java爬虫爬取b站视频分享iframe代码并保存10000条数据到数据库
Posted qq1913284695
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java爬虫爬取b站视频分享iframe代码并保存10000条数据到数据库相关的知识,希望对你有一定的参考价值。
需求:自己开发的一个视频网站不想把自己上传视频和封面图片,因为一个一个上传视频文件和封面图片还是很费时间的,想着直接抓取点b站上的视频iframe分享的链接和图片链接到我的数据库中,这样网站就很快就填充起来了,看着就丰满多了(单纯是为了让我开发的系统看着有数据丰满点好看)。
思路分析:爬取大量的iframe代码和视频标题以及视频封面照片的链接保存到数据库就行。当然如果您是要爬取后把视频文件也下载到自己电脑的话,也可以用java代码实现的哦。
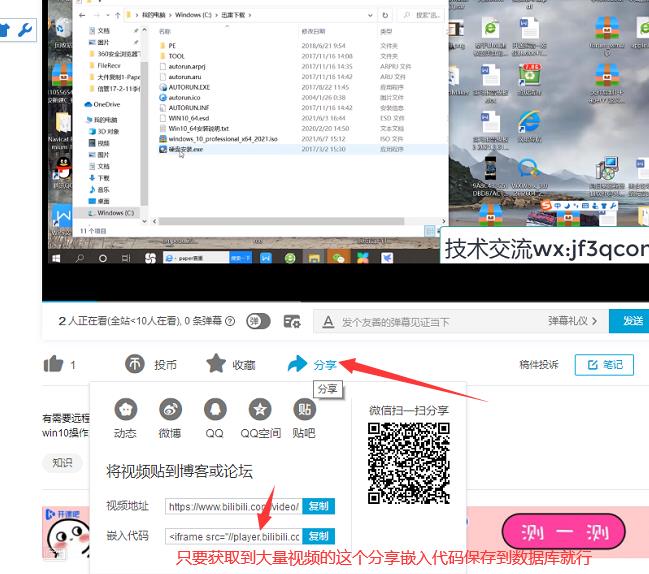
实际操作:
1、先用浏览器打开b站,开发者模式(浏览器开发者模式可以f12打开)进入network面板分析下数据,一般网站都是前后分离的,页面上的动态数据一般都是发送ajax请求后台接口获取到的(当然也有那种提前渲染的,那种不在咱爬取的行列
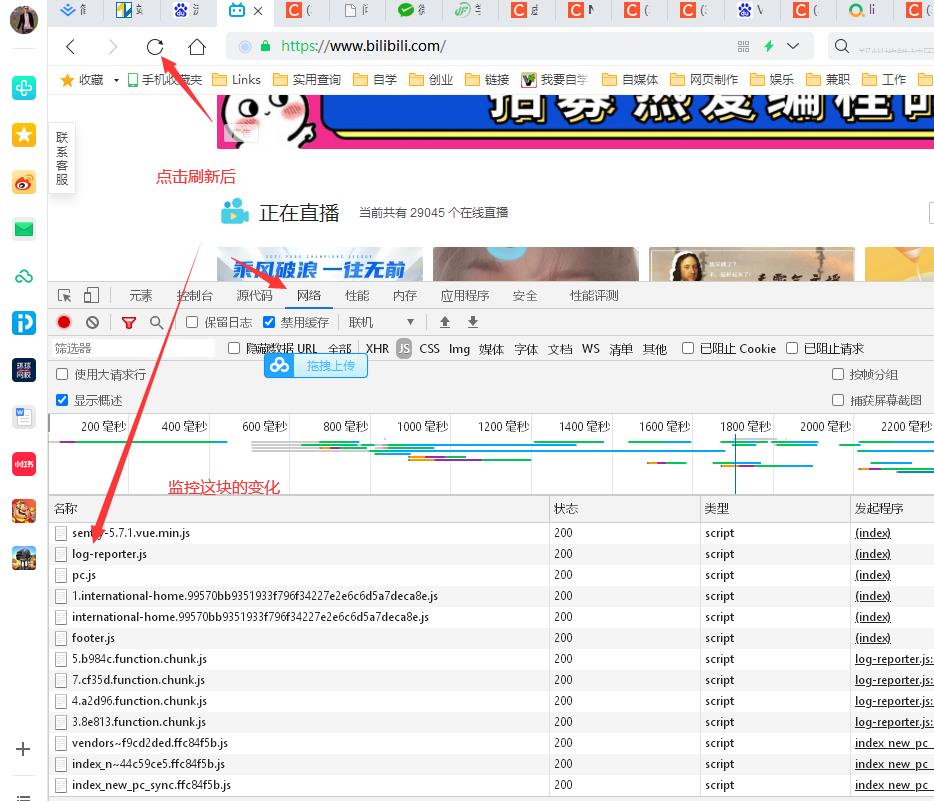
2、最好是找那种带分页的页面去分析爬取数据。
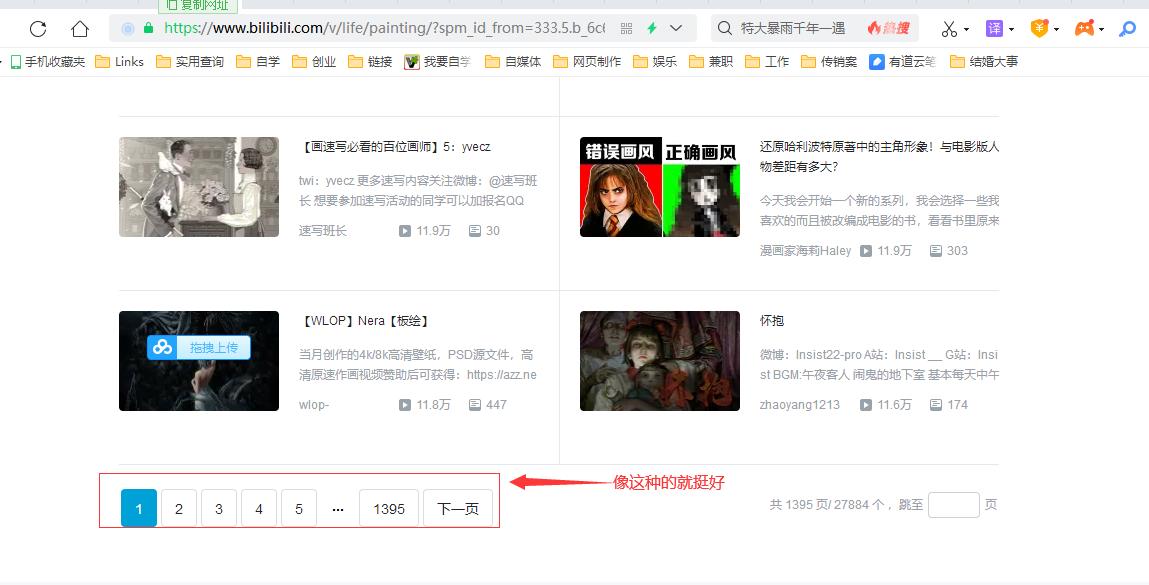
3、点击一个一个的请求分析请求头和响应数据(主要是看响应,找那种返回是json格式的)
我这里找到一个这样的接口
https://api.bilibili.com/x/web-interface/web/channel/multiple/list?channel_id=17683&sort_type=hot&offset=761597855_1626694963&page_size=30
4、开始写java代码
public static void main(String[] args) throws Exception {
