Python 之路 Day02 -基础数据类型及编码详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 之路 Day02 -基础数据类型及编码详解相关的知识,希望对你有一定的参考价值。
基础篇
本章大纲:
字符编码和解释器编码详解
变量命名规则
基础数据类型(一) int
基础数据类型(二) string
基础数据类型(三) bool
基础数据类型(四) list
基础数据类型(五) tuple
基础数据类型(六) dict
基础数据类型(七) set
补充可迭代对象的循环连接及enumerate输出
字符编码和解释器编码详解
一,编码的重要性:
1.1 文件编码和字符编辑编码及读取编码
#!/usr/bin/env python
#-*- coding:utf-8 -*-
with open(‘acsii_01‘,‘a+‘,encoding=‘utf-8‘) as f:
f.write(‘李杰‘+‘\\n‘)
with open(‘acsii_01‘,‘r‘,encoding=‘utf-8‘) as f:
data = f.read()
print(data)
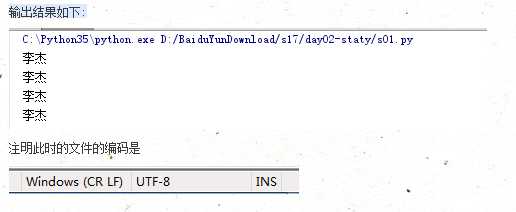
总结:
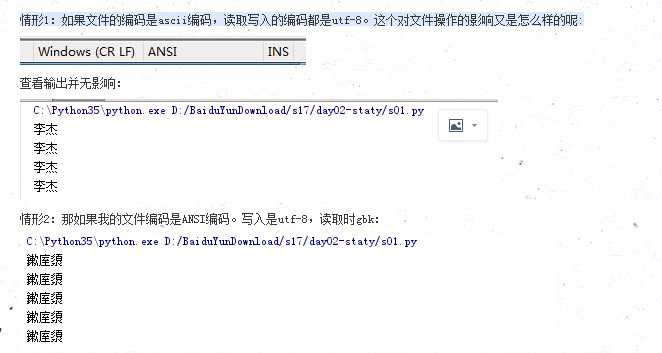
注明: 对待file操作的编码问题。注明文件的编码可以是任何编码格式。但是写入的编码必须和读取的编码一致。其实这就涉及到文件存储编码问题了。下面我们可以二进制的格式读取file看看不同的编码格式的在文件中存储的方式:

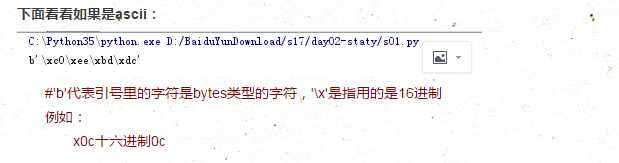
另外如果读取文件的时候使用到时rb模式。就不需要指定encoding。encoding的作业就是当你的file操作的编码不是utf-8(python3字符操作的默认编码是utf-8),就需要你指定读取文件的为指定的编码了。
#!/usr/bin/env python
#-*- coding:utf-8 -*-
with open(‘acsii_01‘,‘rb‘) as f:
data=f.read()
print(‘acsii‘,data)
with open(‘acsii_02‘,‘rb‘) as f:
data=f.read()
print(‘utf-8‘,data)
with open(‘acsii_03‘,‘rb‘) as f:
data=f.read()
print(‘gbk‘,data)
with open(‘acsii_04‘, ‘rb‘) as f:
data = f.read()
print(‘unicode‘, data)

总结:
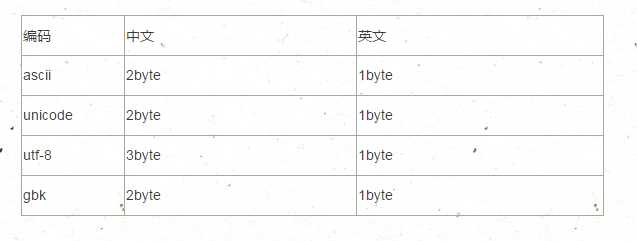
字符编码注意读写的编码要一直。另外文件操作的file编码和读写的编码其实关系。只要是你写入的编码和读取的编码一致就可以正常读取文件。建议文件操作的时候指定文件读写的编码。当然如果是读取的mode是rb的话,就没有必要去指定编码格式了。
其次字符编码和python解释器编码是不同的。python解释器的编码是作用于编译python过程去读取生产字节码。字符编码是对字符操作的。
变量命名规则
一,变量的命名规则:
1,不能以字母开头
2,不能以内置变量相同。
3,不能以特殊含义的字符开头
基础数据类型(一) int
一,整形
a=1
基础数据类型(二) string
二,string的常用方法如下:
#字符串首字母大小。其他的字母小写
s=‘alxE\\ttianTao3‘
data=s.capitalize()
print(data)
#转换成小写。针对unicode所有的字符
data=s.casefold()
print(data)
#转换成小写。只针对ASCII 内的A-Z转换
#可以包含特殊字符%,@
data=s.lower()
print(data)
str1=‘Alex$%@‘
data=str1.lower()
print(data)
#居中填充
#20为长度。*为填充的字符,可以none
data=s.center(20,‘*‘)
print(data)
#统计字符。可以指定其实index和结束index
data=s.count(‘a‘,0,-1)
print(data)
#指定编码errors=no 忽略报错
data=s.encode(encoding=‘utf-8‘,errors=‘no‘)
print(data)
print(‘@@@@@@@@@@@@@@@@@‘)
#以指定的字符结尾
data=s.endswith(‘ao‘)
print(data)
#以指定的字符开始
data=s.startswith(‘al‘)
print(data)
#去掉制表符\\t.
#0是指从起始位置到制表符长度。长度不够空白填充。
#另外注意长度最好指定。默认有一个长度
print(s)
data=s.expandtabs(0)
