python爬取网站视频保存到本地
Posted 有趣的Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬取网站视频保存到本地相关的知识,希望对你有一定的参考价值。
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: Woo_home
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.co-m/noteshare?id=3054cce4add8a909e784ad934f956cef
安装库
该示例使用到的库有requests、lxml、re,其中re是python自带的,所以无需安装,只需安装requests和lxml库即可
安装命令如下:
pip install requests
pip install lxml
分析网页数据
打开一个视频网页如下:
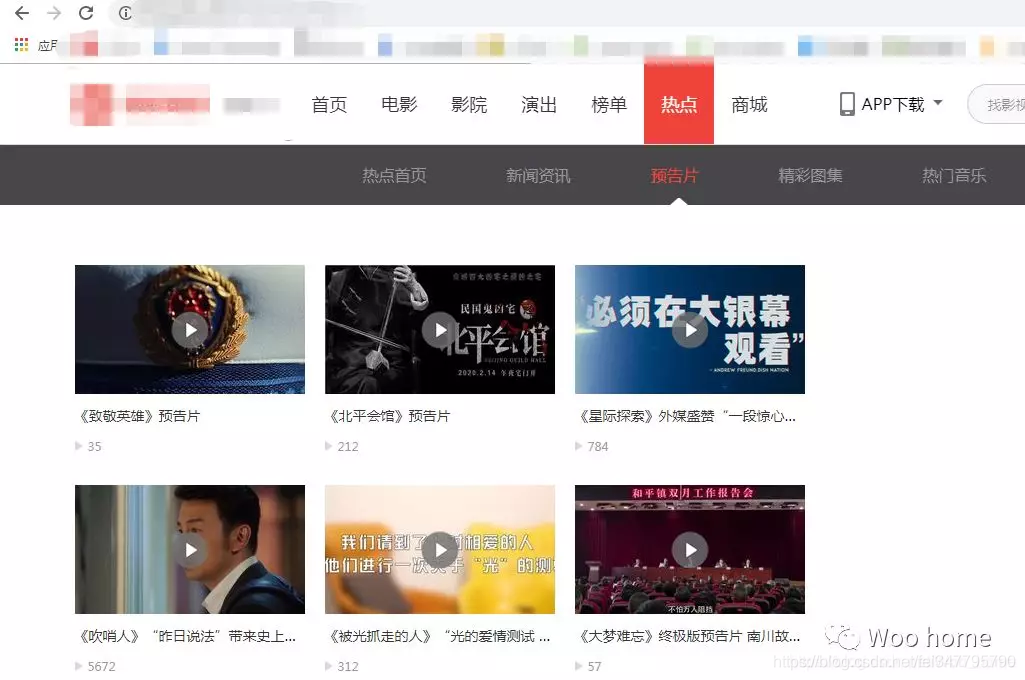
右键进行开发者模式,点击一个视频右键,点击Open in new tab
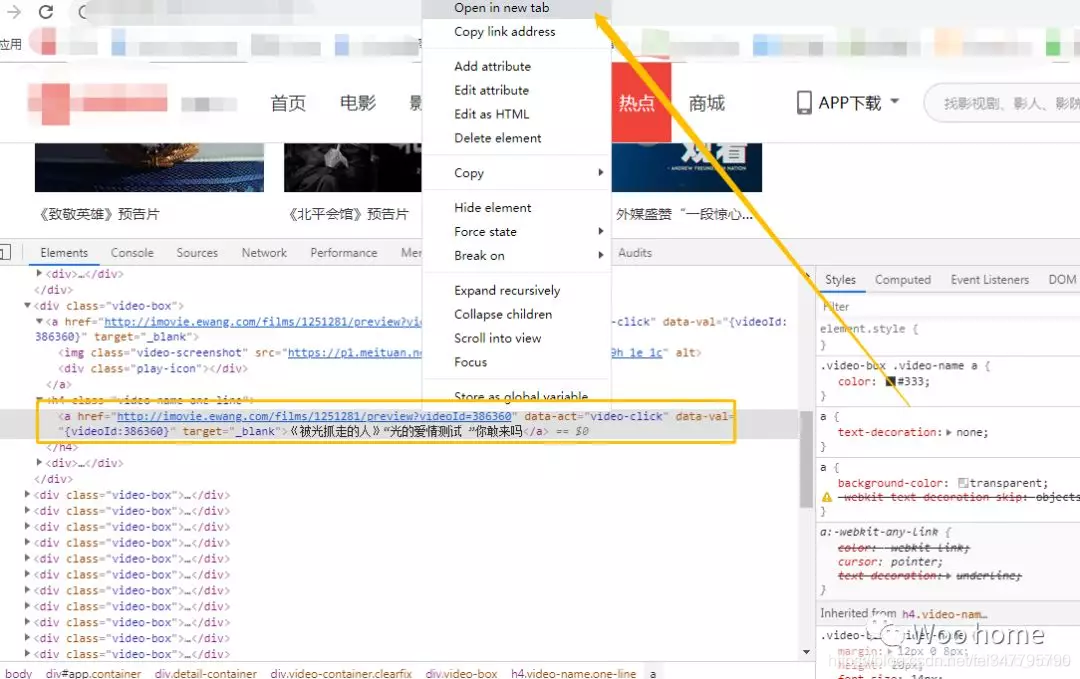
ok,可以打开
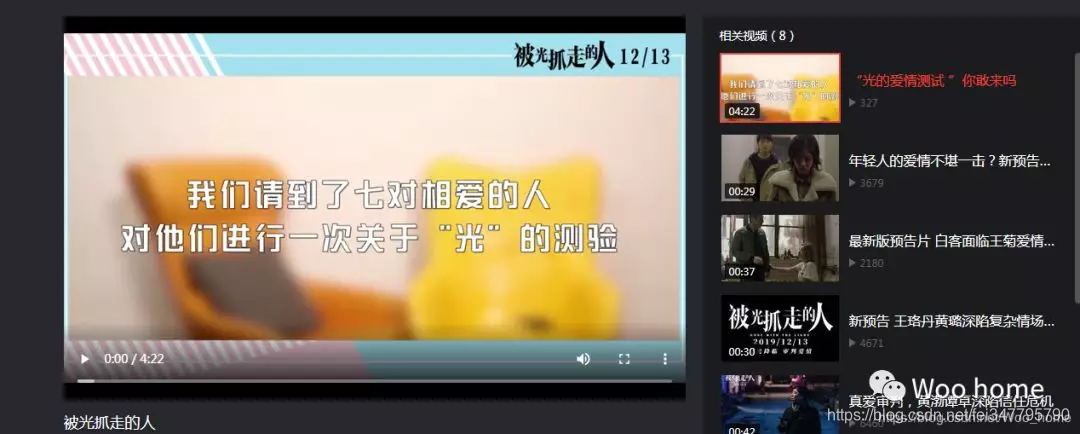
代码实现
先导入要使用的库
import requests
from lxml import etree
import re
拿到网站的url

获取User-Agent

发起请求


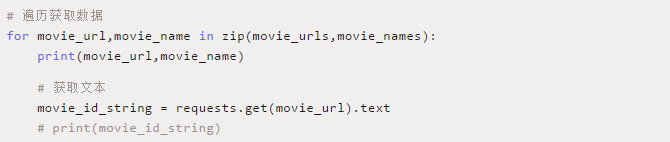

保存数据

下载的视频已经保存在文件夹中

以上是关于python爬取网站视频保存到本地的主要内容,如果未能解决你的问题,请参考以下文章
网络爬虫在爬取网页时,响应头没有编码信息...如何解决保存在本地的乱码问题?
pyhton爬取一二级网站页面,并将爬取的图片信息保存到本地