//1加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2获取连接
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useunicode=true&useSSL=FALSE&serverTimezone=UTC", "root", "123456");
//3获得语句执行者
Statement st = conn.createStatement();
String offset="761597855_1626694963";
long num = 0;
for(int page=1; page<3500; page++) {
System.out.println("页码:" + page);
//请求获取结果
String result = HttpClientUtil.getByJsonParam("https://api.bilibili.com/x/web-interface/web/channel/multiple/list?channel_id=17683&sort_type=hot&offset="+offset+"&page_size=30");
System.out.println(result);
ObjectMapper objectMapper = new ObjectMapper();
HashMap<String, Object> resultMap = objectMapper.readValue(result, HashMap.class);
HashMap<String, Object> dataMap = (HashMap<String, Object>)resultMap.get("data");
//获取下一页数据
offset= (String) dataMap.get("offset");
ArrayList<HashMap<String, Object>> dataList = (ArrayList<HashMap<String, Object>>)dataMap.get("list");
for(int i=0; i<dataList.size(); i++) {
num++;
HashMap<String, Object> itemMap = dataList.get(i);
int user_id=1;
//aid
String aid = String.valueOf(itemMap.get("id"));
//System.out.println(aid);
//bvid
String bvid =(String)itemMap.get("bvid");
//System.out.println(bvid);
//cid
//String cid = String.valueOf(itemMap.get("cid"));
//System.out.println(cid);
String vsrc = "//player.bilibili.com/player.html?aid=" + aid + "&bvid=" + bvid + "&page=1&high_quality=1&danmaku=0";
System.out.println(vsrc);
//图片
String v_image = (String)itemMap.get("cover");
System.out.println(v_image);
//标题
String vname = (String)itemMap.get("name");
System.out.println(vname);
//描述
//String descript = (String)itemMap.get("desc");
//System.out.println(descript);
/*作者信息
HashMap<String, Object> owner = (HashMap<String, Object>)itemMap.get("owner");
//mid
String mid = String.valueOf(owner.get("mid"));
System.out.println(mid);
//name
String name = (String)owner.get("name");
