Python爬虫爬取各大热门短视频平台视频
Posted 爬虫小白0514
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫爬取各大热门短视频平台视频相关的知识,希望对你有一定的参考价值。
1、开发工具
Python3.9
requests库
其他一些Python内置库
pycharm
2、第三方库
安装第三方库
pip install requests
3、实现思路
1、利用tkinter库实例化一个GUI界面,包含提示框、输入框、选择按钮、功能按钮。
2、用requests发送get请求,获得下载链接
3、将下载到的文件保存到本地。
4、实现效果
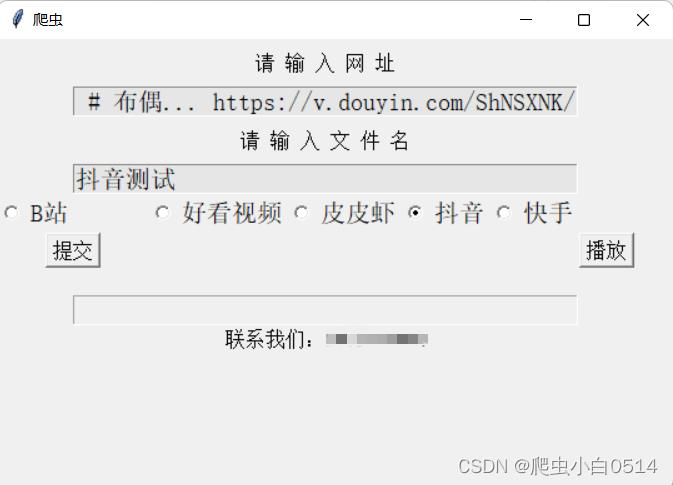


5、实现过程
1、B站视频爬虫
import requests
import re
import os
#判断是否存在文件夹video,不存在,则创建一个
filename='video\\\\'
if not os.path.exists(filename):
os.mkdir(filename)
#定义一个爬虫函数,供主函数调用
def UrlCrawler(url,name):
#定制请求头
headers =
"cookie":"buvid3=0D3353AC-5B77-680A-697F-8B66493826D160198infoc; b_nut=1670493160; CURRENT_FNVAL=4048; _uuid=AA102510B8-6113-12F5-10674-C7E67642D65561585infoc; rpdid=|(YukRR|mR|0J'uY~|RmJuYk; i-wanna-go-back=-1; fingerprint=9a9c4cc60b4c3b41bce4cf46c57c55ea; buvid_fp_plain=undefined; buvid4=60372B7A-A671-65D8-6993-2FB5D6E3B2CD61117-022120817-lih1xoB%2FrWiTqxe5epW4Zg%3D%3D; buvid_fp=9a9c4cc60b4c3b41bce4cf46c57c55ea; nostalgia_conf=-1; DedeUserID=3493087921833988; DedeUserID__ckMd5=f79b1c5b37110e69; b_ut=5; bp_video_offset_3493087921833988=undefined; PVID=1; SESSDATA=9b3f3db2%2C1691137529%2C03f5b%2A22; bili_jct=5587e773eeb7161f147d72322112dd01; b_lsid=46D44D61_18620C2A453; innersign=1; sid=nxtxooce",
"origin":"https://www.bilibili.com",
"user-agent":"Mozilla/5.0 (Linux; android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36",
try:
requests.head(url=url)
except requests.exceptions.ConnectionError:
return "Error"
else:
#从页面源代码中解析出视频地址
response = requests.get(url=url,headers=headers)
date = re.findall('readyVideoUrl":"(.*?)","readyDuration', response.text)[0]
date1=requests.get(url=date,headers=headers).content
#将爬取到的数据写入文件
with open('video\\\\'+name+'.mp4',mode='wb') as f:
f.write(date1)
2、抖音视频爬虫
import requests
import re
import os
#新建文件夹
filename='video\\\\'
if not os.path.exists(filename):
os.mkdir(filename)
#定义函数,供主函数调用
def TikTok(url,name):
response = requests.get(url=url)
response = response.url
#检查主函数输入的链接是否正确
try:
id = re.findall('video/(.*)/\\?', response)[0]
except IndexError:
return 1
# https://www.douyin.com/video/7197438641520610595
print(id)
Url = 'https://www.douyin.com/video/' + id
#定制请求头
headers =
'cookie': 'douyin.com; ttcid=7a9f94f5337c4fb6a4937e5937748bb021; passport_csrf_token=a0ac1ccb642a36adda5944f1c015d48e; passport_csrf_token_default=a0ac1ccb642a36adda5944f1c015d48e; s_v_web_id=verify_lcbu5s5w_28wEiVmM_z3Vd_40ES_B51w_NzAlySlNxpX2; xgplayer_user_id=242308523073; ttwid=1%7CC40qHPAKUiS-rZzMjoNnaRQLVAmjwFKkQYJKPFgoP8w%7C1675328733%7C7c9d6834b4963ac8874725a61b87e3dd9557431c57f3f7751fac875fdc5db078; d_ticket=3c3e91316b0d2f2293d28fe6652d905cc7869; passport_assist_user=CkEfjpnNrq_dwTxeUvZDgvxiJJGX4vK_V2bvkG4hXT2Y93RD7N7Wpv9