MegEngine 使用小技巧:量化
Posted MegEngine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MegEngine 使用小技巧:量化相关的知识,希望对你有一定的参考价值。
常见神经网络模型所用的 Tensor 数据类型 一般是 float32 类型, 而工业界出于对特定场景的需求(极少的计算资源,极致的推理速度),需要把模型的权重和或激活值转换为位数更少的数值类型(比 int8, float16) —— 整个过程被称为量化(Quantization)。

通常以浮点模型为起点,经过中间的量化处理后最终变成量化模型,在这个过程中一般会导致模型掉点。
目前业界缓解模型掉点的问题的技术主要有两种,在 MegEngine 中都进行了支持:
-
训练后量化(Post-Training Quantization, PTQ);
-
量化感知训练(Quantization-Aware Training, QAT)。
更多量化基本流程:量化基本流程介绍
整体流程
以量化感知训练为例,一般以一个训练完毕的浮点模型为起点,称为 Float 模型。 包含假量化算子的用浮点操作来模拟量化过程的新模型,我们称之为 Quantized-Float 模型,或者 QFloat 模型。 可以直接在终端设备上运行的模型,称之为 Quantized 模型,简称 Q 模型。
而三者的精度一般是 Float > QFloat > Q ,故而一般量化算法也就分为两步:
-
拉近 QFloat 和 Q,这样训练阶段的精度可以作为最终 Q 精度的代理指标,这一阶段偏工程;
-
拔高 QFloat 逼近 Float,这样就可以将量化模型性能尽可能恢复到 Float 的精度,这一阶段偏算法。
典型的三种模型在三个阶段的精度变化如下:
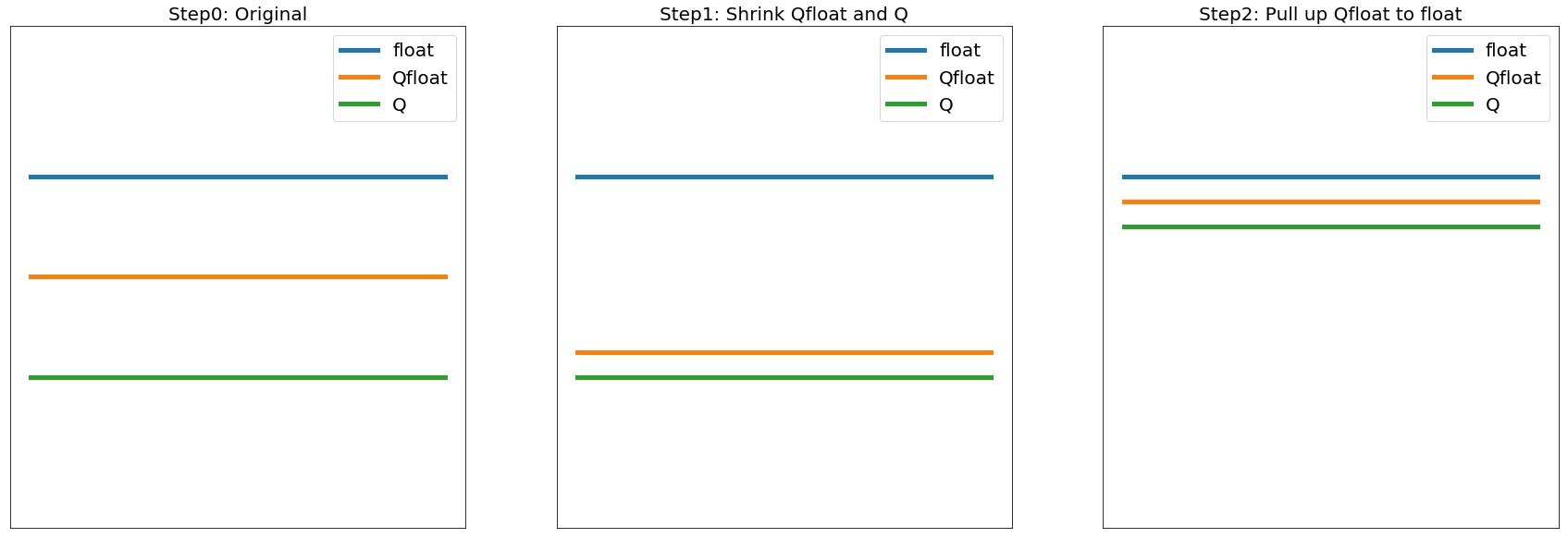
对应到具体的 MegEngine 接口中,三阶段如下:
- 基于 Module 搭建网络模型,并按照正常的浮点模型方式进行训练;