print(data,len(data),len(s),len(‘alEx ‘))
#查找字符串
#返回查到的第一个字符串的起始index,可以指定start,end
data=s.find(‘a‘)
print(data)
#字符串格式化输出
data=‘输出%s‘ %(s)
print(data)
data=‘输出{a}‘.format(a=s)
print(data)
data=‘输出{a}‘.format_map({‘a‘:s})
print(data)
#查找字符串的index.
#显示字符串起始index。可以指定start,end
data=s.index(‘al‘)
print(data)
#isalnum检测字符串是否有字母和数字组成
str1=‘alextian2‘
data=str1.isalnum()
print(data)
#isalpha是否为英文字母
str1=‘alextian‘
data=str1.isalpha()
print(data)
#是否是数字isdecimal
str1=‘22222‘
data=str1.isdecimal() #只能判断纯数字
print(data)
str1=‘2222①‘
data=str1.isdigit() #可以判断特殊的数字
print(data)
str1=‘2222①二‘
data=str1.isnumeric() #可以判断特殊的数字
print(data)
#isidentifier测试是不是有效的变量
str1=‘2ceshi‘
data=str1.isidentifier()
print(data)
str1=‘ceshi‘
data=str1.isidentifier()
print(data)
#是否是小写字符
str1=‘zaddd‘
data=str1.islower()
print(data)
str1=‘aaddd%‘
data=str1.islower()
print(data)
#isprintable是否有影含的换行 制表符 \\n \\r\\n \\t
str1=‘alex tian‘
data=str1.isprintable()
print(data)
str1=‘alex\\n tian‘
data=str1.isprintable()
print(data)
str1=‘alex\\t tian‘
data=str1.isprintable()
print(data)
str1=‘alex tian‘
data=str1.isprintable()
print(data)
#isspace是否全部是空格
str1=‘ ‘
data=str1.isspace()
print(data)
#istitle是否是标题
#每个单词首字母大写
str1=‘Alex Shangshan‘
data=str1.istitle()
print(data)
#循环连接所有可迭代
str1=‘alex‘
data=‘_‘.join(str1)
print(data)
#左填充右填充
str1=‘alex‘
data=str1.rjust(20,‘*‘)
print(data)
#移除空格或者换行
str1=‘ alex ‘
data=str1.strip()
#对应和翻译
m = str.maketrans(‘al‘,‘@@‘)
str1=‘alex tian‘
data=str1.translate(m)
print(data)
#以字符界限分割
str1=‘alex‘
data=str1.partition(‘l‘)
print(data)
data=str1.split(‘l‘)
print(data)
#去掉内部的换行符
str1=‘alex\\ntian‘
data=str1.splitlines()
print(data)
#指定查找替换和替换个数
str1=‘alex‘
data=str1.replace(‘a‘,‘A1‘,1)
print(data)
#字符串转小写.大写转小写。小写转大写
str1=‘AlEx‘
data=str1.swapcase()
print(data)
#小写转大写
str1=‘alex‘
data=str1.upper()
print(data)
#标题
str1=‘Alex tiantao‘
data=str1.title()
print(data)
#从左边用0填充字符串
str1=‘alex‘
data=str1.zfill(20)
print(data)
字符串切片上章节
基础数据类型(三) bool
三,bool类型的值和判断规则
print(bool(1)) print(bool(0)) print(bool(-1))
总结:
‘‘‘
总结 bool类型
0为假 非0为真
空位假 非空为真 (字符和对象都可以判断)
‘‘‘
基础数据类型(四) list
四,list方法总结
