如何用看板工具做任务管理
Posted shineshine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用看板工具做任务管理相关的知识,希望对你有一定的参考价值。
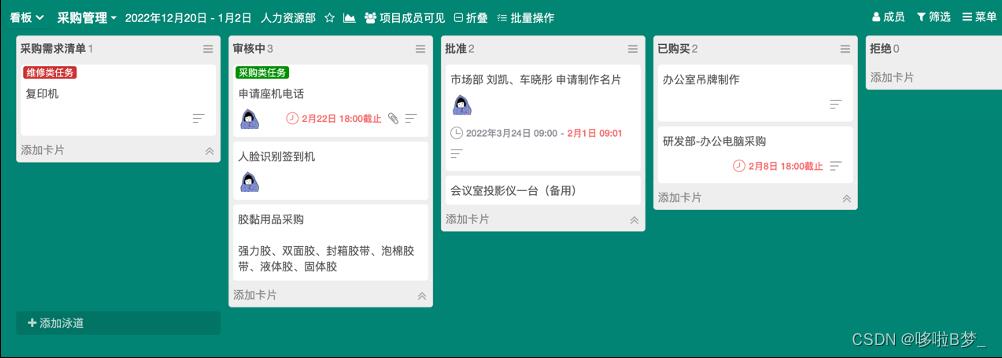
1、首先创建一个任务看板
进入Leangoo系统,使用轻量级项目模板创建一个任务看板。
任务看板内包含:列表和任务卡片,列表一般代表任务流程及状态(可自定义任务流程),一张卡片为一个任务
拖动任务卡片到不同列表,以体现任务的完成状态
 编辑
编辑
2、任务卡片
进入在Leangoo中,任务是以卡片的形式展示,一张卡片代表一个任务,在卡片内可以:
•详细描述任务信息
•设置实际工时和估算工时
•设置任务的开始截止时间及任务到期提醒
•设置任务之间的关联关系,可关联文档、脑图、项目等。
•设置前后置任务
•设置任务卡片完成进度
•可查看卡片历史轨迹信息
•分享任务卡片
•标签为任务分类
•评论并@成员等  编辑
编辑
3、任务分配
•进入看板内,拖拽右侧成员头像至任务卡片上即可完成任务分配
•被分配成员则会收到任务提醒,提醒方式有:微信、邮件及Leangoo系统内部通知
•看板内任务可多人编辑,实时同步,实时更新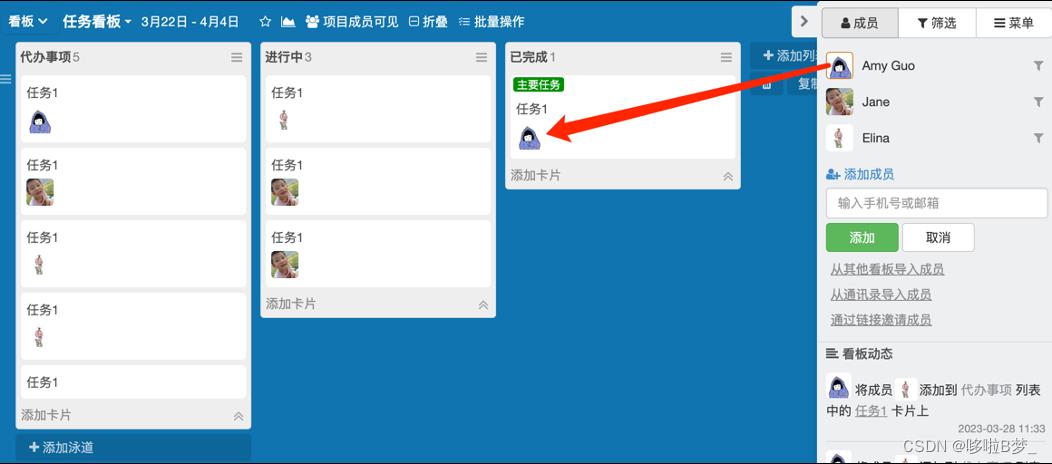 编辑
编辑
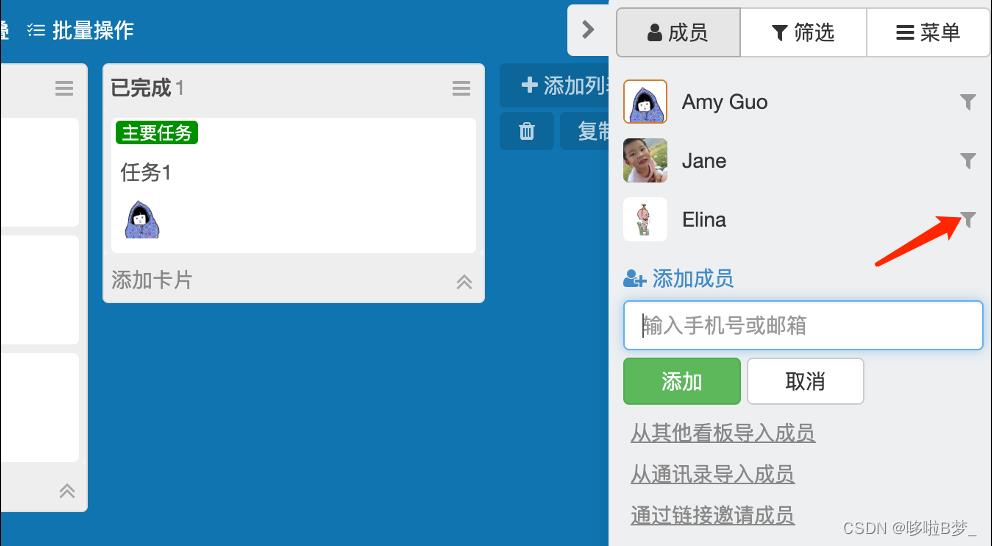
4、看板内成员
创建好看板后,通过看板“成员”为看板添加成员一起共享协作
•可以通过邮箱添加成员,也可以通过链接邀请成员,也可以从其他看板导入成员等多种邀请方式。
