Python基础——上节补充及数据类型
Posted Mrterrific
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础——上节补充及数据类型相关的知识,希望对你有一定的参考价值。
1.变量的创建过程
当我们创建一个变量name=\'oldboy\'时,实际上是这样一个过程。
程序先开辟了一个内存空间,把变量的内容放进去,再让变量name指向\'oldboy’所在的内存地址。
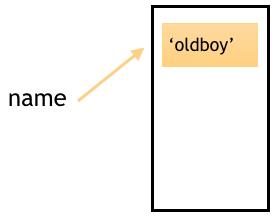
我们可以通过id(name)来查看变量所指向的内存地址,即\'oldboy\'所在的内存地址。
当变量修改时,name=\'alex\',变量就会再开辟一块内存空间,只想‘alex\'所在的内存地址,同时断开与\'oldboy\'之间的连接。
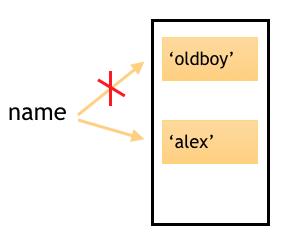
这时id(name)会得到与之前不同的内存地址。比如name指向\'oldboy\'时的内存地址为4317182301,那么name指向‘alex\'的内存地址就可能是4317182360。
当一个变量的值改变时,这个变量会指向新得内存地址,原来数据所占据的内存空间会被释放掉,这就是变量的垃圾回收机制。
如果name1=\'oldboy\' ,name2=\'oldboy\',那么name1和name2指向同一个内存地址。
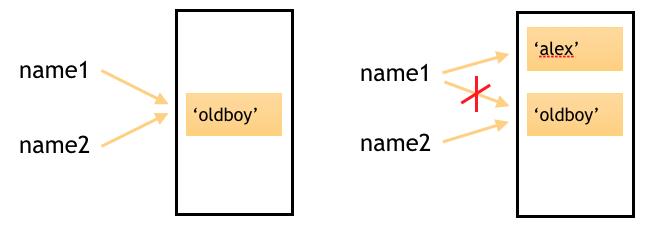
但是,当name1=\'alex\'时,程序会开辟一个新的内存地址,name1指向\'alex\'所在的内存地址,同时也断开了与\'oldboy\'的连接。
2.身份运算
Python中有很多数据类型,查看数据的数据类型可用type()方法。
name = \'alex\' print(type(name))
上面两行代码的运行结果就是<class \'str\'> ,class是类的意思,后面会学习,可以看到name变量是str类型。
判断一个数据的数据类型是不是str 或者 int ,可用is , is not 方法
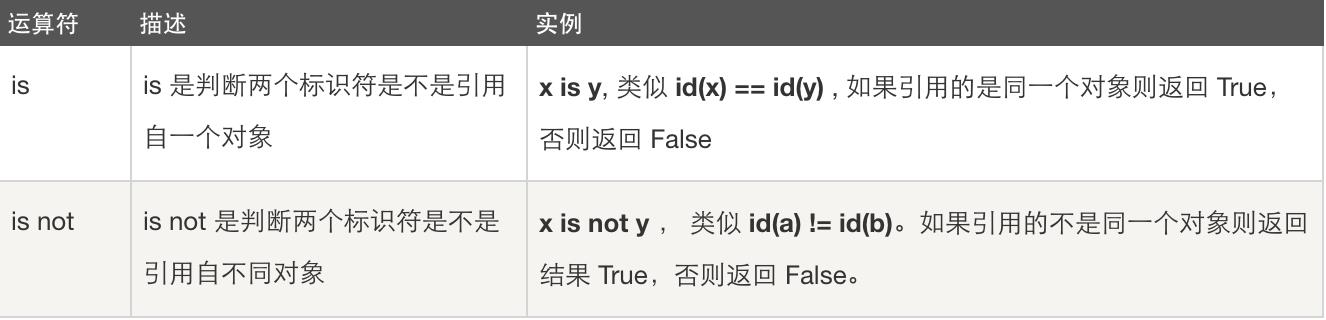
is就是判断一个数据是不是这样一个身份,比如
name = \'alex\' print(type(name) is str)
两行代码判断name是不是str类型,结果为True。
name = \'alex\' print( name is str)
这样运行的结果为False,因为name是一个实实在在的字符串,而并不是字符串类型。
is not 就是判断这个数据是否不是这样的什么,相对应。
3.空值None
None就是什么都没有的意思,通常用作初始化一个变量。即需要提前声明,但不知道应该设置一个怎样的值是,可以将其设置为None。
可用is运算符判断一个变量是否为None。
4.三元运算
#普通青年写法 name = \'alex\' sex = None if name == \'alex\': sex = \'male\' else: sex = \'female\' #装逼青年写法 sex = \'male\' if name == \'alex\' else "female"
三元运算就是将if..else语句缩成一行 ,判断成立,值等于左边;判断不成立,值为右边。
5.细讲数据类型
列表
(1) 定义:[ ]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素。
(2) 特点:可以存放多个值;可以存放各种数据类型;索引从0开始,每一个值按照索引排列;通过索引可以修改对应位置的元素的值。
(3) 列表的增删改查 :列表的内置方法会改变列表本身。
增