#####################################list############################### #注意列表是可变元素故此有一些方法或者属性可以直接在列表上操作。或者有返回值 #添加列表元素 list1=[] v=list1.append(‘alex‘) print(v) print(list1) #清空列表元素 v=list1.clear() print(v) print(list1) #浅copy元素 #浅拷贝,只拷贝了父对象,不会拷贝父对象中的子对象;deepcopy 是深拷贝,可以认为是完全的复制过去了; list1=[1,2,3,[1,2,3,4]] list2=list1.copy() list1[-1][0]=2 print(list1,list2) list1[0]=2 print(list1,list2) #count计数 list1=[1,2,3,4,5,5] data=list1.count(5) print(data) #extend扩展 list1=[1,2,3,4,5,5] data=list1.extend([1,2,3,4]) print(data) print(list1) #index索引 list1=[1,2,3,4,5,5] data=list1.index(5) print(data) #insert指定index位置插入 list1=[1,2,3,4,5,5] data=list1.insert(2,[4,3,4]) print(list1) #pop弹出一个元素.可以指定index list1=[1,2,3,4,5,5] data=list1.pop(2) print(list1) #remove移除指定元素 list1=[1,2,3,4,‘5‘,‘5‘] data=list1.remove(‘5‘) print(list1) #reverse翻转list list1=[1,2,3,4,‘5‘,‘5‘] data=list1.reverse() print(list1) #sort排序 list1=[1,2,3,4,5,5] data=list1.sort() print(list1) list1=[1,2,3,4,5,5] data=list1.sort(reverse=True) print(list1)
基础数据类型(五) tuple
五,元祖类实例化方法如下:
#index通过value找index tuple1=(1,2,3,4) data=tuple1.index(3) print(data) #count统计value tuple1=(1,2,3,4) data=tuple1.count(2) print(data)
基础数据类型(六) dict
六,字典实例化对象方法如下:
#clear清空
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
dict1.clear()
print(dict1)
#copy浅copy
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
dict2=dict1.copy()
print(dict2)
#fromkeys 字典的静态方法 循环list创建字典
#注意key必须不可变元素。另外value修改,其他的元素也会被修改
dict1=dict.fromkeys([‘v1‘,‘v2‘],123)
print(dict1)
#get方法获取指定key的value
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
data=dict1.get(‘v1‘)
print(data)
#items返回一个可循环的元祖的list
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
data=dict1.items()
print(data)
for key,value in dict1.items():
print(key,value)
#keys或者字典的所有的key
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
data=dict1.keys()
print(data)
#pop弹出一个指定键值对,返回对应的value
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
data=dict1.pop(‘v1‘)
print(data)
print(dict1)
#popitmes随机弹出一个指定键值对,返回对应的value
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
data=dict1.popitem()
print(data,dict1)
#setdefaul 设置添加一个元素。存在不添加
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
data=dict1.setdefault(‘v3‘,‘li‘)
print(data,dict1)
