纯js判断文件流格式类型:pdf,doc,docx,xls,xlsx,ppt,pptx一次搞定!
Posted csdnyiiran
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了纯js判断文件流格式类型:pdf,doc,docx,xls,xlsx,ppt,pptx一次搞定!相关的知识,希望对你有一定的参考价值。
目录
使用js判断文件类型的场景
在开发纯前端基于react框架的文件预览组件时,需要根据不同的文件类型,分发给不同的组件去完成预览。网上已有的开源项目通常是通过传递文件名参数,通过后缀名字符串匹配区分文件类型。
但是这种做法需要用户传递准确文件名称与后缀名,如果你的文件是从服务端获取的,也同样要求后端开发准确拥有这些信息。可是,如果能直接从文件流中判断出文件类型的话,文件名参数完全可以省略,就能实现预览效果,对用户或是服务端的依赖就大大降低了。
这个文件预览项目与本文实现的功能函数github地址,都放在文件末尾了。目前实现了react框架pdf,xls,xlsx,docx这几种格式的预览,其中pdf预览实现了toolbar的基础操作功能。欢迎批评交流,如果有帮到你,请帮我点亮star吧。
方法特点
网络上很多方法仅仅通过文件流的头部编码,只能区分文件属于Microsoft2003规范(doc,xls,ppt)或Microsoft2007规范(docx,xlsx,pptx),但是对同一版本内部的具体类型是无法区分的。因为Microsoft2007规范的docx,xlsx,pptx等格式,本质上都是zip类型的文件,文件流开头的几位16进制数都是统一的“0x50,0x4b,0x03,0x04,…”。本方法在区分这两类规范的基础上进行了扩展,能有效识别各个规范下的具体文件类型。
输入输出
输入:文件的arrayBuffer数据
输出:‘file2003,file2007,pdf,doc,docx,xls,xlsx,ppt,pptx,other’之一。
方法步骤
1. 查看每种格式文件的16进制码,提取不同文件类型的“特征数”。
这一步用vscode就能完成。首先可以安装一款Hex Editor插件,用来展示16进制文件流。
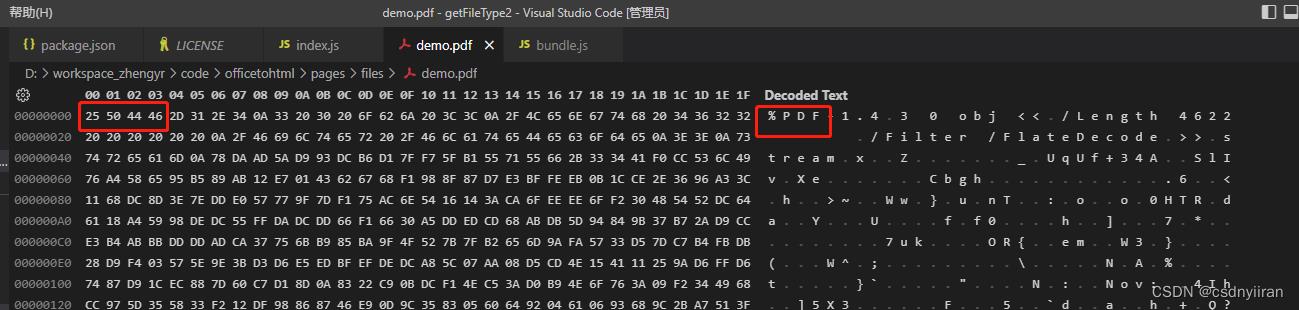
把文件放到vscode中打开,左边是文档的16进制码(0x25,0x50…),右边是将16进制数转换成的ascii码(通过String.fromCharCode就可以转换)。这种模式可以直观地看到每个文件的关键词信息。
pdf文件的开头几个数字是唯一的,因此只要拿到文件流,很好判断一定是pdf文件。
docx,xlsx,pptx文件的文件头标识信息是一样的,通过这几位固定数字能判断出来是Microsoft2007新标准的文件。

但是这些文件的结尾位置也出现了关键词,而且是每种类型唯一的,因此不仅可以获取文件头,也可以专门获取文件尾部的一段数据来判断。
下图是docx文件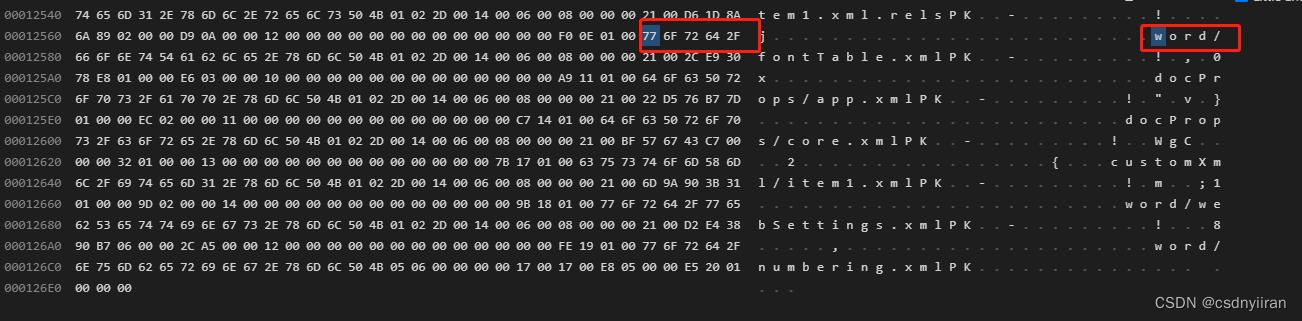
下图是xlsx文件,关键词是/worksheets
同理,pptx文件的关键词是ppt/,也出现在文件结尾位置。
Microsoft2003规范的文件开头,都是统一的’d0’, ‘cf’, ‘11’, ‘e0’。
xls的关键词是Microsoft Excel。
doc的关键词是Microsoft Word。
ppt的关键词是PowerPoint Document。
下面的工作就是,获取文件流的不同位置的数据,放在一个数组中,来判断这个数组是否包含以上含有特征的16进制数。
2. 先判断大类型,在具体大类下判断小类型
1)需要整理一下刚刚总结的各个格式与特征数的对应关系,整理成json格式。
//大类
const formatMap =
'pdf': ['25', '50', '44', '46'],`在这里插入代码片`
'file2003': ['d0', 'cf', '11', 'e0'],
'file2007': ['50', '4b', '03', '04', '14', '00', '06', '00'],
//区分xlsx,pptx,docx三种格式的特征数。通过每个文件末尾的关键词检索判断
const format2007Map =
xlsx: ['77', '6f', '72', '6b', '73', '68', '65', '65', '74', '73', '2f'],// 转换成ascii码的含义是 worksheets/
docx: ['77', '6f', '72', '64', '2f'],// 转换成ascii码的含义是 word/
pptx: ['70', '70', '74', '2f'],// 转换成ascii码的含义是 ppt/
//区分xls,ppt,doc三种格式的特征数,关键词同样出现在文件末尾