- 使用 quantize_qat 将浮点模型转换为 QFloat 模型, 其中可被量化的关键 Module 会被转换为 QATModule , 并基于量化配置 QConfig 设置好假量化算子和数值统计方式;
- 使用 quantize 将 QFloat 模型转换为 Q 模型, 对应的 QATModule 则会被转换为 QuantizedModule , 此时网络无法再进行训练,网络中的算子都会转换为低比特计算方式,即可用于部署了。

此处为标准量化流程,实际使用时也可有灵活的变化。
ResNet 实例讲解
下面我们以 ResNet18 为例来讲解量化的完整流程。主要分为以下几步:
- 修改网络结构,使用已经融合好的 ConvBn2d、ConvBnRelu2d、ElementWise 代替原先的 Module. 在正常模式下预训练模型,并在每轮迭代保存网络检查点;
- 调用 quantize_qat 转换模型,并进行量化感知训练微调(或校准,取决于 QConfig);
- 调用 quantize 转换为量化模型,导出模型用于后续模型部署。
详细操作指南文档见:ResNet 实例讲解
附:
「MegEngine 使用小技巧」系列文章,重点输出 MegEngine 及周边工具的使用技巧,如有催更或投稿,欢迎联系我们哦~
技术交流 QQ 群:1029741705;Bot 微信:megengine-bot
更多 MegEngine 信息获取,您可以:查看文档和 GitHub 项目。欢迎参与 MegEngine 社区贡献,成为 Awesome MegEngineer,荣誉证书、定制礼品享不停。
MegEngine 使用小技巧:使用 Netron 实现模型可视化
近期社区有多个同学问,如何查看 MegEngine 训练出的模型网络结构。其实在去年 8 月,MegEngine 就已经集成到了 Netron 平台上。
目前 Netron 已支持 MegEngine 模型:TracedModule 及 C++ 计算图两种结构。