#update更新字典
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
data=dict1.update({‘v1‘:‘zhangsan‘,‘v3‘:‘lisi‘})
print(data,dict1)
#values获取字典的values
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
data=dict1.values()
print(data,dict1)
‘‘‘
注意字典的key必须是不可变对象
可变hash的
‘‘‘
基础数据类型(七) set
七,set集合对象实例化方法如下:
#add 增加一个元素
set1={1,2,4,5}
data=set1.add(‘6‘)
print(set1)
#clear清除元素
set1={1,2,4,5}
data=set1.clear()
print(set1)
#copy浅copy
set1={1,2,4,5}
set2=set1.copy()
print(set2)
#集合比较
#difference set1与set2的差集。set1有的set2没有
set1={1,2,4,5}
set2={1,2,3,5}
data=set1.difference(set2)
print(data)
#difference_update把差集赋值给set1
set1={1,2,4,5}
set2={1,2,3,5}
data=set1.difference_update(set2)
print(data,set1)
#discard移除元素
set1={1,2,4,5}
data=set1.discard(5)
print(set1)
#交集intersection
set1={1,2,4,5}
set2={1,2,3,5}
data=set1.intersection(set2)
print(data)
#intersection_update略
#union并集
set1={1,2,4,5}
set2={1,2,3,5}
data=set1.union(set2)
print(data)
#isdisjoint如果没有交集就是True
set1={1,2,3,5}
set2={6,7}
data=set1.isdisjoint(set2)
print(data)
#issubset判断是不是子集
set1={1,2}
set2={1,2,3,5}
data=set1.issubset(set2)
print(data)
#issuperset判断是不是父集
set1={1,2}
set2={1,2,3,5}
data=set2.issuperset(set1)
print(data)
#pop弹出一个集合元素
set1={1,2}
data=set1.pop()
print(data)
#remove移除一个元素
set1={1,2}
data=set1.remove(2)
print(set1)
#symmetric_difference对称差集。差集的集合
set1={1,2,6,7}
set2={1,2,3,5}
data=set1.symmetric_difference(set2)
print(data)
#update更新集合
set1={1,2,6,7}
data=set1.update({4,5,6})
print(data,set1)
补充可迭代对象的循环连接及enumerate输出及总结
一,可迭代对象的连接成字符串 ‘‘.join()
#可迭代对象的链接及输出
str1=‘alex‘
str1=‘+‘.join(a)
print(str1)
list1=[‘1‘,‘2‘]
list1=‘+‘.join(list1)
print(list1)
tuple1=(‘1‘,‘2‘)
tuple1=‘+‘.join(list1)
print(tuple1)
dict1={‘v1‘:‘alex‘,‘v2‘:‘tian‘}
dict1=‘+‘.join(list1)
print(dict1)
set1={1,2,3}
set1=‘+‘.join(set1)
print(set1)
总结:
1,可迭代对象都可以用join方法去迭代连接字符串
二,循环输出可迭代对象
#enumerate方法返回一个[(index,enumer)]
data=enumerate(list1)
print(data)
for line in data:
print(line)
data=enumerate(list1)
for index,enum in data:
print(index,enum)
总结:
1,注意迭代器赋值给一个对象后。如果迭代器__next__已经循环结束。后面的这个对象就不会再有元素能迭代了,故此迭代结束
2,enumerate方法返回一个元素是tuple的列表 [(index,enumer)]
以上是关于Python 之路 Day02 -基础数据类型及编码详解的主要内容,如果未能解决你的问题,请参考以下文章