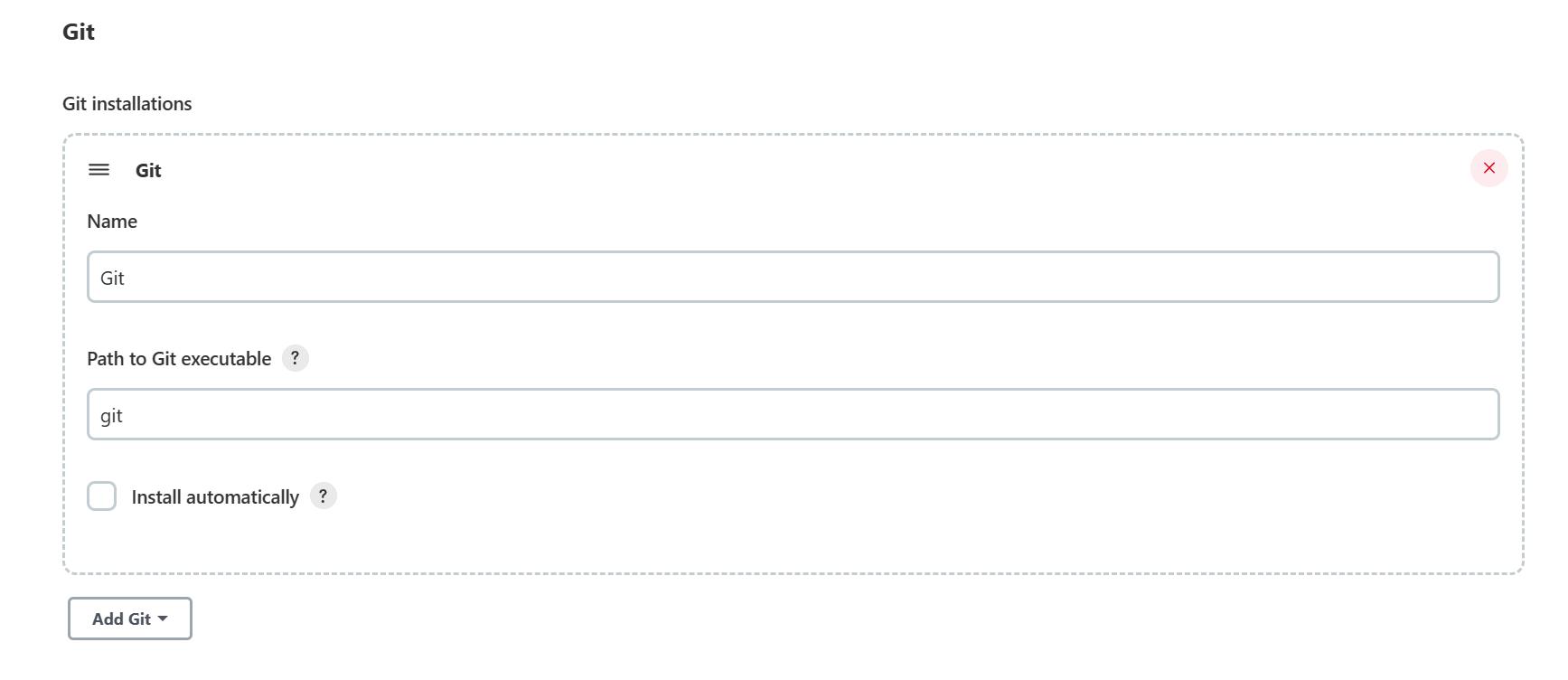
因为jenkins需要从远程仓库拉取代码 所以需要集成git
(1)在jenkins所在的服务器安装git
yum install -y git
(2)jenkins集成安装的git
(3)在gitee创建远程仓库
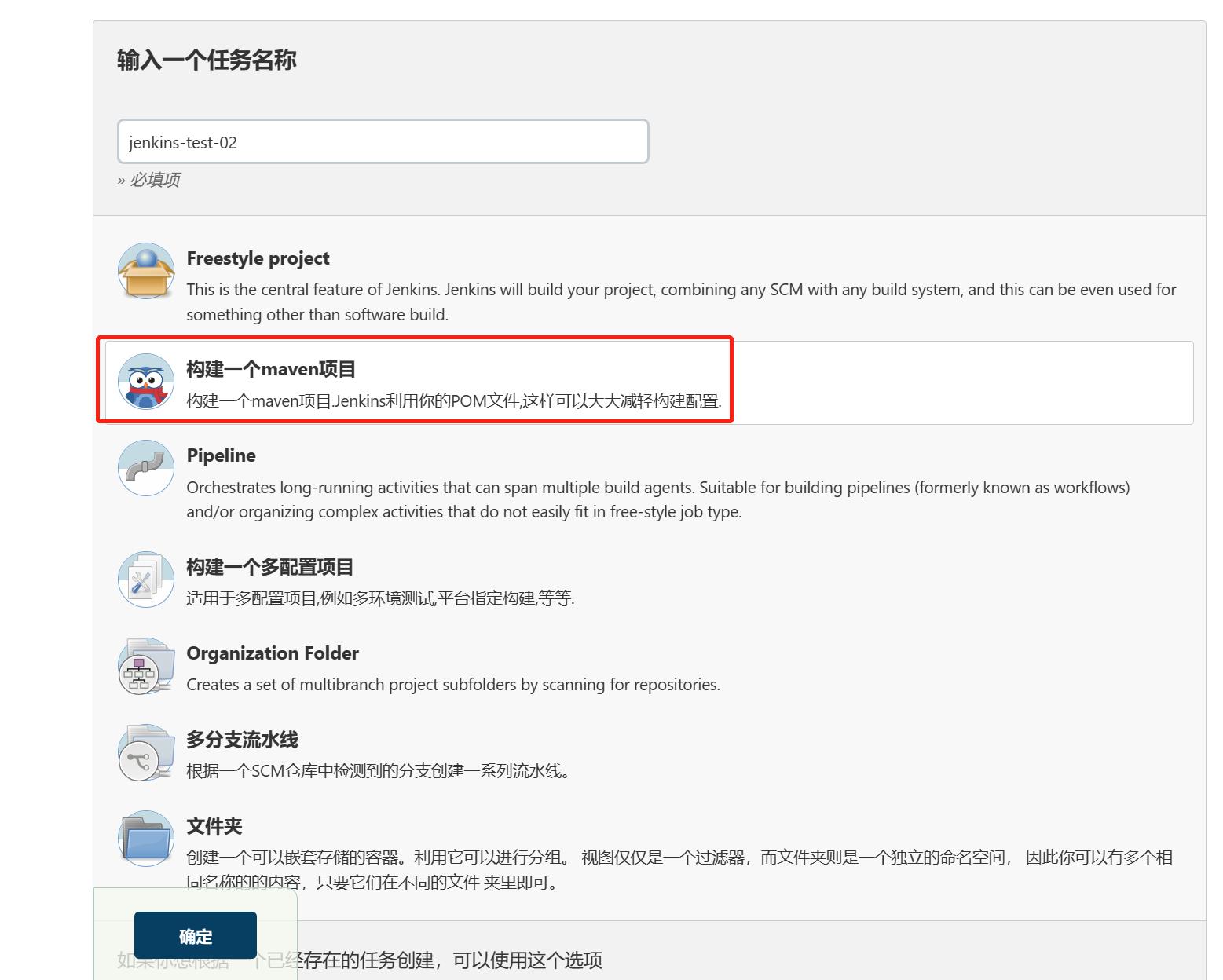
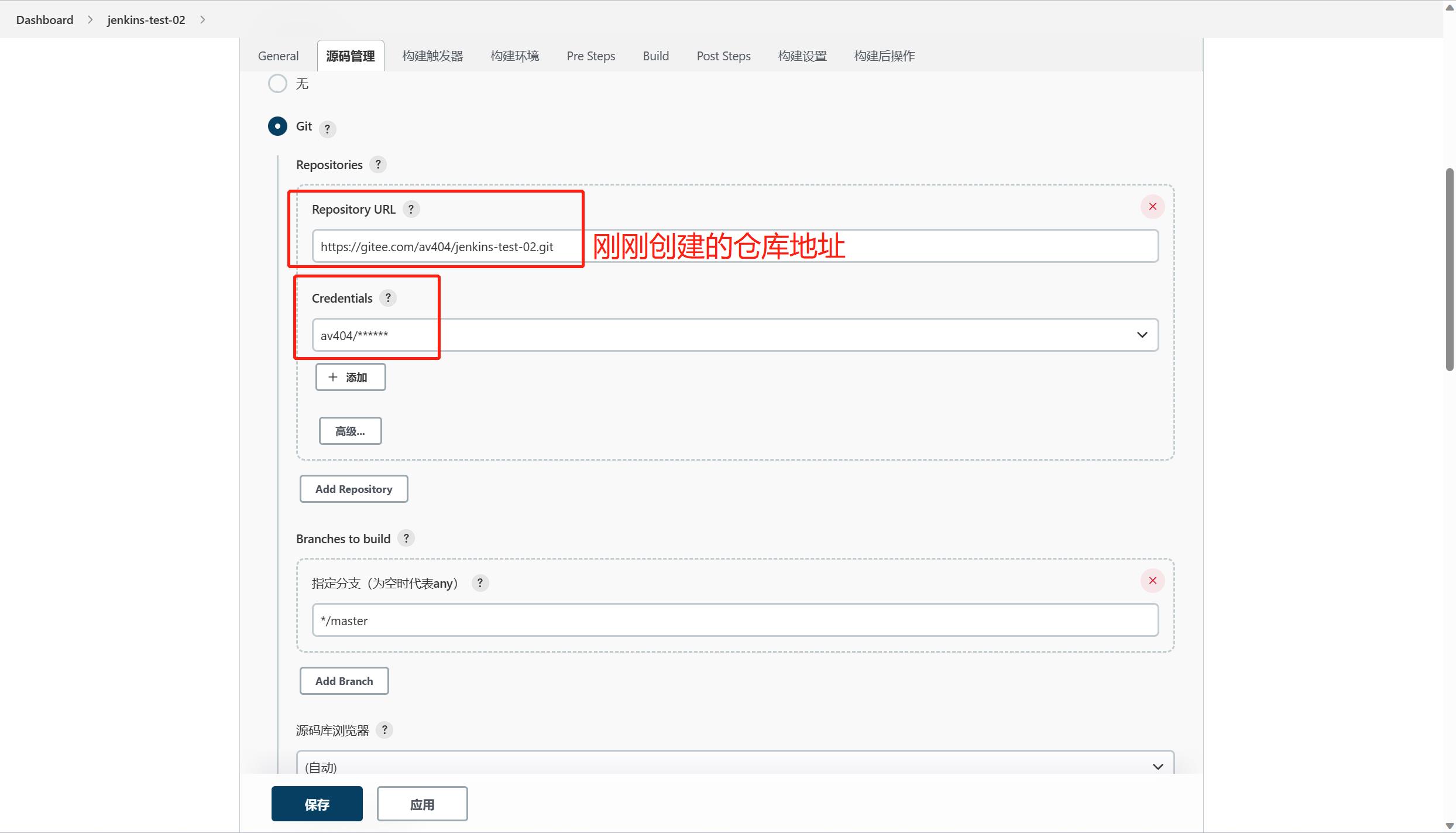
(4)jenkins中创建任务
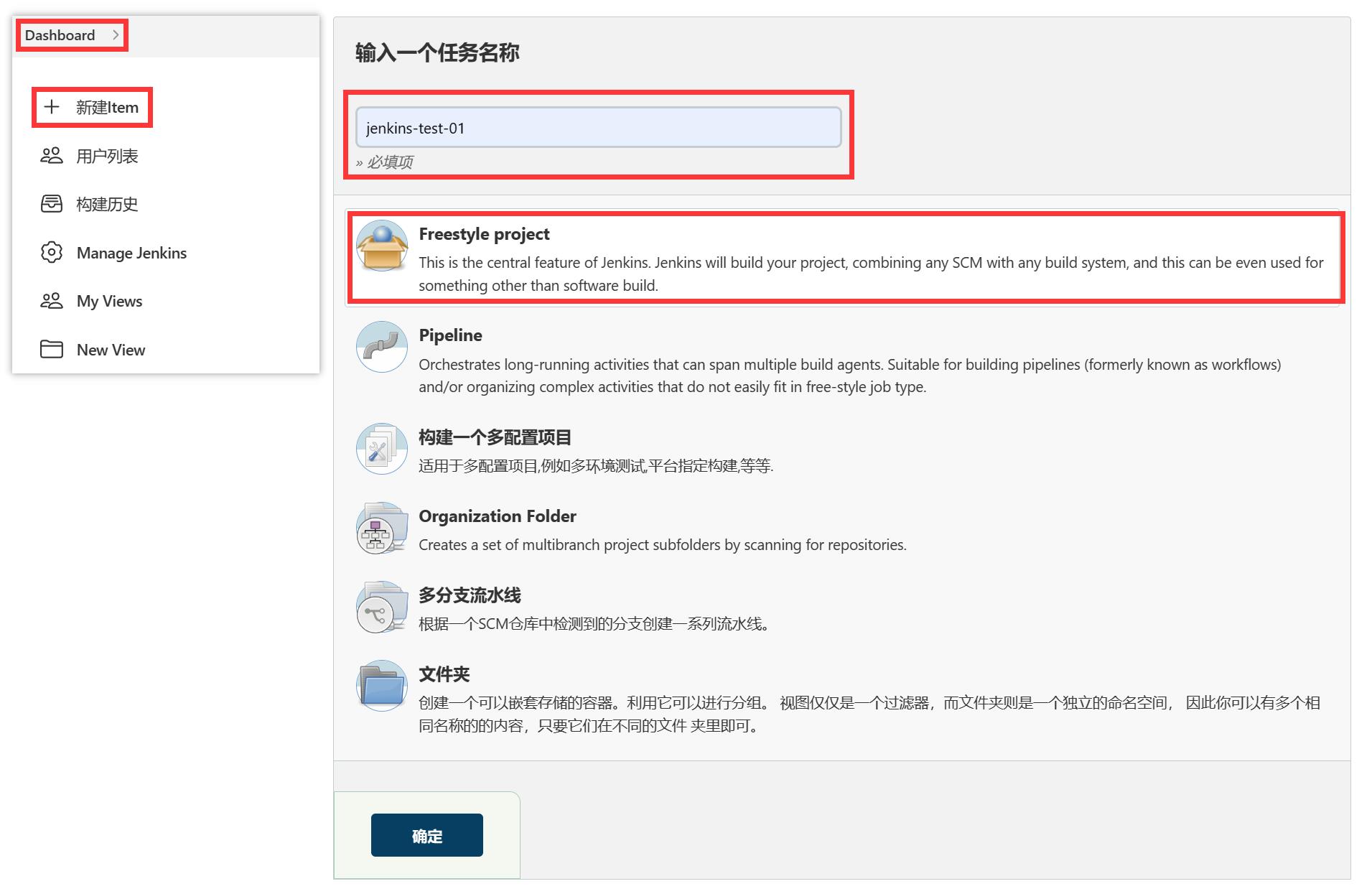
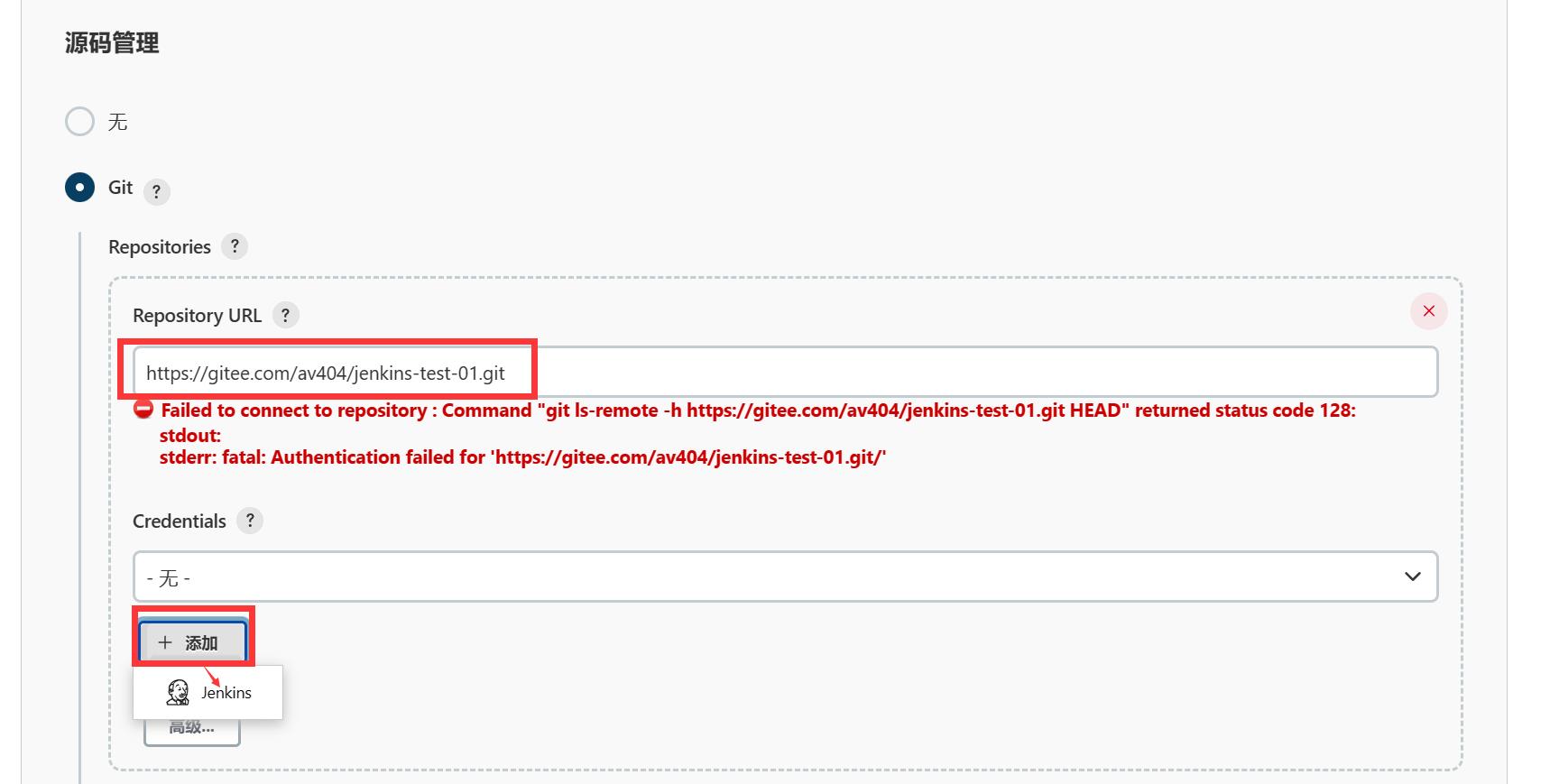
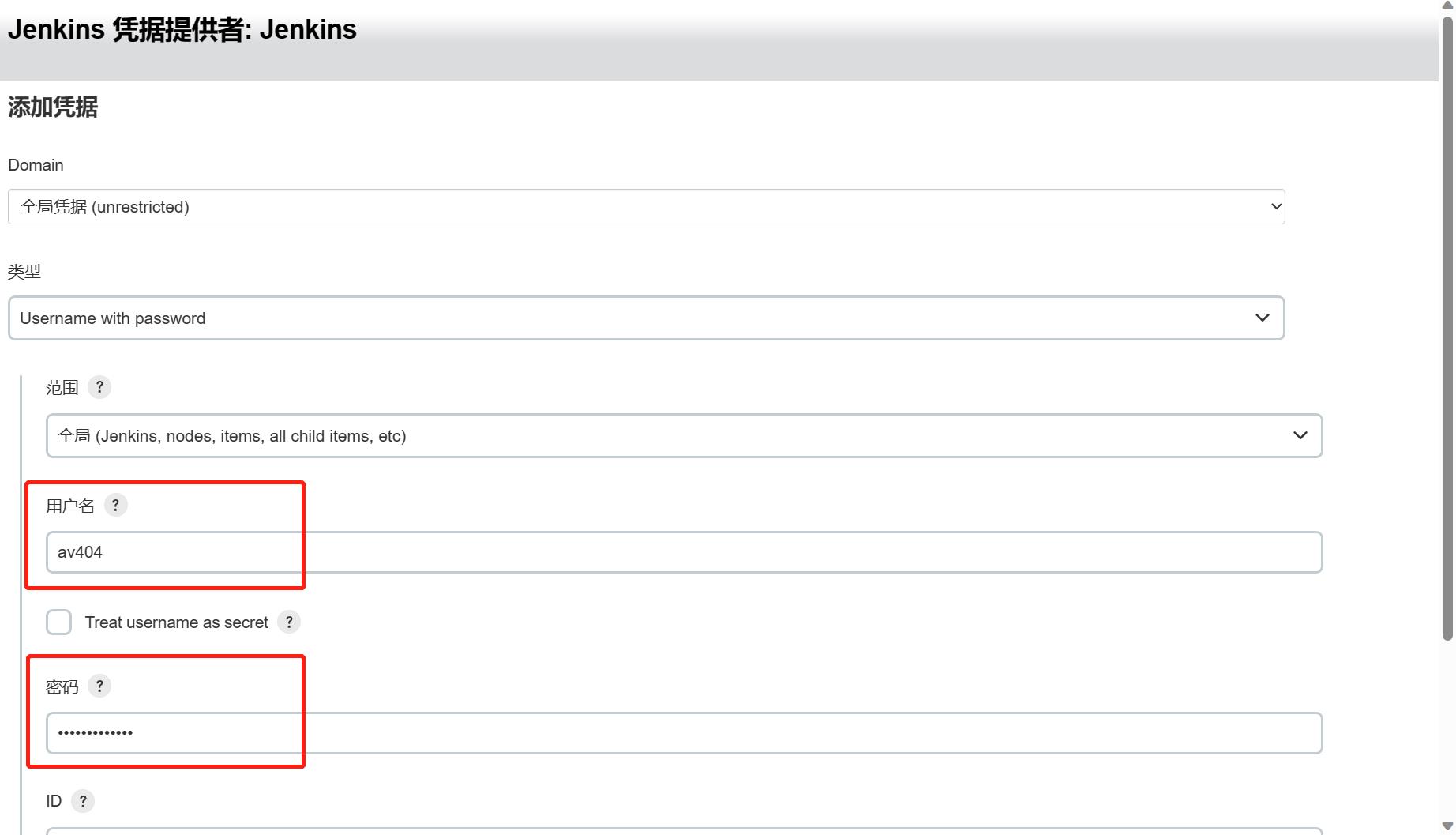
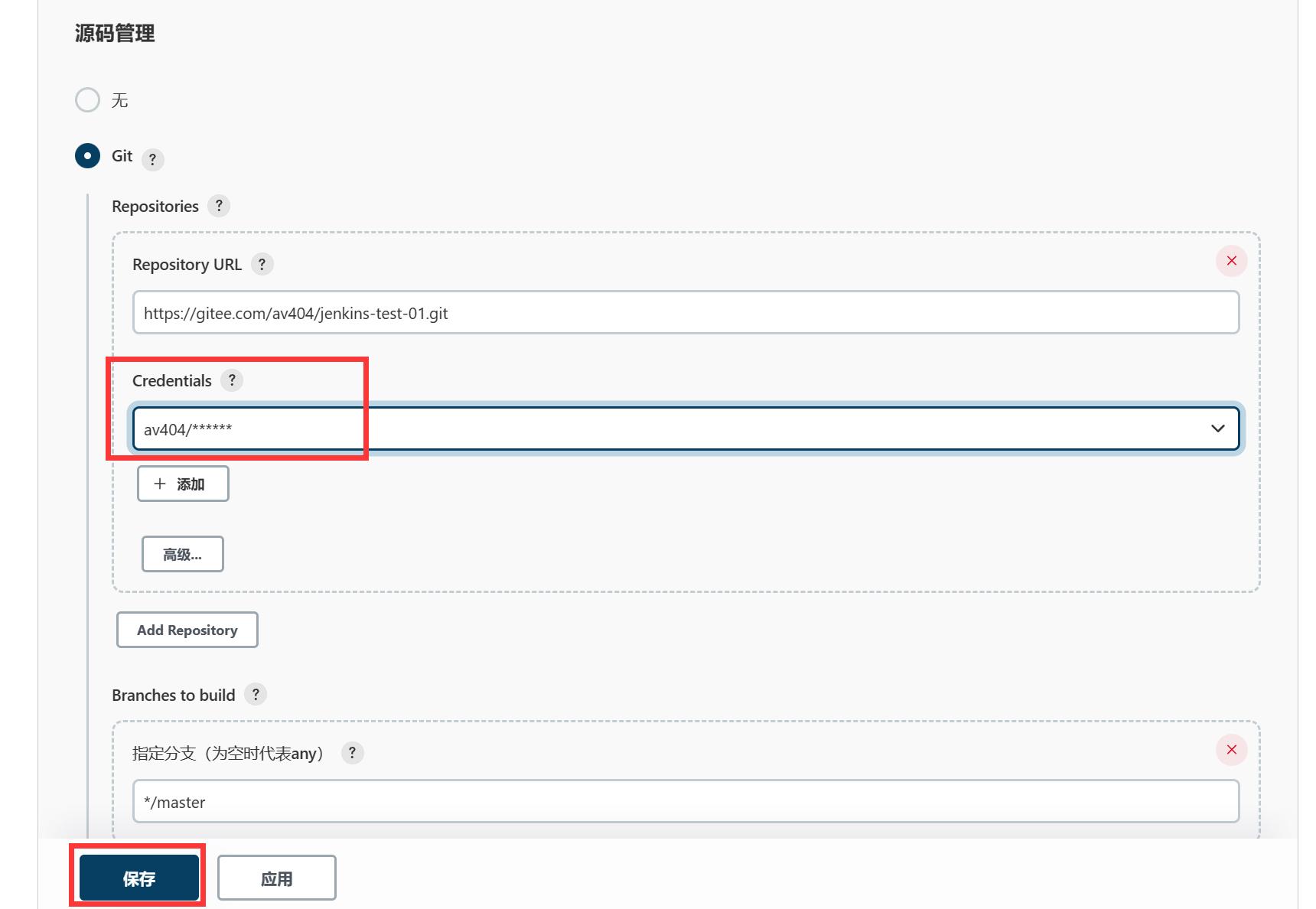
