机器学习系列(17)_关联规则
Posted 温欣'
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习系列(17)_关联规则相关的知识,希望对你有一定的参考价值。
期末考关联规则部分会考选择题
1、关联规则学习(Association rule learning)
文章目录
一、关联规则含义
事务仅包含其涉及到的项目,而不包含项目的具体信息。(只要购买某种商品,则这种商品的标签就为1,否则为0,不管买了多少件产品)
X==>Y含义:
- X和Y是项集
- X称为规则前项
- Y称为规则后项
【1】支持度:一个项集或者规则在所有事务中出现的频率
例子:100个人去超市购物,其中同时购买啤酒和尿布的人数有30人,则关联规则的支持度为30%
【2】置信度:确定Y在包含X的事务中出现的频繁程度
例子:购买薯片的客户中有50%的人购买可乐,则置信度为50%
【3】提升度:物品集A的出现对物品集B的出现概率发生了多大的变化
二、关联规则商品案例
1、使用mlxtend工具包得出频繁项集与规则
!pip install mlxtend #安装包
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
自定义一份购物数据集
data = 'ID':[1,2,3,4,5,6],
'Onion':[1,0,0,1,1,1],
'Potato':[1,1,0,1,1,1],
'Burger':[1,1,0,0,1,1],
'Milk':[0,1,1,1,0,1],
'Beer':[0,0,1,0,1,0]
字典转化为Dataframe
df = pd.DataFrame(data) # 将字典变成DF
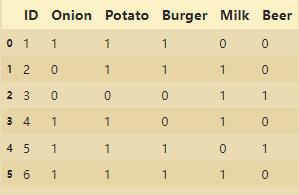
2、设置支持度来选择频繁项集
- 选择最小支持度为50%
- apriori(df,min_support=0.5,use_colnames=True)
frequent_itemsets = apriori(df[['Onion', 'Potato', 'Burger', 'Milk', 'Beer' ]], min_support=0.50, use_colnames=True)

3、计算规则
- association_rules(df,metric=‘lift’,min_threshold=1)
- 可以指定不同的衡量标准和最小阈值
rules = association_rules(frequent_itemsets, metric='lift', min_threshold=1)
min_threshold=1:表示最小阈值为1,即购买单个商品的也计算规则
返回的是各个指标的数值,可以按照感兴趣的指标排序观察,但具体解释还得参考实际数据的含义。
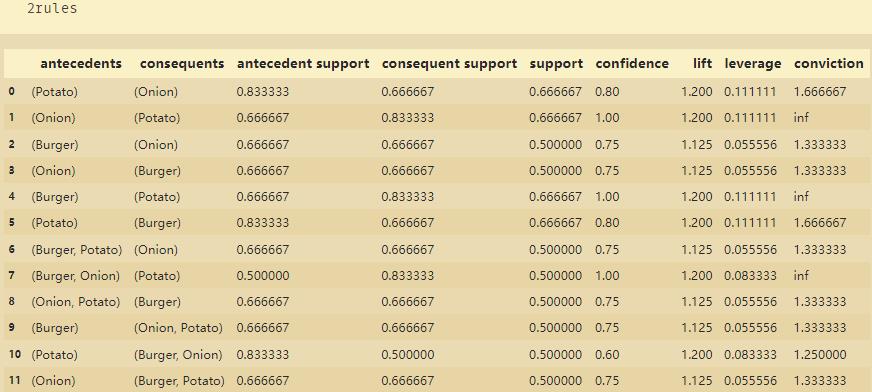
根据提升度和置信度进行查找:
rules[(rules['lift'] >1.125) & (rules['confidence']> 0.8) ]
rules['lift']:提升度
rules['confidence']:置信度

如上图,可以得出以下结论:
- (洋葱和马铃薯)(汉堡和马铃薯)可以搭配着来卖
- 如果洋葱和汉堡都在购物篮里,顾客买马铃薯的可能性也比较高,如果他的篮子里没有,则可以推荐一下
4、数据转换成为独热编码
使用啤酒和尿布的经典例子:
retail_shopping_basket = 'ID':[1,2,3,4,5,6],
'Basket':[['Beer', 'Diaper', 'Pretzels', 'Chips', 'Aspirin'],
['Diaper', 'Beer', 'Chips', 'Lotion', 'Juice', 'BabyFood', 'Milk'],
['Soda', 'Chips', 'Milk'],
['Soup', 'Beer', 'Diaper', 'Milk', 'IceCream'],
['Soda', 'Coffee', 'Milk', 'Bread'],
['Beer', 'Chips']
]
retail = pd.DataFrame(retail_shopping_basket)# 字典转DF
retail = retail[['ID', 'Basket']]# 选取列
pd.options.display.max_colwidth=100# 设定显示宽度