DwPWJ2-RIiM6ryeR0t7a7jrfKZx1645n2bRpICjwfL4B7J61soinEUkLo0zIVrDu52cNfrSTRckp__Zh7a6qAaiefB0n-jw85LEuN7fTxx3zgjB_uycKsyg4Qrb-oDRiJr9ZUIgEDxmngyQ%3D%3D; n_mh=EyHH0OrPqAYMNqnG7-FHeaRIMyHdxcz5bczy1ihDzJY; sso_auth_status=44d73d0e0c92093e78edc25f7dbd4ffe; sso_auth_status_ss=44d73d0e0c92093e78edc25f7dbd4ffe; sso_uid_tt=ace0d555e37a065789e9cfd86cc68d49; sso_uid_tt_ss=ace0d555e37a065789e9cfd86cc68d49; toutiao_sso_user=4410a2614fa77ef6cbbe4c90d8319abe; toutiao_sso_user_ss=4410a2614fa77ef6cbbe4c90d8319abe; sid_ucp_sso_v1=1.0.0-KDIwNGI4ZjQzMDZjZWY3ZjVmOWIxNTExNjQwOTcyMmMzNTA4MDE4OTEKHwjohYGDiY3dAxD47_6eBhjvMSAMMISOpJQGOAJA8QcaAmxmIiA0NDEwYTI2MTRmYTc3ZWY2Y2JiZTRjOTBkODMxOWFiZQ; ssid_ucp_sso_v1=1.0.0-KDIwNGI4ZjQzMDZjZWY3ZjVmOWIxNTExNjQwOTcyMmMzNTA4MDE4OTEKHwjohYGDiY3dAxD47_6eBhjvMSAMMISOpJQGOAJA8QcaAmxmIiA0NDEwYTI2MTRmYTc3ZWY2Y2JiZTRjOTBkODMxOWFiZQ; odin_tt=07cb42e67dc0b9fa65d040b535cc327a7a483b2242828f4c84668fe6a4fcae69b5a3ef54e4dfbdba322ef19aab7c1e73a008921d15e1a48378be1dd2dfa28fb1; passport_auth_status=61c50bbfa9400bbf2fef96292e2465be%2Cded43c4315dd52db289d582351d64d63; passport_auth_status_ss=61c50bbfa9400bbf2fef96292e2465be%2Cded43c4315dd52db289d582351d64d63; uid_tt=159fc791276b24a5528a79ac5776dcf7; uid_tt_ss=159fc791276b24a5528a79ac5776dcf7; sid_tt=748a279e94b51380eefa350d30df8041; sessionid=748a279e94b51380eefa350d30df8041; sessionid_ss=748a279e94b51380eefa350d30df8041; _tea_utm_cache_2018=undefined; LOGIN_STATUS=1; store-region=cn-gs; store-region-src=uid; sid_guard=748a279e94b51380eefa350d30df8041%7C1675606018%7C5183990%7CThu%2C+06-Apr-2023+14%3A06%3A48+GMT; sid_ucp_v1=1.0.0-KGFjZTk1YjdlZTQzZjhjMmM0NDM4MDYxMGExNmJiNTQyYjBjZDZiYTEKGQjohYGDiY3dAxCC8P6eBhjvMSAMOAJA8QcaAmhsIiA3NDhhMjc5ZTk0YjUxMzgwZWVmYTM1MGQzMGRmODA0MQ; ssid_ucp_v1=1.0.0-KGFjZTk1YjdlZTQzZjhjMmM0NDM4MDYxMGExNmJiNTQyYjBjZDZiYTEKGQjohYGDiY3dAxCC8P6eBhjvMSAMOAJA8QcaAmhsIiA3NDhhMjc5ZTk0YjUxMzgwZWVmYTM1MGQzMGRmODA0MQ; download_guide=%223%2F20230205%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAbAE0Tv5yvVMPsAjb-4wSSB90utPobsmULQ_7kgLejFDqnfufpNzDNwIfkvJpjuCt%2F1675699200000%2F1675620287678%2F0%2F1675647531415%22; SEARCH_RESULT_LIST_TYPE=%22single%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAbAE0Tv5yvVMPsAjb-4wSSB90utPobsmULQ_7kgLejFDqnfufpNzDNwIfkvJpjuCt%2F1675699200000%2F1675649307074%2F1675649217197%2F0%22; live_can_add_dy_2_desktop=%220%22; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1676254485724%2C%22type%22%3A1%7D; __ac_nonce=063e3575c005659758d70; __ac_signature=_02B4Z6wo00f01D6bw0AAAIDBLsUmeUz5Ijg-u8fAAGxMkIVlgPVhkXvACKDrW5PQhox9NT7.sU9JfmICX4vwHkzh6YJTURiVvfV0V6JSqJjgtexaAwvibswH5m4jxG-hbyvx.CQFY7vWHr9Obb; passport_fe_beating_status=true; csrf_session_id=7b1abe19e2b6358087568b75dd1a0f95; strategyABtestKey=%221