#append()方法,在列表最后追加一个元素 names = [\'alex\', \'eric\'] #创建一个列表,里面存放两个元素。 names.append(\'peiqi\') print(names) # names = [\'alex\', \'eric\', \'peiqi\'] #insert()方法,插入一个元素,可插入任何位置。 names.insert(2,\'mjj\') print(names) # names = [\'alex\', \'eric\', \'mjj\', \'peiqi\'] #extend(),可以将两个列表合并起来 age = [23,24,25] names.extend(age) print(names) #names=[\'alex\', \'eric\', \'mjj\', \'peiqi\', 23, 24, 25] #列表内部也可以嵌套列表 names.insert(4,[1,2,3]) print(names) # names=[\'alex\', \'eric\', \'mjj\', \'peiqi\', [1,2,3],23, 24, 25]
删
#del 直接删 ,可以删除元素,也可以直接删除整个列表 names = [\'alex\', \'eric\', \'mjj\', \'peiqi\', [1,2,3], 23, 24, 25] del names[1] #删除第二个元素 print(namas) # [\'alex\', \'mjj\', \'peiqi\', [1,2,3], 23, 24, 25] # del names 删除整个列表 #remove()方法,用来删除指定的内容 names.remove(\'peiqi\') print(names) # names = [\'alex\', \'mjj\', [1,2,3], 23, 24, 25] #pop() 默认删除最后一个元素并返回被删除的值,也可以删除指定索引的值 a = names.pop() print(names) # names = [\'alex\', \'mjj\', [1,2,3], 23, 24] print(a) # a为25 names.pop(1) # names = [\'alex\', [1,2,3], 23, 24] #clear() 清空列表 names.clear() print(names) # names = []
改
#通过索引来查找元素和修改元素,可以用通过负数来倒序查找元素,如索引值为-1查找的就是最后一个元素。 names = [\'alex\', \'eric\', \'mjj\', \'peiqi\'] a = names[0] b = names[1]
c = names[-1] print(a,b,c) # 运行结果:\'alex\' \'eric\',\'peiqi\'
names[1] = \'yun\' print(names) # names = [\'alex\', \'yuan\', \'mjj\', \'peiqi\']
查
# index() 方法,返回从左开始匹配到的第一个元素的索引值, names = [\'alex\', \'eric\', \'mjj\', \'peiqi\',\'alex\'] a = names.index(\'mjj\') b = names.index(\'alex\') print(a) #结果为 2 print(b) #结果为0 #count()方法,返回元素的个数 c = names.count(\'alex\') print(c) # 结果为2
(4)切片
切片就像切面包,可以去除多个元素的值
形式:names[start:end]
#切片特点:顾头不顾尾,names[start,end] 实际取出的是索引从start到end-1对应的元素. names=[\'alex\', \'eric\', \'mjj\', \'peiqi\', [1,2,3],23, 24, 25] a = names[1:4] print(a) # a 为 [\'eric\', \'mjj\', \'peiqi\'] #倒着切,列表也可以通过负的索引值切 b=names[-5:-1] print(b) # b 为 [ \'peiqi\', [1,2,3],23, 24] 不包含最后一个元素
b=names[-1:-5]只取出了四个元素,因为切片顾头不顾尾的特性。如果想取出最后五个元素可以通过这种方法
b = names[-5:] print(b) # b为[\'peiqi\', [1,2,3], 23, 24, 25]
names[start:]省略end,会从start开始一直取到最后。
names[:end]省略start,会从第一个元素取到end-1.