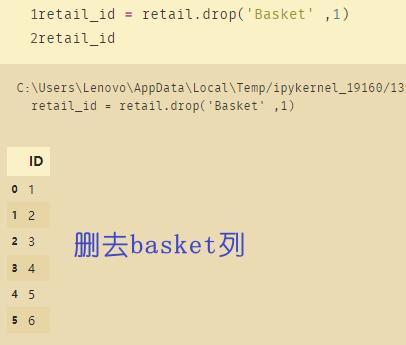
此时retail数据集当中都是字符串组成的,需要转换成为数值的编码:
retail_id = retail.drop('Basket' ,1)
retail_id
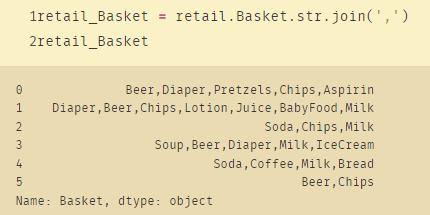
retail_Basket = retail.Basket.str.join(',')
retail_Basket
retail_Basket = retail_Basket.str.get_dummies(',')
retail_Basket
pandas使用get_dummies进行one-hot编码
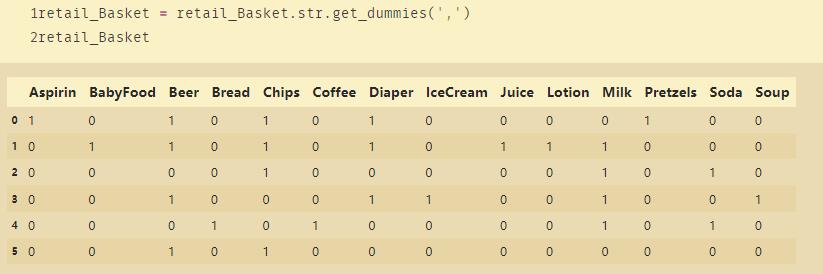
retail = retail_id.join(retail_Basket)
retail

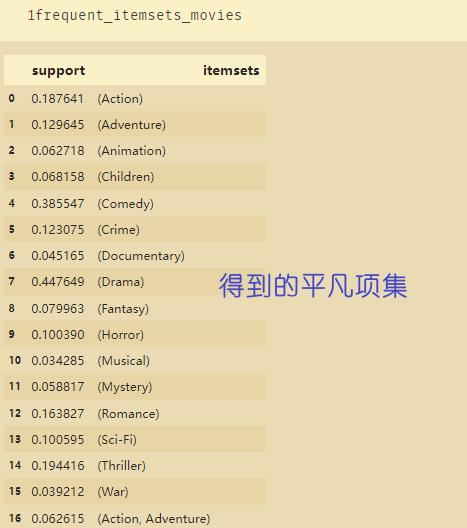
平凡项集:
frequent_itemsets_2 = apriori(retail.drop('ID',1), use_colnames=True)

association_rules(frequent_itemsets_2, metric='lift')
单品的数据就被过滤掉了,是针对二项集来分析的

三、电影题材关联规则
movies = pd.read_csv('ml-latest-small/ml-latest-small/movies.csv')


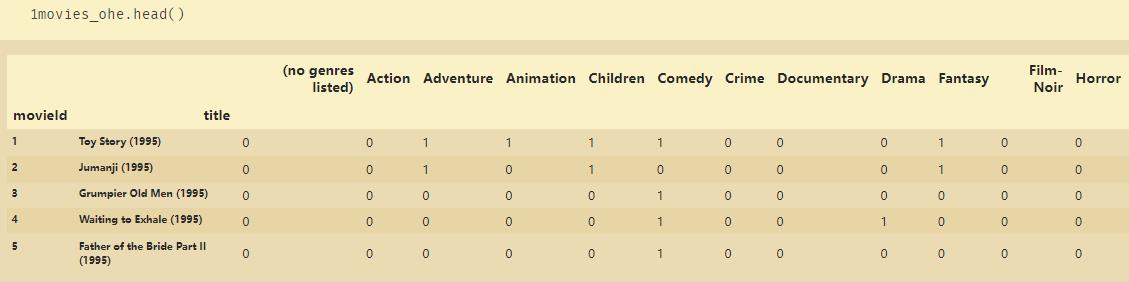
数据中包括电影的名字与电影的类型的标签,第一步还是先转化成独热编码
movies_ohe = movies.drop('genres',1).join(movies.genres.str.get_dummies())