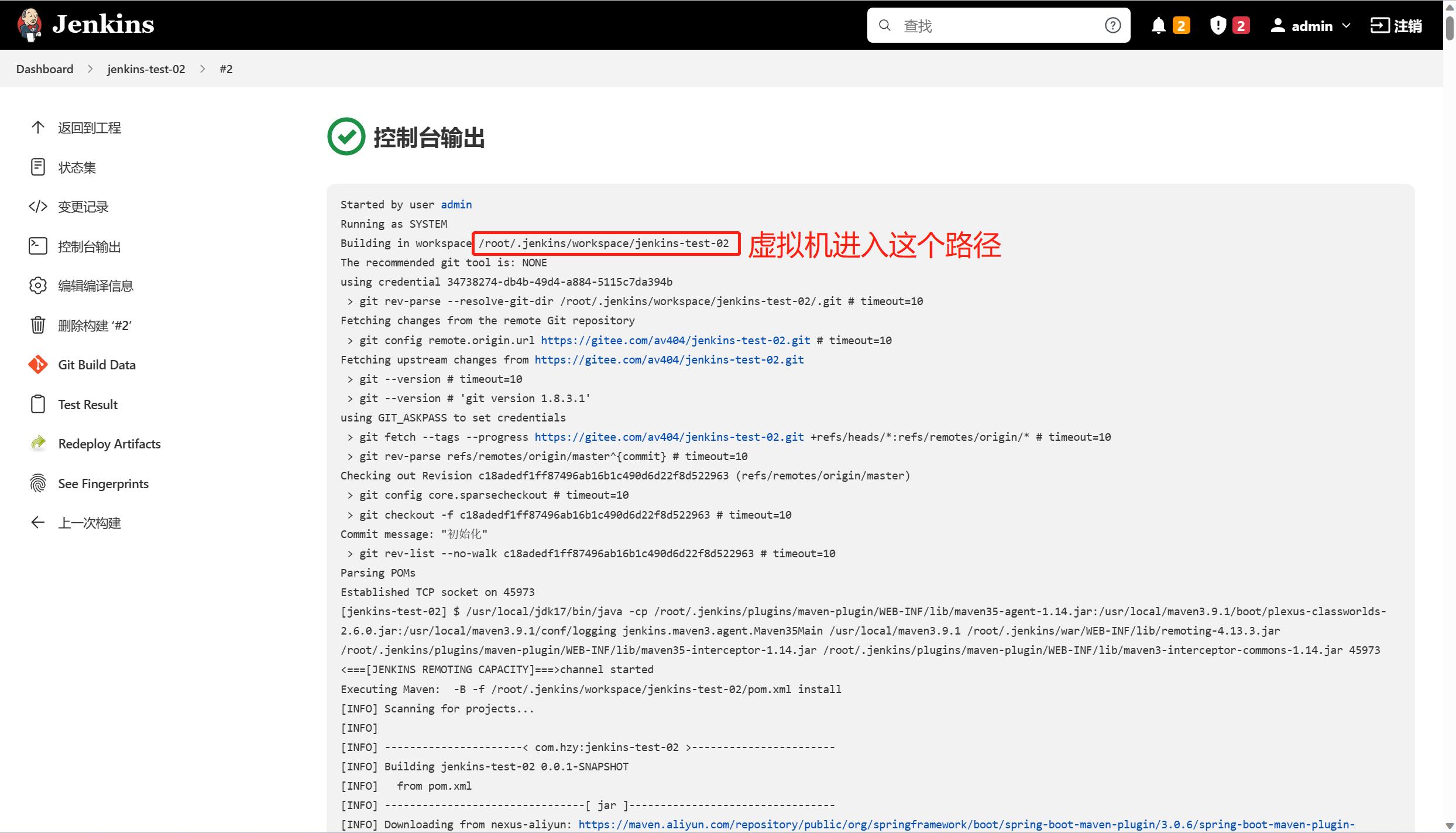
拉取编译项目
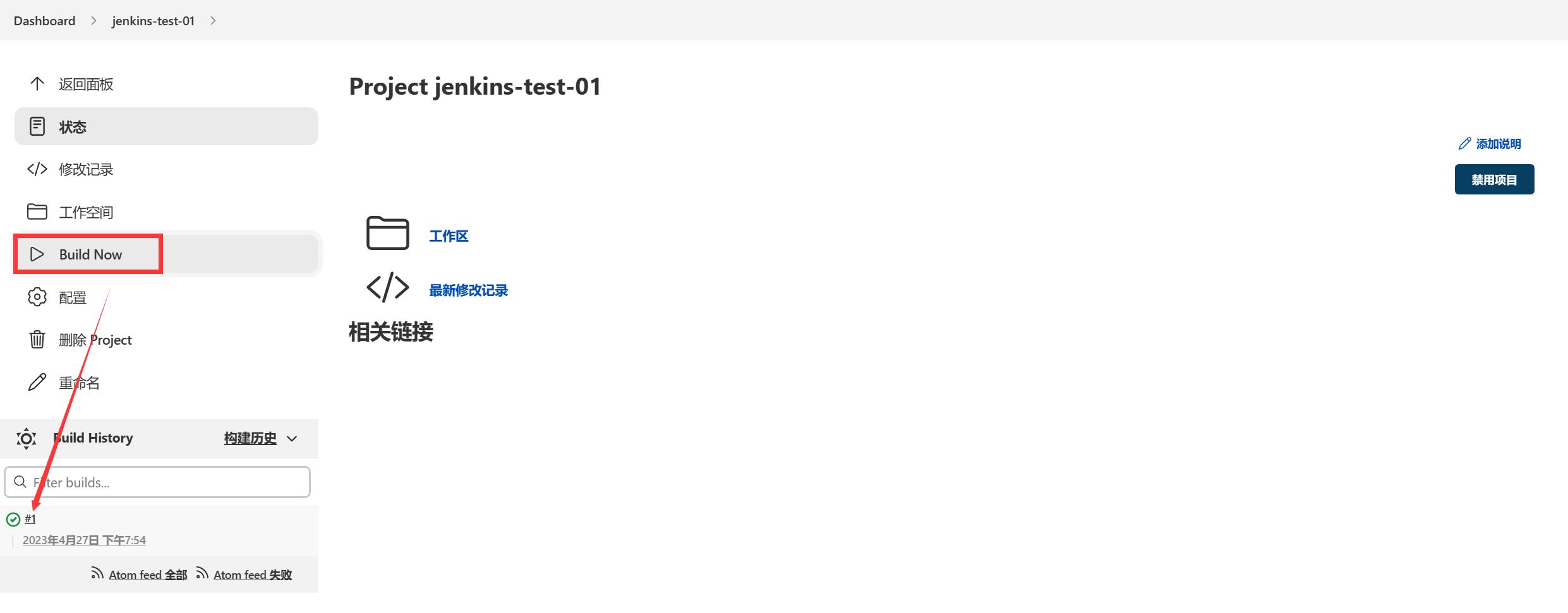
查看是否正确
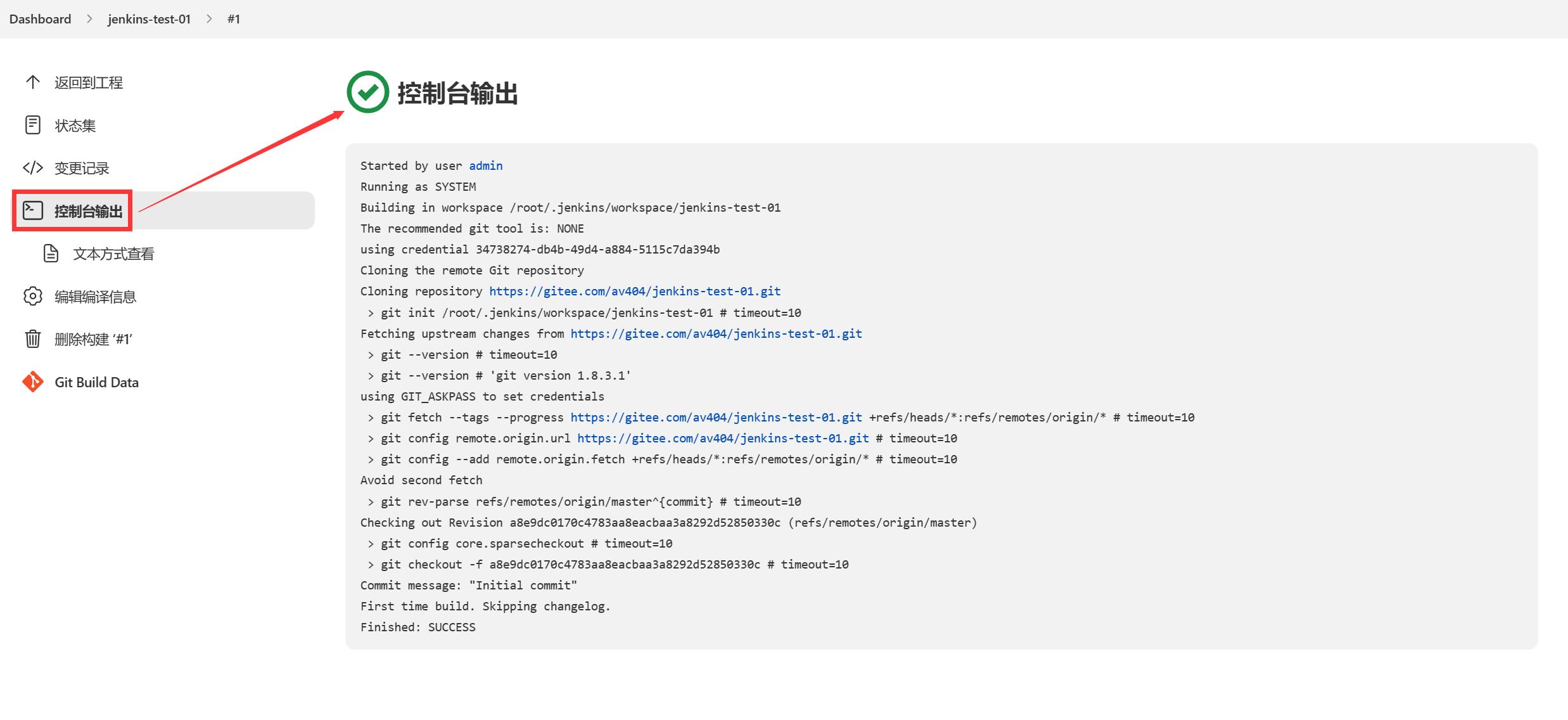
查看linux服务器中拉取的代码
6. jenkins集成maven
我们现在很多项目都是maven的项目架构,所以我们jenkins从远程仓库拉取的代码必须有maven管理依赖jar包
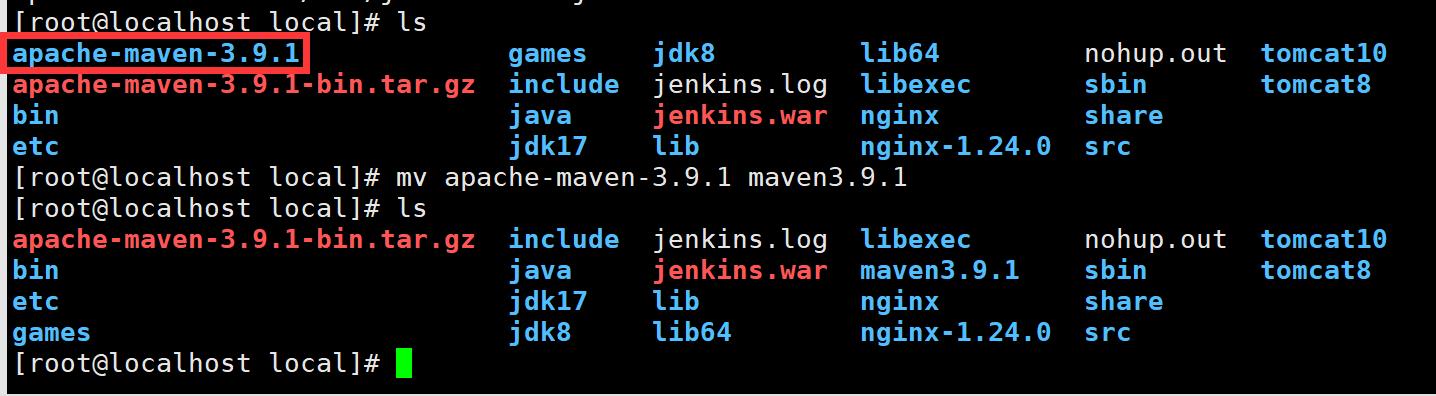
(1)jenkins所在的服务器安装maven并解压
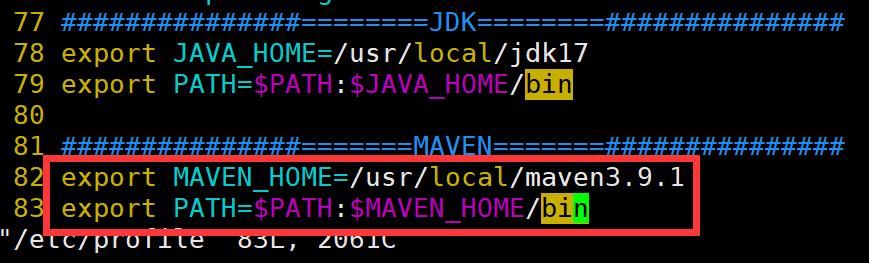
(2)配置环境变量
vi /etc/profile
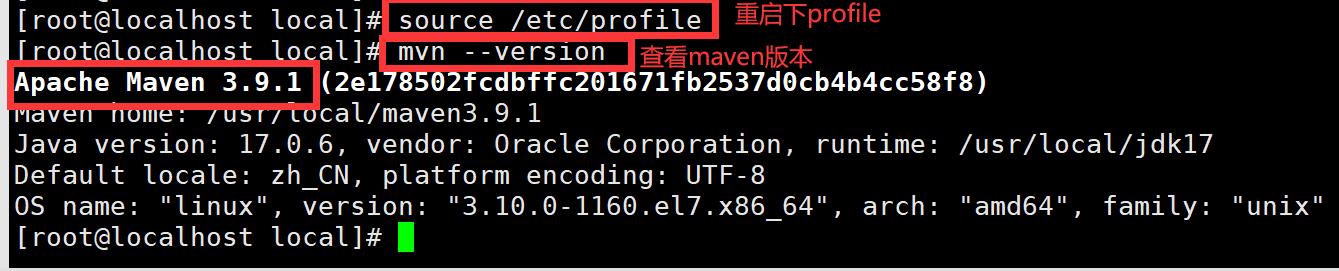