System.out.println(name);
//face
String face = (String)owner.get("face");
System.out.println(face);
*/
String itemSql = "INSERT video (vid, vname, vsrc, userid, praise, get_icon, type_id, v_image, play_num, tags, vtime) VALUES ('" + num + "','" + vname + "', '" + vsrc +"', '" + 1 + "', '" + 0 + "', '" + 0 + "', '" + (int)(1+Math.random()*(9-1+1)) + "', '" + v_image + "', '" + (int)(1+Math.random()*(100000-1+1)) + "', '" + "NULL" + "', now()) ";
//System.out.println(itemSql);
//st.executeUpdate(itemSql);
System.out.println(itemSql);
try {
st.executeUpdate(itemSql);
}
catch (Exception e){
continue;
}
System.out.println("//=========================================");
}
}
st.close();
conn.close();
}
5、运行第4步的代码就可以把数据轻松保存到数据库(运行程序的时间可能有点长)
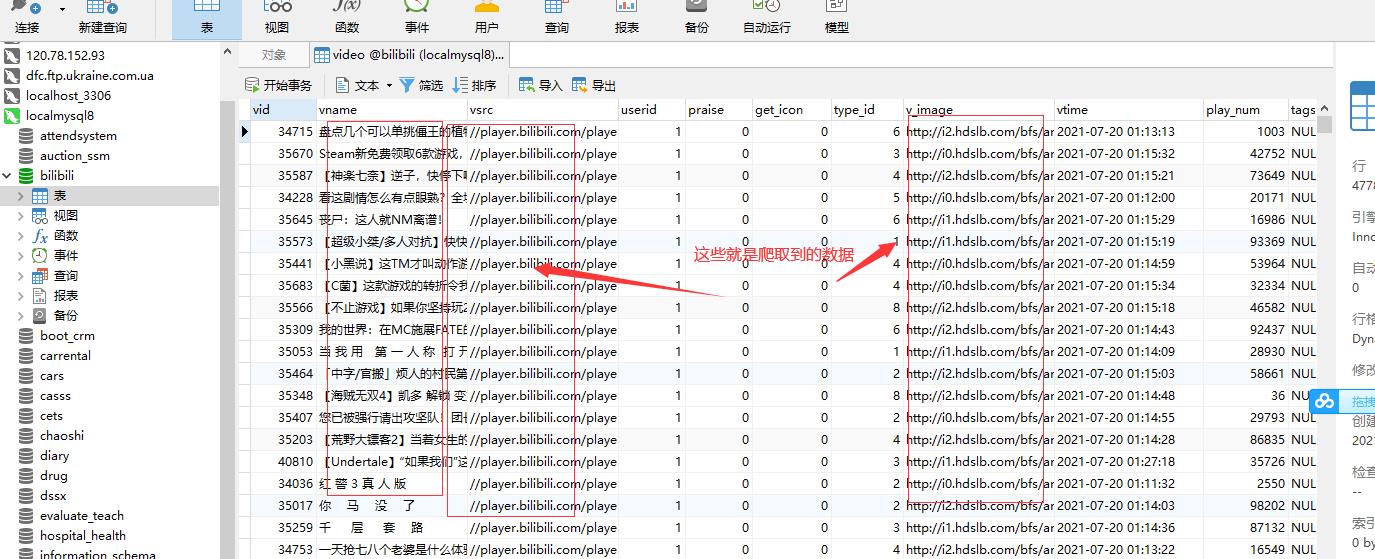
6、最后直接运行我的系统后的效果:
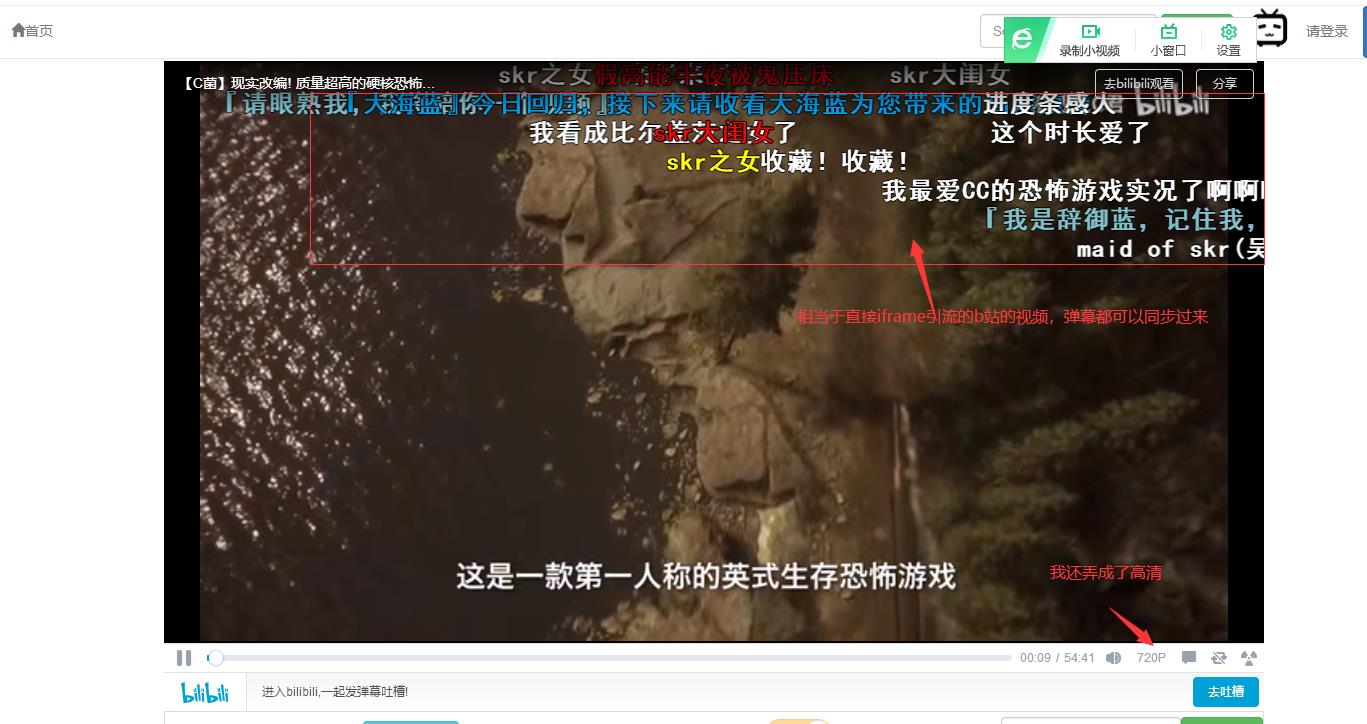
有什么不懂得再q我1913284695。
以上是关于java爬虫爬取b站视频分享iframe代码并保存10000条数据到数据库的主要内容,如果未能解决你的问题,请参考以下文章