movies_ohe.shape

双层索引:
movies_ohe.set_index(['movieId','title'],inplace=True)
frequent_itemsets_movies = apriori(movies_ohe,use_colnames=True, min_support=0.025)
rules_movies = association_rules(frequent_itemsets_movies, metric='lift', min_threshold=1.25)
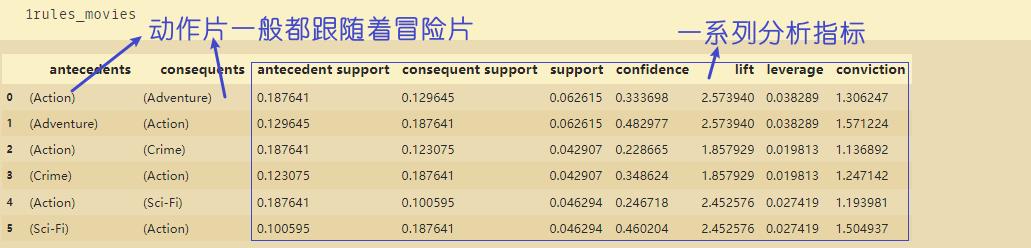
选取关联规则当中提升度大于4的,并且进行降序排序:
rules_movies[(rules_movies.lift>4)].sort_values(by=['lift'], ascending=False)

由上图可知:儿童片和动画片是紧密相关的
选出既是儿童片,又是动画片的:
movies[(movies.genres.str.contains('Children')) & (movies.genres.str.contains('Animation'))]
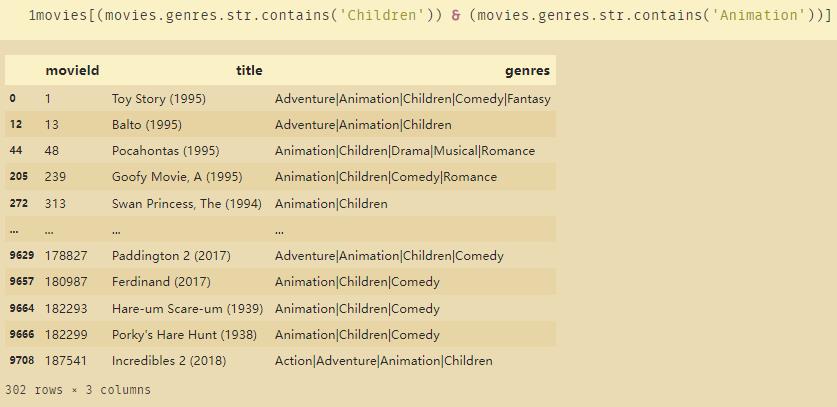
下面代码当中有一个波浪号,意思是取反,相当于not。
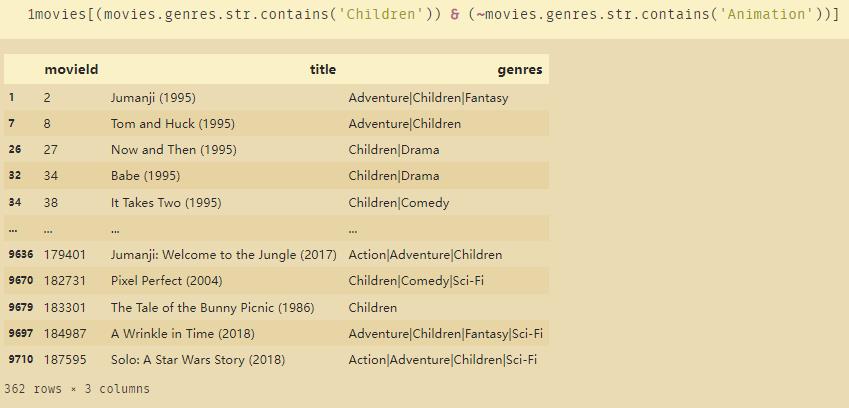
代表的是选出电影类型当中包含儿童片,但是不包含动画片的:
movies[(movies.genres.str.contains('Children')) & (~movies.genres.str.contains('Animation'))]
四、商品出入库历史记录案例
import pandas as pd
import os
import numpy as np
import datetime
导入数据:
ordersdetaildf=pd.read_excel("出入库历史记录.xlsx")
1、数据清洗
去除空格等等,整理数据,规范格式:
ordersdetaildf['商品名称2']=ordersdetaildf['商品名称'].apply(lambda x:x.replace(" ",""))
ordersdetaildf['商品名称2']=ordersdetaildf['商品名称2'].apply(lambda x:x.replace("\\n","").replace("\\\\t\\\\r",""))
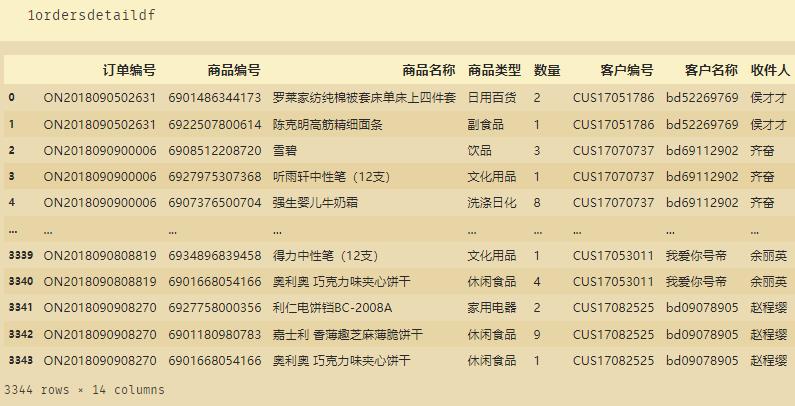
ordetgb=ordersdetaildf.groupby('订单编号',as_index=False)["商品名称"].apply(lambda x:'|'.join(x.values)).reset_index(drop=True)
#替换成|很重要

