怎样在Android中解析doc,docx,xls,xlsx格式文
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎样在Android中解析doc,docx,xls,xlsx格式文相关的知识,希望对你有一定的参考价值。
安卓系统手机下载可以下载以下应用程序就可以打开doc和exe格式的文档了。1、可以在手机上下载安装金山公司推出的金山WPS Office手机版。
此软件运行于Android平台上的全功能办公软件,支持查看、创建和编辑各种常用Office文档,支持DOC/DOCX/WPS/XLS/XLSX/ET/PPT/PPTX/TXT等26种文件格式。而且永久免费。
2、也可以在手机上下载安装软件 “Documents To Go”
Documents To Go 能够进行幻灯片编辑、阅读以及PDF阅读功能,也能对Word文档和 Excel表格进行阅读与编辑,对文档作复制、粘贴、插入等各种编辑动作。但是Documents To Go专业版是要收费的。 参考技术A 都为office07版格式,不知道你要求什么 参考技术B 噢谢谢几位
我诺基亚c5-00(pdf off)
纯js判断文件流格式类型:pdf,doc,docx,xls,xlsx,ppt,pptx一次搞定!
目录
使用js判断文件类型的场景
在开发纯前端基于react框架的文件预览组件时,需要根据不同的文件类型,分发给不同的组件去完成预览。网上已有的开源项目通常是通过传递文件名参数,通过后缀名字符串匹配区分文件类型。
但是这种做法需要用户传递准确文件名称与后缀名,如果你的文件是从服务端获取的,也同样要求后端开发准确拥有这些信息。可是,如果能直接从文件流中判断出文件类型的话,文件名参数完全可以省略,就能实现预览效果,对用户或是服务端的依赖就大大降低了。
这个文件预览项目与本文实现的功能函数github地址,都放在文件末尾了。目前实现了react框架pdf,xls,xlsx,docx这几种格式的预览,其中pdf预览实现了toolbar的基础操作功能。欢迎批评交流,如果有帮到你,请帮我点亮star吧。
方法特点
网络上很多方法仅仅通过文件流的头部编码,只能区分文件属于Microsoft2003规范(doc,xls,ppt)或Microsoft2007规范(docx,xlsx,pptx),但是对同一版本内部的具体类型是无法区分的。因为Microsoft2007规范的docx,xlsx,pptx等格式,本质上都是zip类型的文件,文件流开头的几位16进制数都是统一的“0x50,0x4b,0x03,0x04,…”。本方法在区分这两类规范的基础上进行了扩展,能有效识别各个规范下的具体文件类型。
输入输出
输入:文件的arrayBuffer数据
输出:‘file2003,file2007,pdf,doc,docx,xls,xlsx,ppt,pptx,other’之一。
方法步骤
1. 查看每种格式文件的16进制码,提取不同文件类型的“特征数”。
这一步用vscode就能完成。首先可以安装一款Hex Editor插件,用来展示16进制文件流。
把文件放到vscode中打开,左边是文档的16进制码(0x25,0x50…),右边是将16进制数转换成的ascii码(通过String.fromCharCode就可以转换)。这种模式可以直观地看到每个文件的关键词信息。
pdf文件的开头几个数字是唯一的,因此只要拿到文件流,很好判断一定是pdf文件。
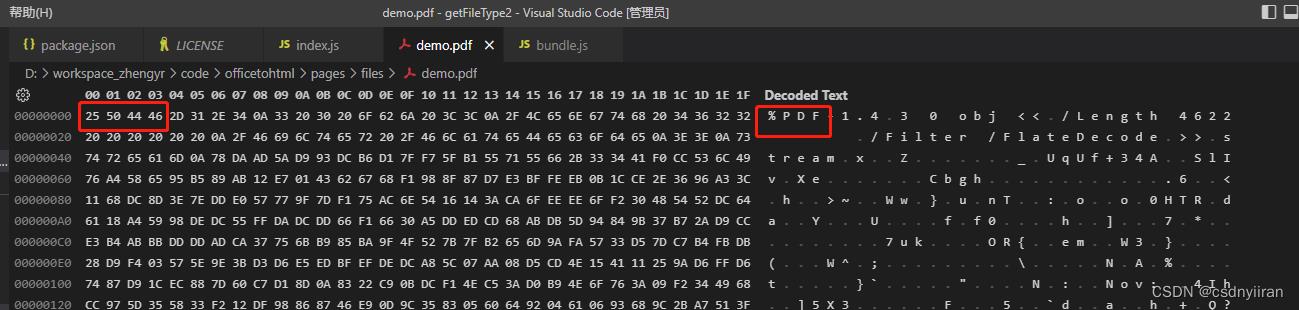
docx,xlsx,pptx文件的文件头标识信息是一样的,通过这几位固定数字能判断出来是Microsoft2007新标准的文件。

但是这些文件的结尾位置也出现了关键词,而且是每种类型唯一的,因此不仅可以获取文件头,也可以专门获取文件尾部的一段数据来判断。
下图是docx文件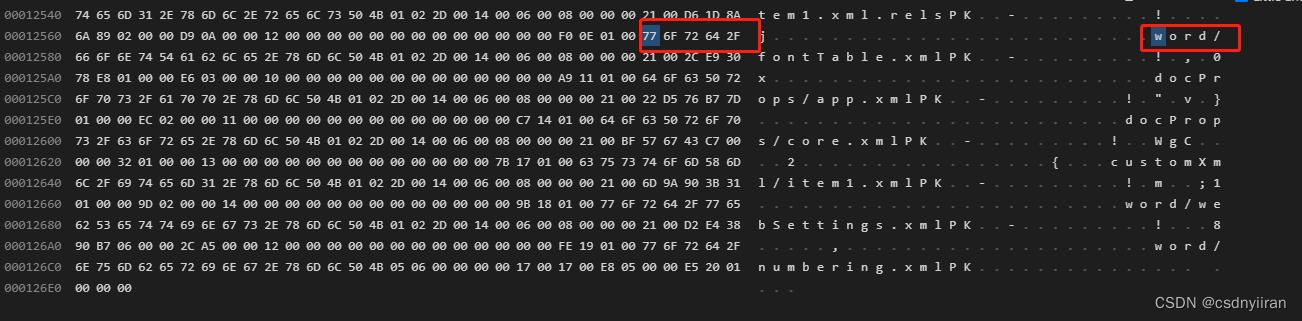
下图是xlsx文件,关键词是/worksheets
同理,pptx文件的关键词是ppt/,也出现在文件结尾位置。
Microsoft2003规范的文件开头,都是统一的’d0’, ‘cf’, ‘11’, ‘e0’。
xls的关键词是Microsoft Excel。
doc的关键词是Microsoft Word。
ppt的关键词是PowerPoint Document。