675844690.634%22; home_can_add_dy_2_desktop=%221%22; msToken=GJXwPYvB3xxwqGpTA9SHiEyyNOtqkIOLQ-aC53WzuItS77HThruQXqUa8KWSorSeTMCWREe_-H06gJ1D4iOk4wV1iOiJT6wRTyo_nTX7c129ED0TB2BjmeLdw5qIWaQ=; msToken=6p8d3ygLZuKLiISQm_63XijKvLSI0sqW04sHI1LzOhZLbRhIaYsqS59QJwZs6y6eEmEYSAuTNpmz9BhVG0t5I1LuUvaWbBxZyrCjlItMH9yZm2RaYk9ZonDx62JygVw=; tt_scid=2FhmuwuvP-leuEyOg46jFNIcPED5l4jUxFsh3H9PwiHLvTImQ1lgmXM5N3.33RFac36f',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78',
response = requests.get(url=Url, headers=headers)
date = response.text
#解析重定向后的地址
try:
html_date = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script', date)[0]
except IndexError:
return 1
html_date = requests.utils.unquote(html_date)
try:
date1=re.findall('playAddr(.*?),',html_date)[0]
#解析出视频地址
video_url='https:'+re.findall('"src":"(.*?)',date1)[0]
except IndexError:
return 1
print(video_url)
video = requests.get(url=video_url, headers=headers)
date1 = video.content
with open('video\\\\' + name + '.mp4', mode='wb') as f:
f.write(date1)
return 0
3、爬取快手
import requests
import re
import os
filename='video\\\\'
if not os.path.exists(filename):
os.mkdir(filename)
def kuaishou(url,name):
#解析视频链接中的关键字
judgement_date=re.findall('//(.*?).kuaishou.com',url)[0]
print(judgement_date)
#通过关键字判断地址来源(pc端,Android端)
if judgement_date=='v':
headers=
'Cookie':'did=web_c449a2a18b2b6ce9264294f6ae305723; didv=1675675109000',
'Host':'v.kuaishou.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78',
#解析重定向后的地址 reresponse=requests.get(url=url,headers=headers)
url1=reresponse.url
url2=re.findall('photo(.*)',url1)[0]
#拼接url url3='https://www.kuaishou.com/short-video'+url2+'&utm_source=app_share&utm_medium=app_share&utm_campaign=app_share&location=app_share'
headers1 =
'Cookie':'kpf=PC_WEB; clientid=3; did=web_c449a2a18b2b6ce9264294f6ae305723; didv=1675675109000; kpn=KUAISHOU_VISION',
'Host':'www.kuaishou.com',
'Referer':'https://kphm5nf3.m.chenzhongtech.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78',
reresponse=requests.get(url=url3,headers=headers1)
date=re.findall('"representation":(.*?)"backupUrl":',reresponse.text)[0]
date=re.findall('"url":"(.*?)",',date)[0]
video_url=date.encode('utf-8').decode('unicode_escape')
headers2=
'origin':'https://www.kuaishou.com',
'referer':'https://www.kuaishou.com/short-video/3xwrthmgyqg3fvk?fid=0&cc=share_copylink&followRefer=151&shareMethod=TOKEN&docId=9&kpn=NEBULA&subBiz=BROWSE_SLIDE_PHOTO&photoId=3xwrthmgyqg3fvk&shareId=17357027357264&shareToken=X-34jhKPf33QT2fT&shareResourceType=PHOTO_OTHER&userId=3x64pacztgf3z2q&shareType=1&et=1_i%2F2001957724826908914_sl6508bl%24s&shareMode=APP&originShareId=17357027357264&appType=21&shareObjectId=5204190936495876828&shareUrlOpened=0×tamp=1675943654763&utm_source=app_share&utm_medium=app_share&utm_campaign=app_share&location=app_share',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78',