•未注册成员系统会自动注册并发送注册信息至邀请邮箱
•可通过成员名称后的“漏斗”以成员筛选任务
 编辑
编辑
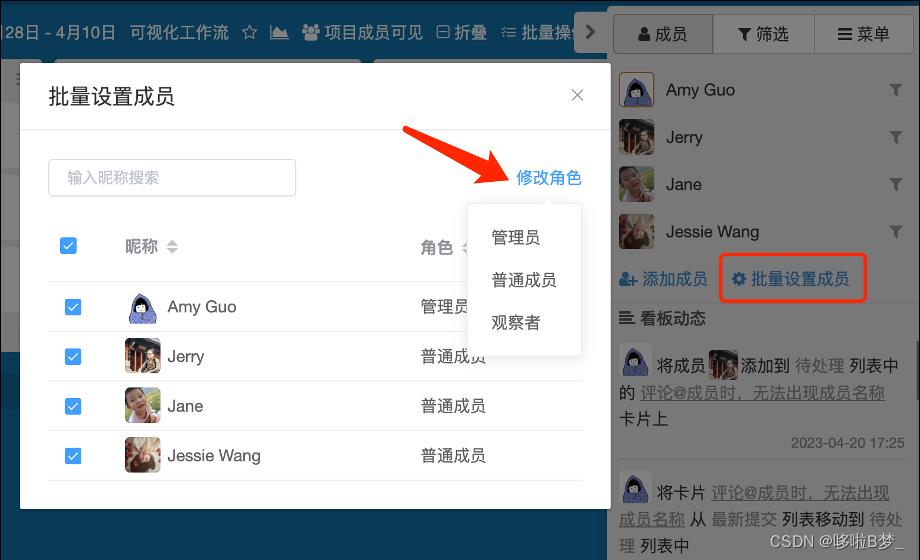
5、批量设置看板内成员权限
目前看板内成员权限分三种,点击右侧成员,可批量设置成员权限。
- 看板管理员:拥有导入导出看板,分享看板和删除归档看板等权限
- 普通成员:拥有修改看板的权限
- 观察者:只能浏览看板内容,没有编辑权限
 编辑
编辑
6、看板内标签、筛选
Leangoo看板内可以通过标签筛选任务。
标签通常用作对任务的分类。
•拖拽标签至任务上即可。
•标签可以自由命名
•勾选标签可通过标签筛选 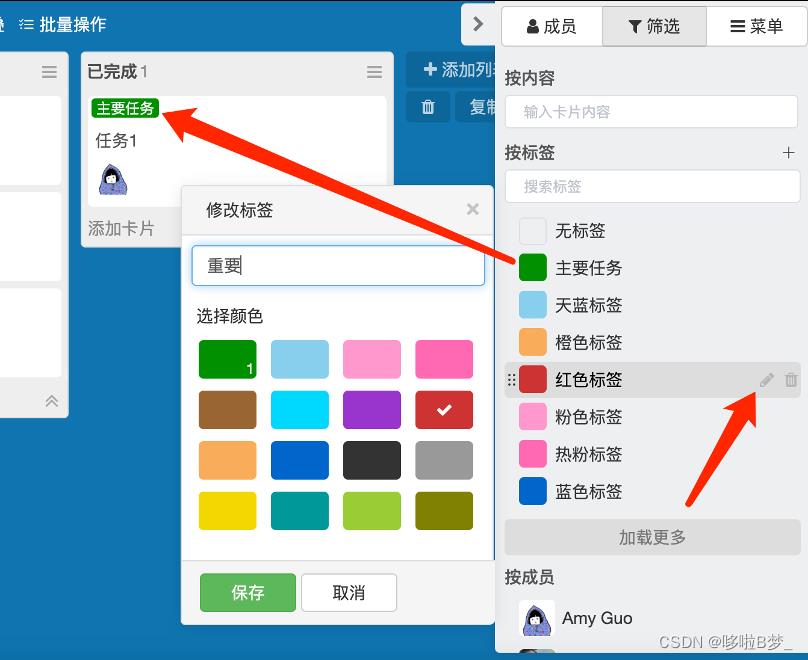 编辑
编辑
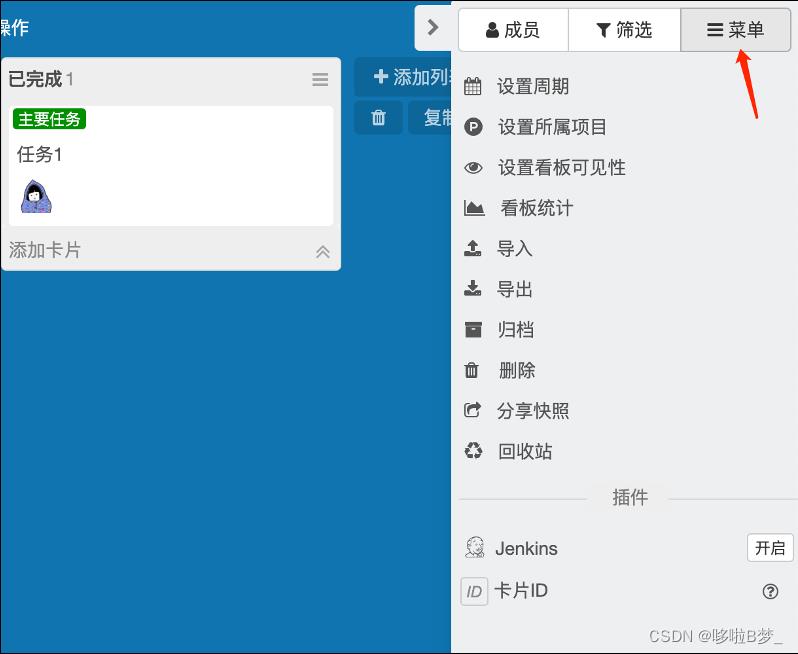
7、看板数据导入导出
看板右侧菜单中,可以自由导入导出看板数据、删除看板、归档看板等等
 编辑
编辑
8、看板内任务分布情况
通过任务分布统计帮助团队快速直观的了解团队成员每个人负责的工作负荷及工作进展状态,帮助团队进行更高效的协作。 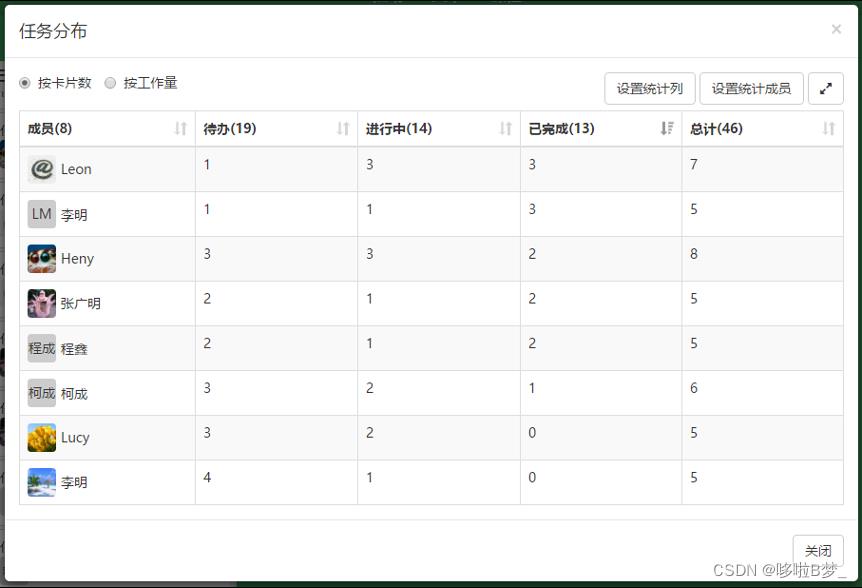 编辑
编辑
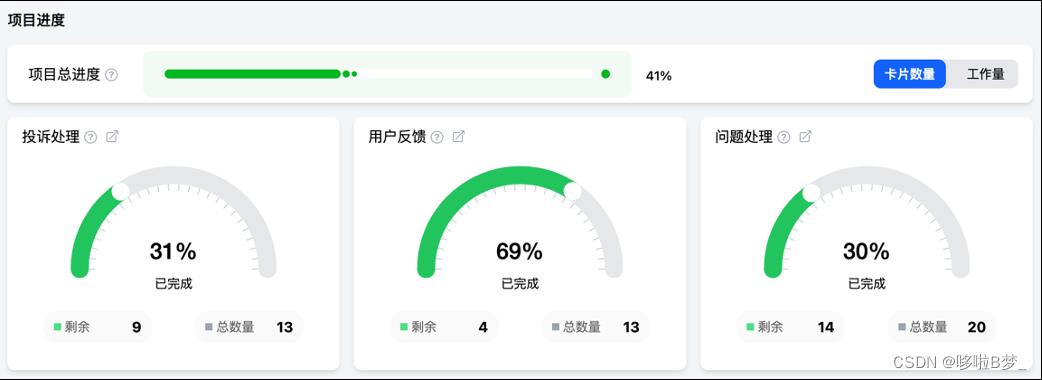
9、项目内看板进度统计
配置好看板信息,即可在统计页面内看到所有项目内所有看板内任务完成情况
 编辑
编辑
10、项目内成员任务数量统计
成员任务数量统计是统计项目成员在该项目中的所有看板中的任务分布情况
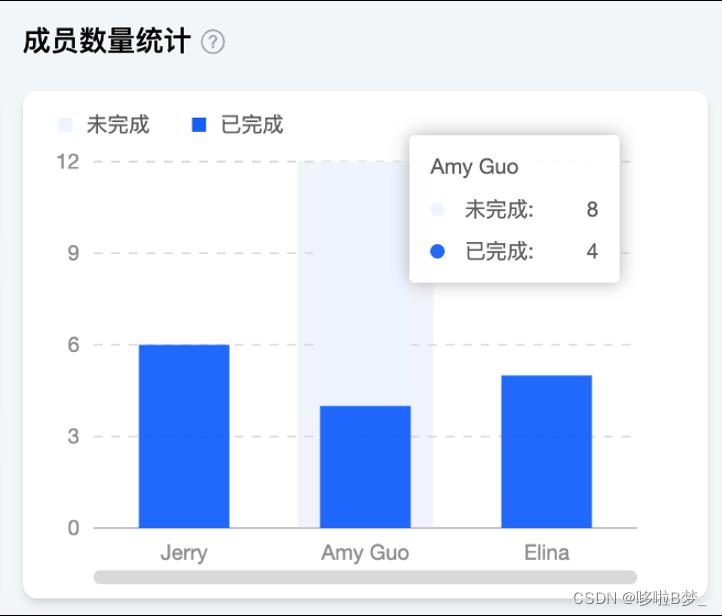 编辑