下面的工作就是,获取文件流的不同位置的数据,放在一个数组中,来判断这个数组是否包含以上含有特征的16进制数。
2. 先判断大类型,在具体大类下判断小类型
1)需要整理一下刚刚总结的各个格式与特征数的对应关系,整理成json格式。
//大类
const formatMap =
'pdf': ['25', '50', '44', '46'],`在这里插入代码片`
'file2003': ['d0', 'cf', '11', 'e0'],
'file2007': ['50', '4b', '03', '04', '14', '00', '06', '00'],
//区分xlsx,pptx,docx三种格式的特征数。通过每个文件末尾的关键词检索判断
const format2007Map =
xlsx: ['77', '6f', '72', '6b', '73', '68', '65', '65', '74', '73', '2f'],// 转换成ascii码的含义是 worksheets/
docx: ['77', '6f', '72', '64', '2f'],// 转换成ascii码的含义是 word/
pptx: ['70', '70', '74', '2f'],// 转换成ascii码的含义是 ppt/
//区分xls,ppt,doc三种格式的特征数,关键词同样出现在文件末尾
const pptFormatList = ['50', '6f', '77', '65', '72', '50', '6f', '69', '6e', '74', '20', '44', '6f', '63', '75', '6d', '65', '6e', '74'];// 转换成ascii码的含义是 PowerPoint Document
const format2003Map =
xls: ['4d', '69', '63', '72', '6f', '73', '6f', '66', '74', '20', '45', '78', '63', '65', '6c'],// 转换成ascii码的含义是 Microsoft Excel
doc: ['4d', '69', '63', '72', '6f', '73', '6f', '66', '74', '20', '57', '6f', '72', '64'],// 转换成ascii码的含义是 Microsoft Word
ppt: pptFormatList.join(',00,').split(',')
//xls格式的文件还有一种例外情况,就是保存为.html格式的文件。特征码是office:excel
let xlsHtmlTarget = ['6f', '66', '66', '69', '63', '65', '3a', '65', '78', '63', '65', '6c'];
2)把arraybuffer数据先使用Unit8Array转换成数组,再转化成16进制(为便于比较,省略了’0x’,只保留后两位)。同时,我们每次运算不需要使用全部的数组数据,而是找到对应位置的一部分,所以通过slice方法来截取我们期望位置的数组。
这里要说明,具体应该截取文件的什么位置,是打开若干个文件之后估计的大概范围,这个范围越大,匹配的成功率越高,但是要在数组遍历的效率之间做一个平衡。不排除有一些文件因为标准兼容的问题,关键词出现的位置跟我们截取的位置不一样,导致最后判断错误的可能性。
//截取部分数组,并转化成16进制
function getSliceArrTo16(arr, start, end)
let newArr = arr.slice(start, end);
return Array.prototype.map
.call(newArr, (x) => ('00' + x.toString(16)).slice(-2));
//判断arr数组是否包含target数组,且不能乱序。如果数组比较小,直接将两个数组转换成字符串比较。
//在数组长度大于500的情况下,写了如下方法来提高检索的效率:
function isListContainsTarget(target, arr)
let i = 0;
while (i < arr.length)
if (arr[i] == target[0])
let temp = arr.slice(i, i + target.length);
if (temp.join() === target.join())