names[:]即可取得所有元素。
列表的切片不管起始和终止的索引为正为负,默认都是从左向右取的。那么想要切片从右往左取,就可以通过规定步长来实现。
names[start:end:step] 在没有规定step是默认为1。
names=[\'alex\', \'eric\', \'mjj\', \'peiqi\', [1,2,3],23, 24, 25] a = names[1:5:2] # 每步长为2取一个 print(a) # a为[\'eric\',\'peiqi\'] b = [::-1] # 通过规定步长为-1,就可以实现列表的倒序排列 print(b) # b = [25, 24, 23, [1, 2, 3], \'peiqi\', \'mjj\', \'eric\', \'alex\']
(5)排序
# sort() 方法使列表从小到大排列 a = [83,4,2,4,6,19,33,21] a.sort() print(a) # a为[2, 4, 4, 6, 19, 21, 33, 83] # sort(key,reverse) 里面两个参数 # key 参数用来指定根据哪个元素来比较 排序 , reverse 就是倒序 info = [[\'alex\',10], [\'eric\',20\'],[\'mjj\',2]] info.sort(key = lambda x : x[1]) # 根据列表中每个元素的第二个元素排序 # 结果 info = [[\'mjj\',2],[\'alex\',10], [\'eric\',20\']] #如果含有特殊字符或者多个字符,会按照第一个字符的ascii码值排序 names=[\'金角大王\', \'rain\', \'@\', \'黑姑娘\', \'狗蛋\', "4","#",\'银角大王\', \'eva\'] names.sort() print(names) # [\'#\', \'4\', \'@\', \'eva\', \'rain\', \'狗蛋\', \'金角大王\', \'银角大王\', \'黑姑娘\'] #reverse()方法,可以实现列表的反转 names.reverse() print(names) # names =[\'黑姑娘\', \'银角大王\', \'金角大王\', \'狗蛋\', \'rain\', \'eva\', \'@\', \'4\', \'#\']
(6)循环列表
循环列表一般用for循环。
numbers = [1, 2, 3, 4, 5] for i in numbers: print("number=",i) #运行结果: number= 1 number= 2 number= 3 number= 4 number= 5
元组
元组又被称为只读列表,不能修改。
(1)定义:与列表相似,不过[ ]改为()。
(2)特点:可存放多个值;元素不可变;按照从左到右的顺序定义元组元素。
(3)元组常用操作:
#创建 a = (11, 12 ,13, 14) #或 b = tuple((11, 12 ,13, 14)) ages = (11, 22, 33, 44, 55) c=ages[0] d=ages[-1] print(c,d) # c为11 ,d为55 #切片:同列表 #循环:同列表 #len方法查看长度(元素个数) >>> len(ages) 5
#包含 print(11 in ages) # True print(66 in ages) # False print(11 not in ages) # False
注意:元组本身不可变,如果元组中还包含其他可变元素,这些可变元素可以改变。
不可变元素如数字,字符串,可表元素如字典,列表。
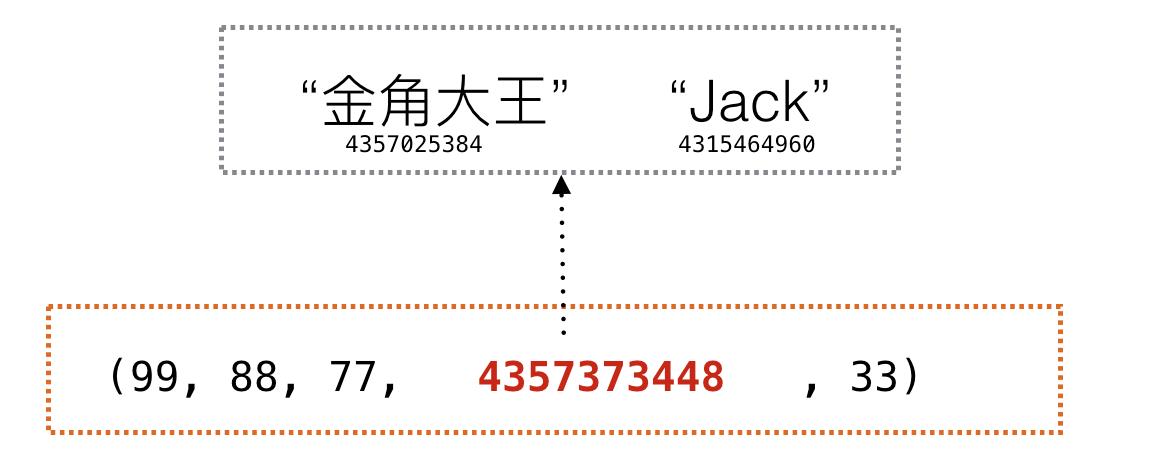
data=(99, 88, 77, [\'Alex\', \'Jack\'], 33) data[3][1]=\'eric\' print(data) # (99, 88, 77, [\'Alex\', \'eric\'], 33)