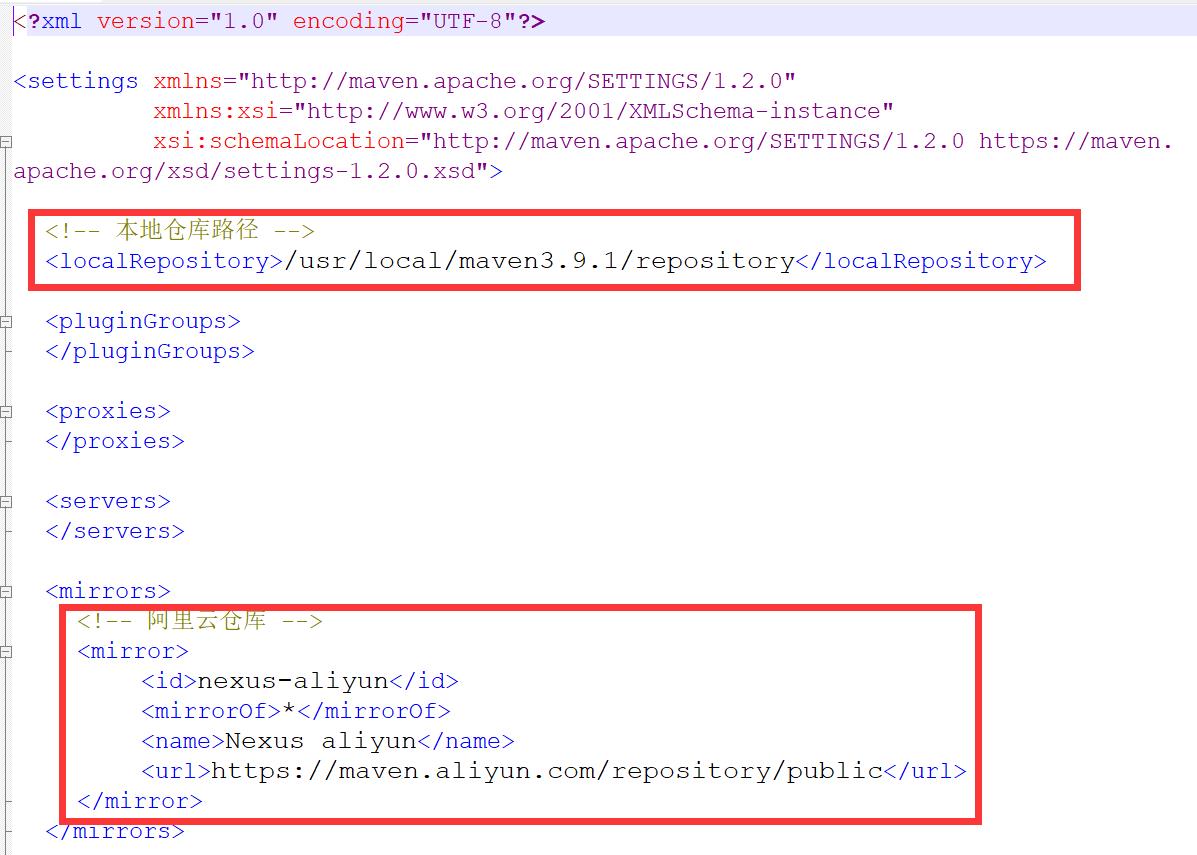
(3) 修改maven的配置文件--镜像---本地仓库地址
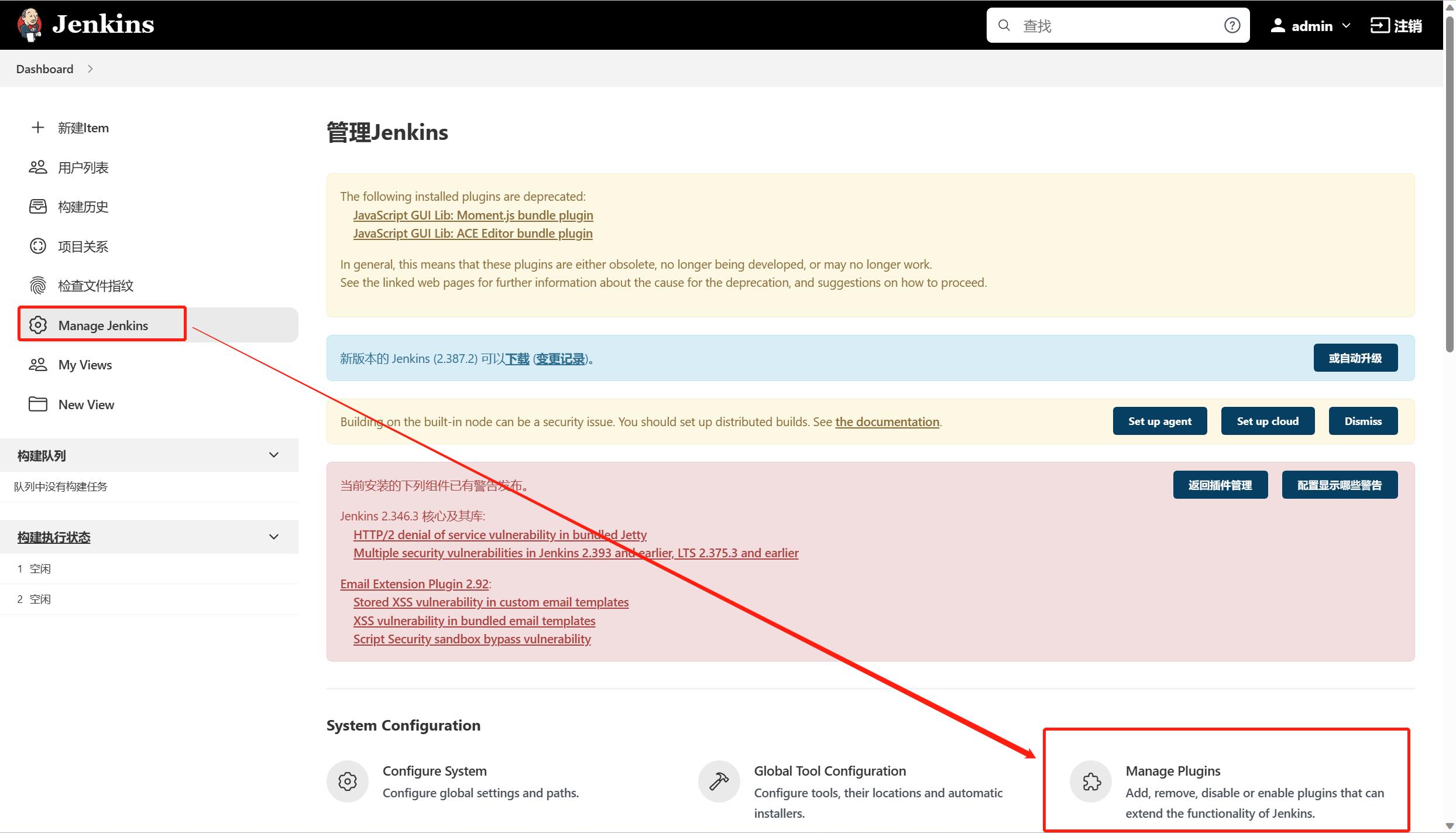
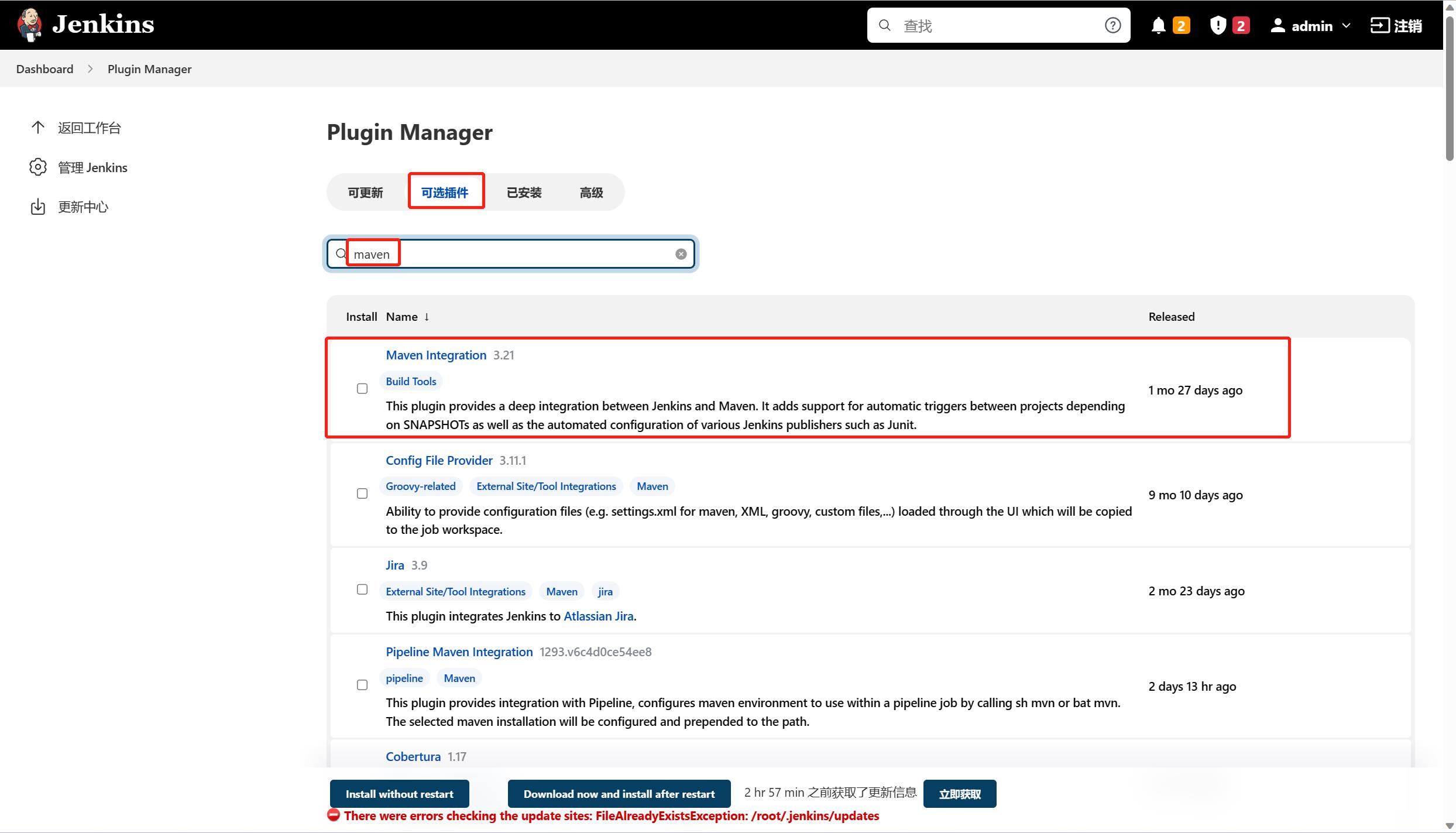
(4) jenkins集成maven

安装maven的插件
在git上创建一个仓库并上传maven项目
在jenkins创建任务项
机器学习中的有监督学习,无监督学习,半监督学习
在机器学习(Machine learning)领域。主要有三类不同的学习方法:
监督学习(Supervised learning)、
非监督学习(Unsupervised learning)、
半监督学习(Semi-supervised learning),
监督学习:通过已有的一部分输入数据与输出数据之间的相应关系。生成一个函数,将输入映射到合适的输出,比如分类。