编辑
11、项目成员工作分布情况
工作分布统计展示项目成员在该项目内的所有看板/脑图中的任务分布情况。
通过工作分布统计帮助管理者快速直观的了解项目成员每个人负责的工作负荷及工作进展状态,帮助团队进行更高效的协作。 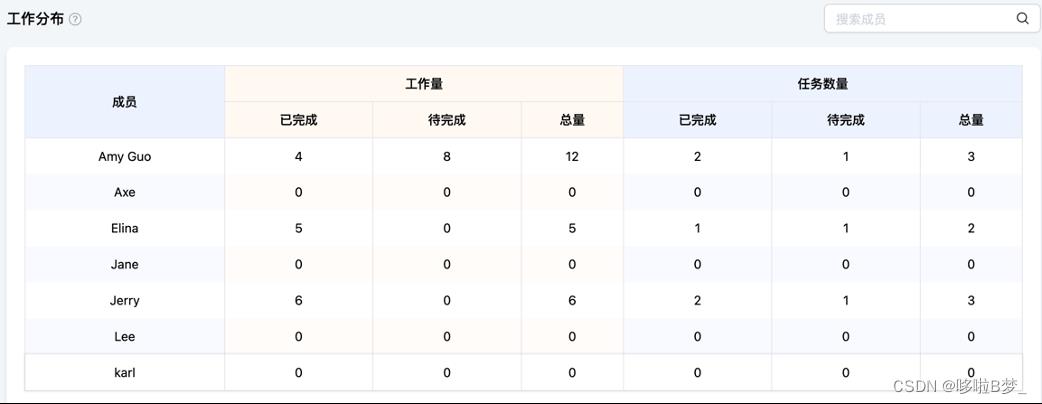 编辑
编辑
12、项目文件管理
Leangoo中提供了文档存储,便于团队沉淀经验、共享资源。
•多人共享项目文件
•实时同步上传
•支持文档、图片、视频等资料上传
•可深度关联工作任务,看板中打开任务卡片,可关联文档。
 编辑
编辑
还有更多使用方法,可以访问www.leangoo.com
[转] 如何用kaldi训练好的模型做特定任务的在线识别
转自:http://blog.csdn.net/inger_h/article/details/52789339
在已经训练好模型的情况下,需要针对一个新任务做在线识别应该怎么做呢?
一种情况是,用已有的声学模型和新训练的语言模型。
ngram-count -text train.txt -order 3 -limit-vocab -vocab wordlist -unk -map-unk "<unk>" -kndiscount -interpolate -lm srilm.o3g.kn.gz
mkdir -p $lang_own cp -r $lang/* $lang_own gunzip -c $lm | utils/find_arpa_oovs.pl $lang_own/words.txt > $lang_own_tmp/oovs.txt || exit 