去除空格:
# 经过excel查询code(a1) unicode=u00A0 不间断空格
ordetgb['商品名称']=ordetgb['商品名称'].astype(str).apply(lambda x:x.replace(u"\\u00A0",""))
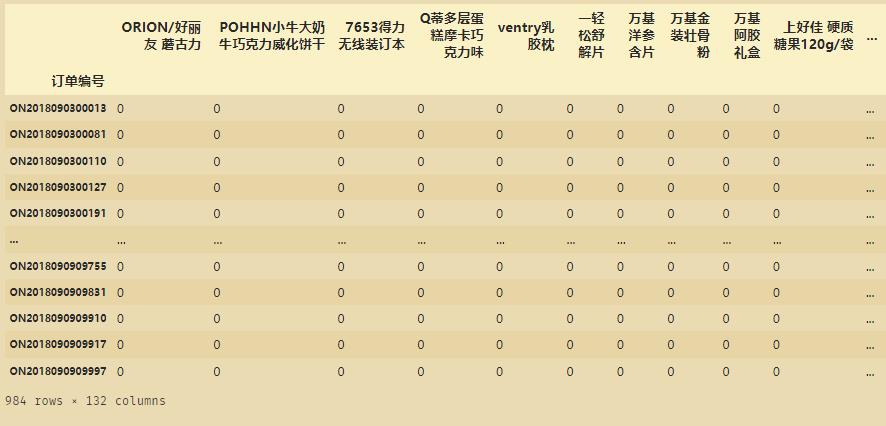
得到独热编码(稀疏矩阵):
ord_ohe= ordetgb.drop('商品名称',1).join(ordetgb.商品名称.str.get_dummies())
ord_ohe.set_index(['订单编号'],inplace=True)
挖掘平凡项集:
frequent_itemsets_ord = apriori(ord_ohe,use_colnames=True, min_support=0.015)

rules_ord = association_rules(frequent_itemsets_ord, metric='lift', min_threshold=2.25)
根据需要进行排序:
rules_ord[(rules_ord.lift>4)].sort_values(by=['lift'], ascending=False)
rules_ord[(rules_ord.lift>40)].sort_values(by=['confidence'], ascending=False)
以上是关于机器学习系列(17)_关联规则的主要内容,如果未能解决你的问题,请参考以下文章