非监督学习:直接对输入数据集进行建模,比如聚类。
半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
一、监督学习
1、监督式学习(Supervised learning),是一个机器学习中的方法。能够由训练资料中学到或建立一个模式( learning model)。并依此模式猜測新的实例。
训练资料是由输入物件(一般是向量)和预期输出所组成。函数的输出能够是一个连续的值(称为回归分析)。或是预測一个分类标签(称作分类)。
2、一个监督式学习者的任务在观察完一些训练范例(输入和预期输出)后,去预測这个函数对不论什么可能出现的输入的值的输出。要达到此目的。学习者必须以"合理"(见归纳偏向)的方式从现有的资料中一般化到非观察到的情况。
在人类和动物感知中。则通常被称为概念学习(concept learning)。
3、监督式学习有两种形态的模型。
最一般的。监督式学习产生一个全域模型,会将输入物件相应到预期输出。而还有一种,则是将这样的相应实作在一个区域模型。(如案例推论及近期邻居法)。为了解决一个给定的监督式学习的问题(手写辨识),必须考虑下面步骤:
1)决定训练资料的范例的形态。
在做其他事前,project师应决定要使用哪种资料为范例。譬如,可能是一个手写字符,或一整个手写的词汇。或一行手写文字。
2)搜集训练资料。这资料需要具有真实世界的特征。所以。能够由人类专家或(机器或传感器的)測量中得到输入物件和其相相应输出。
3)决定学习函数的输入特征的表示法。
学习函数的精确度与输入的物件怎样表示是有非常大的关联度。传统上,输入的物件会被转成一个特征向量。包括了很多关于描写叙述物件的特征。由于维数灾难的关系。特征的个数不宜太多,但也要足够大。才干准确的预測输出。
4)决定要学习的函数和其相应的学习算法所使用的数据结构。譬如。project师可能选择人工神经网络和决策树。