因为元组只是存每个元素的内存地址,上面[‘金角大王’, ‘Jack’]这个列表本身的内存地址存在元组里确实不可变,但是这个列表包含的元素的内存地址是存在另外一块空间里的,是可变的。
字符串
(1)定义:字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,\' \' , \'\' \'\' , \'\'\' \'\'\',中间包含的内容称之为字符串。
(2)特性: 按照从左到右的顺序定义字符集合,下标从0开始顺序访问; 可以进行切片操作;
不可变,字符串是不可变的,不能像列表一样修改其中某个元素,所有对字符串的修改操作其实都是相当于生成了一份新数据。
(3)字符串的单引号和双引号都无法取消特殊字符的含义,如果想让引号内所有字符均取消特殊意义,在引号前面加r,如name=r\'l\\thf\'。
注意:对字符串的操作方法并不改变原字符串。
(4)字符串的常用操作
names=\'alex Li\' names.capitalize() # 首字母大写 Alex Li names.casefold() # 把字符串全变小写 alex li names.center(20,\'-\') # ------alex Li------- names.count(\'字符\',start,end) # 找出在规定范围内字符出现的个数 names.endcode() # 编码 names.endwith() # 判断字符串以什么结尾 names.startwith() # 判断字符串以什么开始 name.find() # 找到这个字符返回下标,多个时返回第一个;不存在的字符返回-1 name.index() # 找到这个字符返回下标,多个时返回第一个;不存在的字符报错 name.format() # 字符串格式化 s1 = "Welcome {name} to Apeland,you are No.{user_num} user." print(s1.format(name="Alex", user_num=999)) #结果Welcome Alex to Apeland,you are No.999 user
bb = "luffy"
print(f\'my name is {bb}\') # my name is bb f\'为fromat 简写
names.isdigit() # 判断字符串是否都是数字,返回一个布尔值 names.isspace() #是否全是空白字符 names.islower() #S中的字母是否全是小写 names.isupper() #S中的字母是否便是大写 names.istitle() #S是否是首字母大写的 n = [\'alex\',\'jack\',\'rain\'] print(\'|\'.join(n)) # 结果为\'alex|jack|rain\' #\' strs\'.join(n) 用字符串连接n 使n成为一个字符串 ,n可以为字符串。 names.lower() # 将字符串全部小写 names.upper() # 将字符串全部大写 names.swapcase() # 返回大小写转换后的字符串 names.ljust(width,char) # 返回一个原字符串向左对齐,指定长度的字符串,长度不够# 用指定的字符来补,超过则自动加长 names.rjust(width,char) # 向右对齐,其余同上 names.strip() # 去掉左右的空格和换行符 names.lstrip() # 去掉左边的空格和换行符 names.rstrip() # 去掉右边的空格和换行符 names.strip(str) # 去掉指定的字符 names.replace(oldstr,newstr) # 字符串替换 names.split() # 默认以空格分割成一个列表,也可指定字符分割 names.zfill(width) # 指定字符串长度,向右对其,长度不够补0
字典
(1)定义:通过键值对的形式{ key1: value1, key2: value2}
ex : user_info = {
\'name\': \'alex\',
\'age\': 24;
\'hobby\': \'have fun with girls\'