date1=requests.get(url=video_url,headers=headers2)
date1 = date1.content
with open('video\\\\' + name + '.mp4', mode='wb') as f:
f.write(date1)
elif judgement_date=='www':
headers =
'Cookie': 'kpf=PC_WEB; clientid=3; did=web_c449a2a18b2b6ce9264294f6ae305723; didv=1675675109000; userId=3303107795; kpn=KUAISHOU_VISION; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqAB4kEeE5ZGYsgUmcOaQwDSehsaKGZt2r70Wor6gLe3oXplBL9DZkFXFF8OTo3xCjXuELSpsclmnaq5YJ5qogAv97vzwiopbY7iv0Z4exgMIuQK2nxD4cabvEFGNJdUtnfahJkQpp8zZko5-oACQKxUfhQZowUpqxEByX1x8SkRi6dX17oHOaNeGjul_YRT7g4h6rrh_QoMidetWqPNzUiHVxoSsguEA2pmac6i3oLJsA9rNwKEIiBRsnjw8H54hs6pJjw4Yj19heswDBgDRePckr2ppBA8ECgFMAE; kuaishou.server.web_ph=d031276ae48aadaed85f1733fb5804924f4e',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78',
url = 'https://www.kuaishou.com/f/X4WR6tV40LEX1N6'
# https://v.kuaishou.com/JeArJH
response = requests.get(url=url, headers=headers)
date = response.url
response1 = requests.get(url=date, headers=headers)
html_date = response1.text
html_date = re.findall('"representation":(.*?)"backupUrl"', html_date)[0]
html_date = re.findall('"url":"(.*?)",', html_date)[0]
video_url = html_date.encode('utf-8').decode('unicode_escape')
headers1 =
'origin': 'https://www.kuaishou.com',
'range': 'bytes=0-',
'referer': 'https://www.kuaishou.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78',
date1 = requests.get(url=video_url, headers=headers1)
date1 = date1.content
with open('video\\\\' + name + '.mp4', mode='wb') as f:
f.write(date1)
4、爬取皮皮虾
import requests
import re
import os
filename='video\\\\'
if not os.path.exists(filename):
os.mkdir(filename)
def pipixia(url, name):
print(url)
#请求头信息随时更新
headers =
"cookie": "_ga=GA1.2.819352039.1675836585; _gid=GA1.2.815125706.1675836585; MONITOR_WEB_ID=50071578-68a0-493a-8db2-3eb818b40948",
"user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36",
response_home_page = requests.get(url=url, headers=headers)
date = response_home_page.url
#正则解析视频播放器地址
id = re.findall('item/(.*?)\\?', date)[0]
#拼接新地址
url_1 = f"https://h5.pipix.com/bds/webapi/item/detail/?item_id=id&source=share"
response_url = requests.get(url=url_1, headers=headers)
date = response_url.text
#正则解析视频地址
viedo_url = re.findall('http://v6(.*?)u', date)[0]
viedo_url = 'http://v6' + viedo_url
video_response = requests.get(url=viedo_url, headers=headers)
#写入文件
video_date = video_response.content
with open('video\\\\' + name + '.mp4', mode='wb') as f:
f.write(video_date)
5、爬取好看视频
impor requests
import re
import os
#创建文件
filename='video\\\\'
if not os.path.exists(filename):
os.mkdir(filename)
def Crawler(url,name):