二者的实现方法完全一致:只需直接拖拽本地模型文件到 网页版 netron,便可得到完整的模型结构图,并点击查看每层结构的细节参数。
如下图:
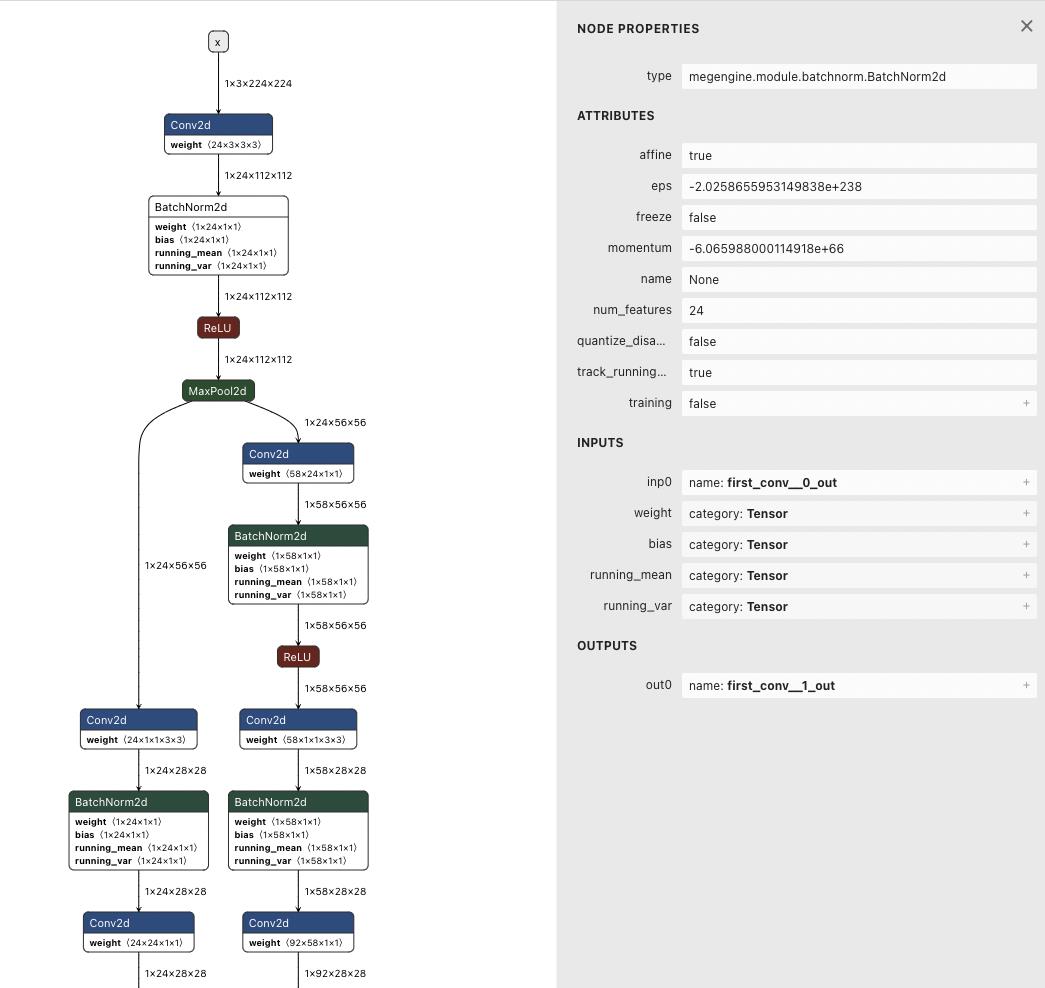
当然大家也可以通过「netron 客户端」或「Python Server」的方式,得到同样结果。
详细操作指南见文档:
MegEngine 模型可视化 - MegEngine 1.12 文档www.megengine.org.cn/doc/stable/zh/user-guide/tools/viewmodel.html
但在实操时,有几点需要注意的地方:
TracedModule 格式
-
Netron 需要是 6.0.0 及以上版本,为了保证最优体验效果,建议使用最新版本;
-
保存 TracedModule 模型文件时需要用 .tm 作为文件后缀,推荐使用 megengine.save 和 megengine.load 保存和加载 TracedModule;
-
因为 tm 格式的模型有很多子 module ,为了让大家更好的了解他们之间的链接关系,所以在做可视化展示时,各子图是全部展开的,以一张图来完整展示模型结构。
C++ 格式
-
Netron 使用 6.5.3 及以上版本,为了保证最优体验效果,建议使用最新版本;
-
MegEngine 版本:v1.10.0 及以上;
欢迎大家通过以下样例模型,试用该功能~
附:
更多 MegEngine 信息获取,您可以:查看文档和 GitHub 项目,或加入 MegEngine 用户交流 QQ 群:1029741705。欢迎参与 MegEngine 社区贡献,成为 Awesome MegEngineer,荣誉证书、定制礼品享不停。
以上是关于MegEngine 使用小技巧:量化的主要内容,如果未能解决你的问题,请参考以下文章
MegEngine 使用小技巧:使用 Optimizer 优化参数
提速还能不掉点!深度解析 MegEngine 4 bits 量化开源实现