5)完毕设计。project师接着在搜集到的资料上跑学习算法。能够借由将资料跑在资料的子集(称为验证集)或交叉验证(cross-validation)上来调整学习算法的參数。參数调整后,算法能够执行在不同于训练集的測试集上
另外对于监督式学习所使用的词汇则是分类。现著有著各式的分类器。各自都有强项或弱项。分类器的表现非常大程度上地跟要被分类的资料特性有关。
并没有某一单一分类器能够在全部给定的问题上都表现最好,这被称为‘天下没有白吃的午餐理论’。
各式的经验法则被用来比較分类器的表现及寻找会决定分类器表现的资料特性。决定适合某一问题的分类器仍旧是一项艺术,而非科学。
眼下最广泛被使用的分类器有人工神经网络、支持向量机、近期邻居法、高斯混合模型、朴素贝叶斯方法、决策树和径向基函数分类。
二、无监督式学习
1、无监督式学习(Unsupervised Learning )是人工智能网络的一种算法(algorithm)。其目的是去对原始资料进行分类,以便了解资料内部结构。有别于监督式学习网络,无监督式学习网络在学习时并不知道其分类结果是否正确,亦即没有受到监督式增强(告诉它何种学习是正确的)。其特点是仅对此种网络提供输入范例。而它会自己主动从这些范例中找出其潜在类别规则。当学习完成并经測试后,也能够将之应用到新的案例上。
2、无监督学习里典型的样例就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常仅仅须要知道怎样计算相似度就能够開始工作了。
三、半监督学习
1、半监督学习的基本思想是利用数据分布上的模型如果, 建立学习器对未标签样本进行标签。
形式化描写叙述为:
给定一个来自某未知分布的样本集S=L∪U, 当中L 是已标签样本集L={(x1,y1),(x2,y2), … ,(x |L|,y|L|)}, U是一个未标签样本集U={x’1,x’2,…,x’|U|},希望得到函数f:X → Y能够准确地对样本x预測其标签y,这个函数可能是參数的。如最大似然法;可能是非參数的。如最邻近法、神经网络法、支持向量机法等;也可能是非数值的,如决策树分类。当中, x与x’ 均为d 维向量, yi∈Y 为样本x i 的标签, |L| 和|U| 分别为L 和U
的大小, 即所包括的样本数。半监督学习就是在样本集S 上寻找最优的学习器。怎样综合利用已标签例子和未标签例子,是半监督学习须要解决的问题。
2、半监督学习问题从样本的角度而言是利用少量标注样本和大量未标注样本进行机器学习。从概率学习角度可理解为研究怎样利用训练样本的输入边缘概率 P( x )和条件输出概率P ( y | x )的联系设计具有良好性能的分类器。这样的联系的存在是建立在某些如果的基础上的。即聚类如果(cluster assumption)和流形如果(maniford assumption)。
以上是关于学习-17的主要内容,如果未能解决你的问题,请参考以下文章