#请求头信息需要更新
headers =
'cookie':'BIDUPSID=C4EC17093B39D9C14DA27F2C5EB5E971; PSTM=1665404090; BAIDUID=C4EC17093B39D9C1AE6281A256712DF2:FG=1; BAIDUID_BFESS=C4EC17093B39D9C1AE6281A256712DF2:FG=1; ZFY=S73y0dle7IUenE66ZTiRDG5oPbcGuVoCVD3d1DpoCl8:C; __bid_n=184432843e24d427a34207; PC_TAB_LOG=video_details_page; COMMON_LID=20d6fdf7fb2da7f9480d684df4d1ccbf; Hm_lvt_4aadd610dfd2f5972f1efee2653a2bc5=1675650075,1675659083; BDUSS=1JuMmRQb1o2YlloajV3Y1NsdS05V0lxQkFSb0hmSjFtcG94UUZGVFpPSnRGQWhrRUFBQUFBJCQAAAAAAQAAAAEAAABjUK55aGVoc3ZzODUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAG2H4GNth-Bja; BDUSS_BFESS=1JuMmRQb1o2YlloajV3Y1NsdS05V0lxQkFSb0hmSjFtcG94UUZGVFpPSnRGQWhrRUFBQUFBJCQAAAAAAQAAAAEAAABjUK55aGVoc3ZzODUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAG2H4GNth-Bja; hkpcvideolandquery=DJ%u52B2%u7206%u821E%u66F2%uFF0C%u6124%u6012%u7684%u60C5%u4EBA%28DJ%u7248%29; Hm_lpvt_4aadd610dfd2f5972f1efee2653a2bc5=1675661411; ariaDefaultTheme=undefined; ab_sr=1.0.1_NWEyYWJjZTA4ZjMxN2I1NDJhZDk0ZGVjYmEwMTkyOGJjZGFiYzA5MDM3NDZhNDIxMzVjMmJkMTE0OTk0YjczZjA3NDUwODNiOTA4MWQ4YWYxNjBmZTdlYzc5MmVjM2FhYzRlNzYzYjkxY2NiMjI5NTQwOWNkNWU5MGVjMmQ4OGE0YzNjZDg3OTk2YjZjZjIwZDZiNzA5MWZlN2JkZGI3ZQ==; reptileData=%7B%22data%22%3A%22e8e9b6023742835f0e561432225f0e7a9a4914d19bf05d633fc2c9dbb0d2621c76ee8600fcf0b64559b108f8658605f4268b0093a8129458e37ff2bc85d28b7d70f4f49d66367684ead60f00ae201824e25c511a619895de14546b0522203ef3%22%2C%22key_id%22%3A%2230%22%2C%22sign%22%3A%22f719e71b%22%7D; RT="z=1&dm=baidu.com&si=57e4d3b7-0362-48c5-80ae-0c5b89bcbe22&ss=ldsc5hkc&sl=77&tt=1v38&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=1ebc8&ul=1ec6h"',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.78',
response = requests.get(url=url, headers=headers)
m = re.findall('playurl":"(.*?).mp4', response.text)[0]
m = m.replace("\\\\", "")
m = m + ".mp4"
print(m)
video = requests.get(url=m, headers=headers)
date1 = video.content
with open('video\\\\' + name + '.mp4', mode='wb') as f:
f.write(date1)
6、主函数
import tkinter # 界面模块
import re # 正则模块 from tkinter import * import crawler_bilibili # B站爬取文件 import crawler_hao # 好看视频爬取文件 import kuaishou import pipixia import tiktok import threading import time ''' 实现原理: 1 利用tkinter模块建立一个界面 2运用按钮执行函数button,将获取的参数提交对应的执行文件 3单选按钮应用 ''' # win = tkinter.Tk() win.title("爬虫") win.geometry("540x360") l1 = Label(win, text="请 输 入 网 址", font="宋体", height="2") l1.grid(row=0, column=0, columnspan=100, padx=60) text=StringVar() text2 = StringVar() text5 = StringVar() text6 = StringVar() e1 = Entry(win, width=40,textvariable=text,font="song -20", background="#E6E6E6") e1.grid(row=1, column=0, columnspan=100, padx=60) l2 = Label(win, text="请 输 入 文 件 名", font="宋体", height="2") l2.grid(row=2, column=0, columnspan=100, ) e2 = Entry(win, width=40, textvariable=text2, font="song -20", background="#E6E6E6") e2.grid(row=3, column=0, columnspan=100, ) l3 = Label(win, textvariable=text5, font='宋体') l3.grid(row=7, column=0, columnspan=100, ) e3 = Entry(win, width=40, textvariable=text6,state='disabled', font="song -20") e3.grid(row=9, column=0, columnspan=100) l4 = Label(win, text='联系我们', font='宋体') l4.grid(row=10, column=0, columnspan=100, ) chore = True def crawler(text3,name,Num): Num2=Num-1 list3=[crawler_bilibili.UrlCrawler,crawler_hao.Crawler,pipixia.pipixia,tiktok.TikTok,kuaishou.kuaishou] response=list3[Num2](text3,name) if response==1: text5.set('未知错误') elif response==0: text5.set('下载完成') global chore chore=False text6.set('*'*41) pass def progress_bar(): i = 1 while chore: text6.set("*" * i) i += 1 time.sleep(0.1) if i > 37: break if __name__ == '__main__': def Del(): text2.set('') text6.set('') text.set('') text5.set('') def button(): if Num1==0: text5.set('请选择站点') else: t1 = threading.Thread(target=progress_bar, args=()) try: text1 = text.get() except UnicodeDecodeError: text5.set('请删除链接中的特殊符号') return if len(text1)==0: text5.set('网址为空') return list1=text1.split(' ') j=0 for i in list1: src=list1[j] list2=re.findall('https(.*)',src) if len(list2)==0: j+=1 else: text3='https'+list2[0] name=text2.get() if len(name)==0: text5.set('文件名为空') return t2=threading.Thread(target=crawler,args=(text3,name,Num1) ) t1.start() t2.start() but1 = Button(win, text="提交", command=button, font="宋体") but2 = Button(win, text="清除", command=Del, font="宋体") but1.grid(row=6, column=0) but2.grid(row=6, column=6) Num1 = 0 # 布置选项按钮和对应的函数 def date(): global Num1 Num1 = v.get() v = IntVar() r1 = Radiobutton(win, text="B站 ", variable=v, value=1, command=date, font="song -20") r2 = Radiobutton(win, text="好看视频", variable=v, value=2, command=date, font="song -20") r3 = Radiobutton(win, text="皮皮虾", variable=v, value=3, command=date, font="song -20") r4 = Radiobutton(win, text="抖音", variable=v, value=4, command=date, font="song -20") r5 = Radiobutton(win, text="快手", variable=v, value=5, command=date, font="song -20") r1.grid(row=5, column=0) r2.grid(row=5, column=1) r3.grid(row=5, column=3) r4.grid(row=5, column=4) r5.grid(row=5, column=5) win.mainloop()
7、将.py文件封装成.exe文件
1、安装pyinstaller库
pip install pyinstaller
2、封装
pyinstaller -F-w 文件名
Python爬取各大外包网站需求
文章目录
前言
为了更好的掌握数据处理的能力,因而开启Python网络爬虫系列小项目文章。
- 小项目小需求驱动
- 总结各种方式
- 页面源代码返回数据(Xpath、Bs4、PyQuery、正则)
- 接口返回数据
一、需求
二、分析
一品威客
1、查看网页源代码
2、查找数据
3、获取详情页(赏金、任务要求、需求、状态)
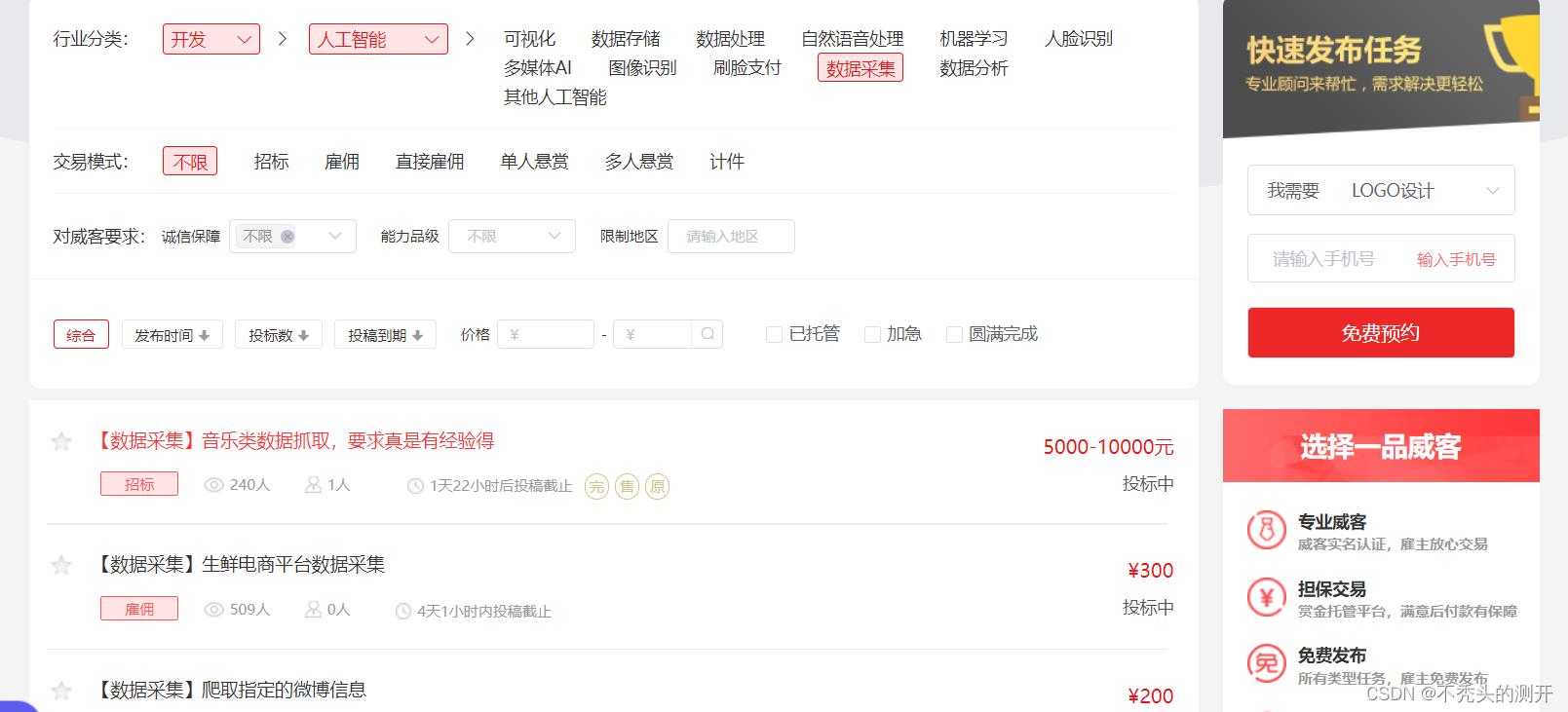
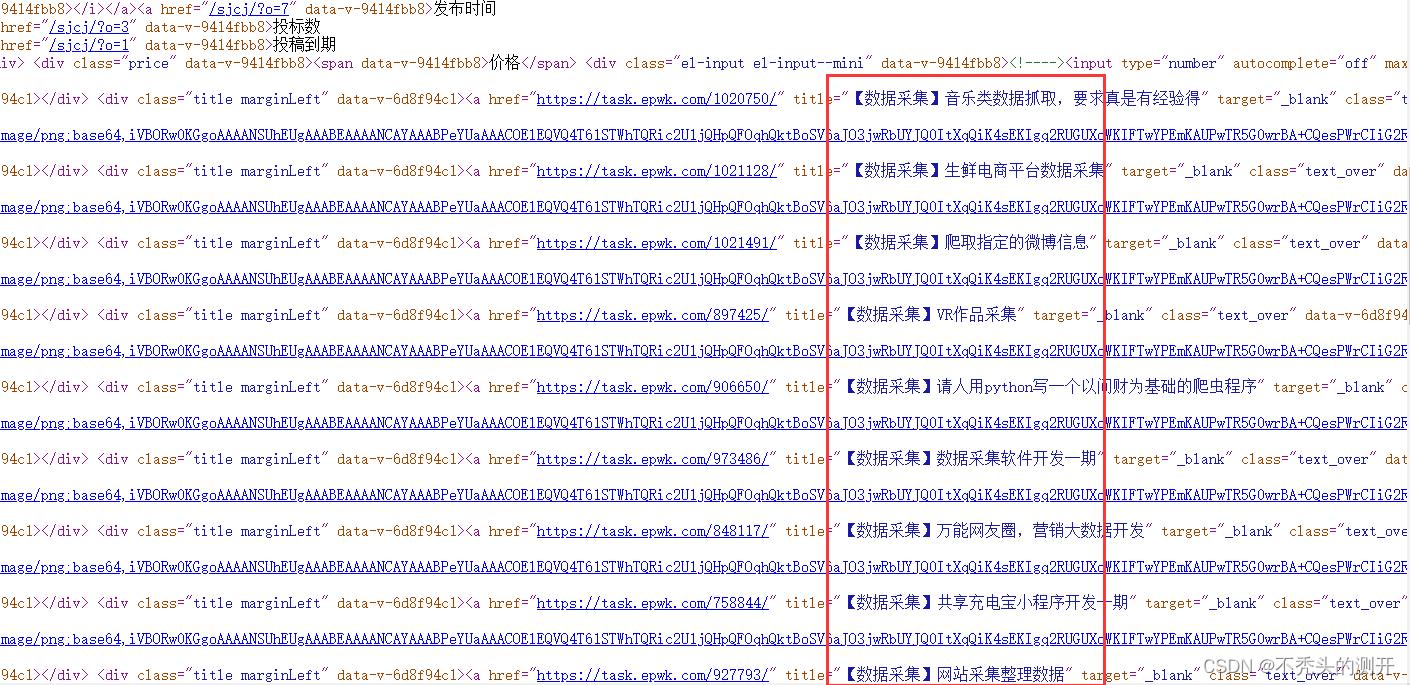
软件项目交易网
1、查看网页源码
2、全局搜索数据


获取YesPMP平台需求任务
1、查看网页源代码
2、全局搜索数据
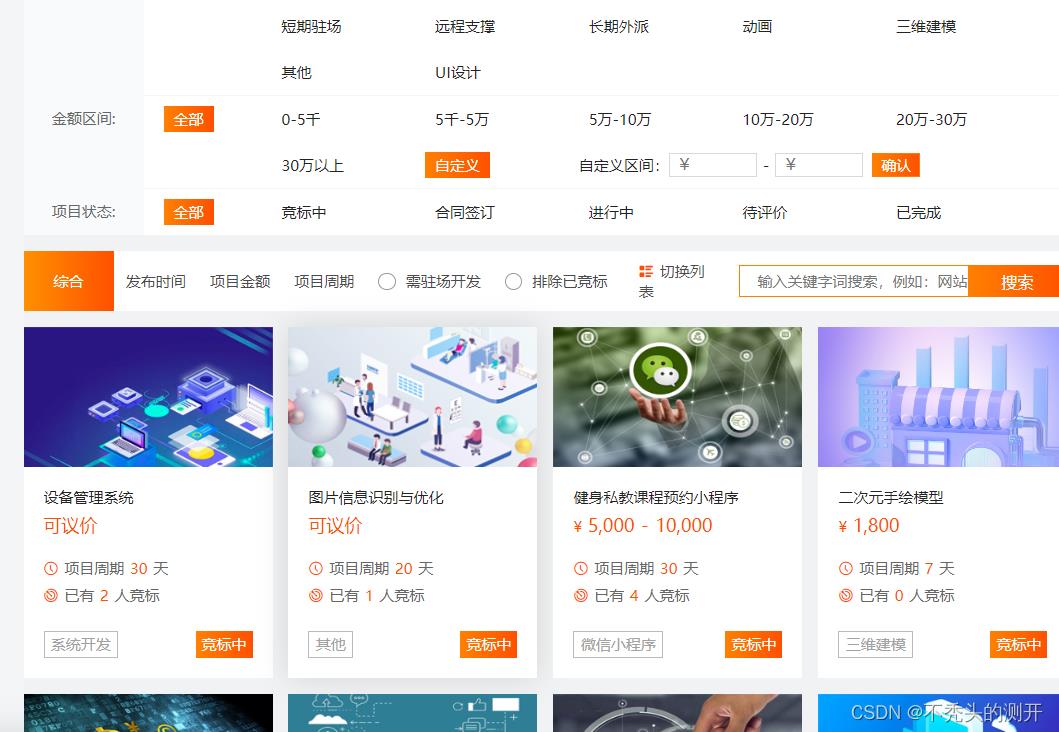

码市
1、F12抓包即可获取数据
2、构造请求即可获取数据

三、处理
一品威客