}
(2)特性:
-
key-value结构。
-
key必须为不可变数据类型、必须唯一。
-
可存放任意多个value、可修改、可以不唯一。
-
排列无序。
-
查询速度快。
(3)字典的创建及常用操作
创建
#直接通过大括号创建 person = {"name": \'alex\', \'age\': 20} #dict方法 person = dict(name=\'seven\', age=20) #或 person = dict({"name": "egon", \'age\': 20}) #批量创建key时, 用{}.fromkeys([key1,key2,key3],n) 其中key为键名,n为默认值 a={}.fromkeys([1,2,3,4],100) print(a) # 运行结果: {1:100, 2:100, 3:100, 4:100}
增
user_info = {\'name\': \'alex\', \'age\': 23, \'sex\': \'male}
#添加一组键值对
user_info[\'hobby\'] = \'girls\'
print(user_info)
# user_info = {\'name\': \'alex\', \'age\': 23, \'sex\': \'male,\'hobby\': \'girls\'}
#setdefault()方法
#user_info.setdefult("key",value)
# 如果字典user_info中没有key,则在字典中添加该键值#对,并返回value的值;
#如果字典中用这个key,则返回字典中key对应的值,原来字典中的值不作修改。
删
person = {\'alex\': \'boss\', \'wupeiqi\': \'manager\', \'egon\': \'staff\' }
#pop()方法
person.pop(\'egon\') # 删除指定的键值对
print(person) # person = {\'alex\': \'boss\', \'wupeiqi\': \'manager\'}
#popitem()
person = {\'alex\': \'boss\', \'wupeiqi\': \'manager\', \'egon\': \'staff\' }
person.popitem() # popitem()方法随机删除一组键值对,所以person可能有多个值
print(person)
#del方法
del person[\'wupeiqi\'] # del什么都可以删,包括字典本身。
print(person) # person = {\'alex\': \'boss\', \'egon\': \'staff\' }
#clear
person.clear() # 清空字典
print(person) # person={}
改
#通过key来修改 person = {\'alex\': \'boss\', \'wupeiqi\': \'manager\', \'egon\': \'staff\' } person[\'egon\'] = \'弟弟\' print(person) # person = {\'alex\': \'boss\', \'wupeiqi\': \'manager\', \'egon\': \'弟弟\' } #update方法 dic1 = {\'name\':\'alex\', \'age\':23, \'sex\':\'male\'} dic2 = {\'sex\':\'female\',\'hobby\':\'girls\'} dic1.update(dic2) print(dic1) # dic1={\'name\': \'alex\', \'age\': 23, \'sex\': \'female\', \'hobby\': \'girls\'} #update方法就是dic1和dic2合并成为一个字典,当dic1和dic2有相同的key时, #key的值会进行覆盖,update()里面的覆盖外面的,即dic2覆盖dic1.