return true
i++;
具体的判断方法:
export default function getFileTypeFromArrayBuffer(arrayBuffer)
try
if (Object.prototype.toString.call(arrayBuffer) !== '[object ArrayBuffer]')
throw new TypeError("The provided value is not a valid ArrayBuffer type.")
let arr = new Uint8Array(arrayBuffer);
let str_8 = getSliceArrTo16(arr, 0, 8).join(''); //只截取了前8位
//为了简便,匹配的位置索引我选择在代码里直接固定写出,你也可以把相应的索引配置在json数据里。
//第一次匹配,只匹配数组前八位,得到大范围的模糊类型
let result = '';
for (let type in formatMap)
let target = formatMap[type].join('');
if (~str_8.indexOf(target)) //相当于(str_8.indexOf(target) !== '-1')
result = type;
break;
if (!result)
//第一次匹配失败,不属于file2003,file2007,pdf。有可能是html格式的xls文件
//通过前50-150位置判断是否是xls
let arr_start_16 = getSliceArrTo16(arr, 50, 150);
if (~(arr_start_16.join('').indexOf(xlsHtmlTarget.join(''))))
return 'xls';
return 'other';
if (result == 'pdf')
return result;
if (result == 'file2007')
//默认是xlsx,pptx,docx三种格式中的一种,进行第二次匹配.如果未匹配到,结果仍然是file2007
let arr_500_16 = getSliceArrTo16(arr, -500);
for (let type in format2007Map)
let target = format2007Map[type];
if (isListContainsTarget(target, arr_500_16))
result = type;
break;
return result;
if (result == 'file2003')
let arr_end_16 = getSliceArrTo16(arr, -550, -440);
for (let type in format2003Map)
let target = format2003Map[type];
//通过倒数440-550位置判断是否是doc/ppt/xls
if (~(arr_end_16.join('').indexOf(target.join(''))))
result = type;
break
return result;
//未匹配成功
return 'other';
项目地址:
纯前端基于react实现的多类型文件预览:
https://github.com/react-office-viewer/react-office-viewer.git,
通过arraybuffer判断文件类型:
https://github.com/react-office-viewer/getFileTypeFromArrayBuffer.git
结语
最后,本文最希望的就是为大家提供一种区分文件格式的思路,在实际操作中可以用更加丰富细致的标准来不断提升判断的准确率。欢迎大家留言交流。
以上是关于怎样在Android中解析doc,docx,xls,xlsx格式文的主要内容,如果未能解决你的问题,请参考以下文章
如何在android中读取.doc、.docx、.xls文件[重复]
如何根据文件头识别doc、docx、pdf、xls和xlsx
java读取txt/pdf/xls/xlsx/doc/docx/ppt/pptx
uniapp 打开文档,支持格式:doc, xls, ppt, pdf, docx, xlsx, pptx