1 gunzip -c $lm | grep -v ‘<s> <s>‘ | grep -v ‘</s> <s>‘ | grep -v ‘</s> </s>‘ | arpa2fst - | fstprint | utils/remove_oovs.pl $lang_own_tmp/oovs.txt | utils/eps2disambig.pl | utils/s2eps.pl | fstcompile --isymbols=$lang_own/words.txt --osymbols=$lang_own/words.txt --keep_isymbols=false --keep_osymbols=false | fstrmepsilon | fstarcsort --sort_type=ilabel > $lang_own/G.fst utils/validate_lang.pl --skip-determinization-check $lang_own || exit 1;最后生成新的语言模型在graph_own_dir
graph_own_dir=$model_dir/graph_own utils/mkgraph.sh $lang_own $model_dir $graph_own_dir || exit 1;
第二种情况是,利用一个新的字典和已有的声学模型
utils/prepare_lang.sh --phone-symbol-table $lang/phones.txt $dict_own "<SPOKEN_NOISE>" $lang_own_tmp $lang_own新生成的lang就会在lang_own目录下。--phone-symbol-table选项十分重要,它保证了新lexicon里面的音素和原来识别器里面的音素是对应的。最后再生成语言模型。
graph_own_dir=$model_dir/graph_own
utils/mkgraph.sh $lang_own $model_dir $graph_own_dir || exit 1;
第三种情况是,字典语料都不同,语言模型也重新训练。这个时候从准备字典开始就要重新做。
./local/general_prep_dict.sh ./tv--> reading tv4/dict/extra_questions.txt
--> ERROR: phone "X5" is not in {, non}silence.txt (line 120, block 17)
--> ERROR validating dictionary directory tv4/dict (see detailed error messages above)
Checking tv3/dict/extra_questions.txt ...
--> reading tv3/dict/extra_questions.txt
--> tv3/dict/extra_questions.txt is OK
--> SUCCESS [validating dictionary directory tv3/dict]
Phone appears in the lexicon but not in the provided phones.txt: X5
以上是关于如何用看板工具做任务管理的主要内容,如果未能解决你的问题,请参考以下文章