查
#通过key查找,dic[key],存在则返回相对应的值,不存在则报错。 person = {\'alex\': \'boss\', \'wupeiqi\': \'manager\', \'egon\': \'staff\' } a = person[\'alex\'] print(a) # a = \'boss\' #get方法查找,dic.get(key, default) 返回key对应的值,若不存在,则返回默认值 b = person.get(\'wupeiqi\') # default可以不写,默认为None print(b) # b = \'manager\' c = person.get(\'mjj\', \'cleaner\') # 可以设置默认值 print(c) # c = \'cleaner\' #dic.keys() 返回一个包含所有key的列表 #dic.values() 返回一个包含所有values的列表 ,但不能像列表一样操作,因为数据类型不同 keys = person.keys() # dict_keys([\'alex\', \'wupeiqi\', \'egon\']) values = person.values() # dict_values([\'boss\', \'manager\', \'staff\']) #dic.items() 返回一个包含所有(键,值)元组的列表 item = person.items() # dict_items([(\'alex\', \'boss\'), (\'wupeiqi\', \'manager\'), (\'egon\', \'staff\')])
(4)字典的循环
#1、for k in dic.keys() # k就是key的值 #2、for k,v in dic.items() #用两个参数k,v接收,k为key的值,v为value的值 #3、for k in dic # 推荐用这种,效率速度最快 k仍为key,当想取值时,用 dic[k] 即可
(5) 求字典长度
len(dic):求出字典中键值对的个数。
集合
(1)定义:集合与列表相似,可以存放不同的数据类型,但与列表也有不同之处。
(2)特性:
1.天生去重,集合中不能有重复的元素。
2.无序,不像元素在列表中通过索引来排列,集合中的元素时没有顺序的,即{3,4,5}与{5,3,4}是同一个集合。
3.集合中的元素不可变,即不能存放列表,字典,数字、字符串、元组这些不可变的类型可以存入集合。
综合以上特性,集合可以用来做两件事情,去重和关系运算。
(3)集合的语法及常用操作
创建
#集合和字典相似,都是通过{}创建,不过集合没有键值对。 a={1,2,3,4,\'alex\',\'wupeiqi\',\'egon\',1,2,3,4,5} print(a) # a={1,2,3,4,5,\'alex\',\'wupeiqi\',\'egon} ,由此可见集合的去重特性 #通过集合去重的特性,我们可以帮列表去重。 b = [1, 2, 3, 4, 2, \'alex\', 3, \'rain\', \'alex\'] a = set(b) # a={1, 2, 3, 4, \'alex\', \'rain\'} b = list(a) # b =[1, 2, 3, 4, \'alex\', \'rain\'] #上述过程就是将b转换成集合,去重后,在转换为列表,整个过程通过一句代码就可以搞定。 b = list(set(b)) #效果与上面的三句相同
增删查:集合元素不能修改
a = { 1,2,3,4,\'alex\',\'wupeiqi\'}
#增加元素,用add()方法
a.add(\'mjj\')
print(a) # a ={1, 2, 3, 4, \'alex\', \'mjj\',\'rain\'}
#删除元素,有三种方法
#a.pop() 随机删除一个元素并返回
#a.discard() #删除指定元素,如果该元素不存在,则什么都不做。
#a.remove() # 删除指定元素,如果该元素不存在,则报错。
#查
print(a) # 查看整个集合
print(4 in a) # 通过in 、not in 方法判断元素是否在集合中
(4)关系运算:两个集合之间一般有三种关系,相交、包含、不相交。
s_1024 = {"peiqi","oldboy","rain","mjj"}
s_pornhub = {"Alex","Egon","rain"}
print(s_1024&s_pornhub)#求交集
# {\'rain}以上是关于Python基础——上节补充及数据类型的主要内容,如果未能解决你的问题,请参考以下文章