1、任务页任务
2、详情页(处理直接雇佣)
3、获取赏金、任务要求、时间
# -*- encoding:utf-8 -*-
__author__ = "Nick"
__created_date__ = "2022/11/12"
import requests
from bs4 import BeautifulSoup
import re
HEADERS = "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"Content-Type": "text/html; charset=utf-8"
def get_index_source(url):
res = requests.request("GET",url=url,headers=HEADERS)
res.encoding = "utf-8"
return res.text
# 实例化bs4
def method_bs4(html):
page = BeautifulSoup(html, "html.parser")
return page
# 直接雇佣任务
def method_zz(code):
deal = re.compile(r'<meta name="description" content="(?P<is_direct>.*?)" />',re.S)
result = deal.finditer(code)
for i in result:
check = i.group("is_direct")
if "直接雇佣任务" in check:
return True
def get_task_url(html):
page = method_bs4(html)
# 通过class属性获取页面的任务div
div = page.select(".title.marginLeft")
#
url_list =
for _div in div:
# 获取url
content_url = _div.find("a")["href"]
content = _div.text
task = content.split("【数据采集】")[1]
url_list[task] = content_url
return url_list
def get_task_content(url_dict):
with open("一品威客任务.txt",mode="a+", encoding="utf-8") as f:
for name, url in url_dict.items():
# print(name,url)
code_source = get_index_source(url)
page = method_bs4(code_source)
# 获取赏金
money = page.select(".nummoney.f_l span")
for _money in money:
task_money = _money.text.strip("\\n").strip(" ")
print(task_money)
# 直接雇佣任务无法查看详情,进行处理
result = method_zz(code_source)
if result:
f.write(f"直接雇佣-nametask_money\\n")
# 获取开始、结束时间
time = page.select("#TimeCountdown")
for _time in time:
start_time = _time["starttime"]
end_time = _time["endtime"]
print(start_time,end_time)
# 获取需求任务
content = page.select(".task-info-content p")
for _content in content:
content_data = _content.text
print(content_data)
f.write(f"name---content_data,task_money,start_time,end_time\\n")
if __name__ == '__main__':
url = "https://task.epwk.com/sjcj/"
html = get_index_source(url)
url_dict = get_task_url(html)
get_task_content(url_dict)
软件项目交易网
通过Xpath即可获取对应数据
# -*- encoding:utf-8 -*-
__author__ = "Nick"
__created_date__ = "2022/11/12"
import requests
from lxml import etree
HEADERS = "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"Content-Type": "text/html; charset=utf-8"
def get_index_source(url):
res = requests.request("GET",url=url,headers=HEADERS)
res.encoding = "utf-8"
return res.text
# 实例化etree
def method_xpath(html):
parse = etree.HTML(html)
return parse
def get_task_info(html):
with open("软件交易网站需求.txt",mode="w",encoding="utf-8") as f:
# 实例化xpath
parse = method_xpath(html)
# 通过xpath定位
result = parse.xpath('//*[@id="projectLists"]/div/ul/li')
for li in result:
# 获取任务状态
status = li.xpath('./div[@class="left_2"]/span/text()')[1]
# 剔除空格,其它符号
status = status.strip()
# 获取任务
task = li.xpath('./div[@class="left_8"]/h4/a/text()')
task_content = task[-1].strip()
# 获取预算
bond = li.xpath('./div[@class="left_8"]/span[1]/em/text()')[0]
# 获取人气
hot = li.xpath('./div[@class="left_8"]/span[2]/em/text()')[0]
# 发布日期
start_time = li.xpath('./div[@class="left_8"]/span[3]/em/text()')[0]
# 截止日期
end_time = li.xpath('./div[@class="left_8"]/span[4]/em/text()')[0]
f.write(f"status,task_content,bond,hot,start_time,end_time\\n")
if __name__ == '__main__':
url = "https://www.sxsoft.com/page/project"
html = get_index_source(url)
get_task_info(html)
获取YesPMP平台需求任务
通过PQuery即可获取数据
# -*- encoding:utf-8 -*-
__author__ = "Nick"
__created_date__ = "2022/11/12"
import requests
from pyquery import PyQuery as pq
HEADERS = "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"Content-Type": "text/html; charset=utf-8"
def get_index_source(url):
res = requests.request("GET",url=url,headers=HEADERS)
res.encoding = "utf-8"
return res.text
# 实例化pq
def method_pq(html):
parse = pq(html)
return parse
def get_task_info(html):
with open("yespmp网站需求.txt",mode="a",encoding="utf-8") as f:
parse = method_pq(html)
# 通过class属性进行定位
result =parse.find(".promain")
# print(result)
for _ in result.items():
# 任务名称
task_name = _.find(".name").text()
# 赏金
price = _.find(".price").text()
# 项目周期
date = _.find(".date").text()
# 竞标人数
bid_num = _.find(".num").text()
f.write(f"task_name,price,date,bid_num\\n")
if __name__ == '__main__':
for i in range(2,10):
url = f"https://www.yespmp.com/project/index_ii.html"
html = get_index_source(url)
get_task_info(html)
码市
基本request请求操作(请求头、参数)
# -*- encoding:utf-8 -*-
__author__ = "Nick"
__created_date__ = "2022/11/12"
import requests
import json
headers =
'cookie': 'mid=6c15e915-d258-41fc-93d9-939a767006da; JSESSIONID=1hfpjvpxsef73sbjoak5g5ehi; _gid=GA1.2.846977299.1668222244; _hjSessionUser_2257705=eyJpZCI6ImI3YzVkMTc5LWM3ZDktNTVmNS04NGZkLTY0YzUxNGY3Mzk5YyIsImNyZWF0ZWQiOjE2NjgyMjIyNDM0NzgsImV4aXN0aW5nIjp0cnVlfQ==; _ga_991F75Z0FG=GS1.1.1668245580.3.1.1668245580.0.0.0; _ga=GA1.2.157466615.1668222243; _gat=1',
'referer': 'https://codemart.com/projects?labelId=&page=1',
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
def get_data():
url = "https://codemart.com/api/project?labelId=&page=1"
payload =
response = requests.request("GET", url, headers=headers, data=payload)
print(json.loads(response.text))
if __name__ == '__main__':
get_data()
四、总结
- Xpath
- 适用于要获取的信息在某个标签下,且各标签层次明显,通过路径找到位置,for循环遍历即可
- Bs4
- 适用于要获取的信息比较分散,且通过选择器可以定位(class唯一、id唯一)
- PyQuery
- 适用于要获取的信息比较分散,且通过选择器可以定位(class唯一、id唯一)
- 正则
- 通过(.*?)就可以处理元素失效或者定位少量信息
- 不适用网页代码有很多其它符号,定位失效
- 接口返回数据
- 对于接口没有进行加密,通过requests构造请求即可获取数据
- 关注点在请求头中的参数
欢迎加入免费的知识星球内!
我正在「Print(“Hello Python”)」和朋友们讨论有趣的话题,你⼀起来吧?
https://t.zsxq.com/076uG3kOn
以上是关于Python爬虫爬取各大热门短视频平台视频的主要内容,如果未能解决你的问题,请参考以下文章