const pptFormatList = ['50', '6f', '77', '65', '72', '50', '6f', '69', '6e', '74', '20', '44', '6f', '63', '75', '6d', '65', '6e', '74'];// 转换成ascii码的含义是 PowerPoint Document
const format2003Map =
xls: ['4d', '69', '63', '72', '6f', '73', '6f', '66', '74', '20', '45', '78', '63', '65', '6c'],// 转换成ascii码的含义是 Microsoft Excel
doc: ['4d', '69', '63', '72', '6f', '73', '6f', '66', '74', '20', '57', '6f', '72', '64'],// 转换成ascii码的含义是 Microsoft Word
ppt: pptFormatList.join(',00,').split(',')
//xls格式的文件还有一种例外情况,就是保存为.html格式的文件。特征码是office:excel
let xlsHtmlTarget = ['6f', '66', '66', '69', '63', '65', '3a', '65', '78', '63', '65', '6c'];
2)把arraybuffer数据先使用Unit8Array转换成数组,再转化成16进制(为便于比较,省略了’0x’,只保留后两位)。同时,我们每次运算不需要使用全部的数组数据,而是找到对应位置的一部分,所以通过slice方法来截取我们期望位置的数组。
这里要说明,具体应该截取文件的什么位置,是打开若干个文件之后估计的大概范围,这个范围越大,匹配的成功率越高,但是要在数组遍历的效率之间做一个平衡。不排除有一些文件因为标准兼容的问题,关键词出现的位置跟我们截取的位置不一样,导致最后判断错误的可能性。
//截取部分数组,并转化成16进制
function getSliceArrTo16(arr, start, end)
let newArr = arr.slice(start, end);
return Array.prototype.map
.call(newArr, (x) => ('00' + x.toString(16)).slice(-2));
//判断arr数组是否包含target数组,且不能乱序。如果数组比较小,直接将两个数组转换成字符串比较。
//在数组长度大于500的情况下,写了如下方法来提高检索的效率:
function isListContainsTarget(target, arr)
let i = 0;
while (i < arr.length)
if (arr[i] == target[0])
let temp = arr.slice(i, i + target.length);
if (temp.join() === target.join())
return true
i++;
具体的判断方法:
export default function getFileTypeFromArrayBuffer(arrayBuffer)
try
if (Object.prototype.toString.call(arrayBuffer) !== '[object ArrayBuffer]')
throw new TypeError("The provided value is not a valid ArrayBuffer type.")
let arr = new Uint8Array(arrayBuffer);
let str_8 = getSliceArrTo16(arr, 0, 8).join(''); //只截取了前8位
//为了简便,匹配的位置索引我选择在代码里直接固定写出,你也可以把相应的索引配置在json数据里。
//第一次匹配,只匹配数组前八位,得到大范围的模糊类型
let result = '';
for (let type in formatMap)
let target = formatMap[type].join('');
if (~str_8.indexOf(target)) //相当于(str_8.indexOf(target) !== '-1')
result = type;
break;
if (!result)
//第一次匹配失败,不属于file2003,file2007,pdf。有可能是html格式的xls文件
//通过前50-150位置判断是否是xls
let arr_start_16 = getSliceArrTo16(arr, 50, 150);
if (~(arr_start_16.join('').indexOf(xlsHtmlTarget.join(''))))
return 'xls';
return 'other';
if (result == 'pdf')
return result;
if (result == 'file2007')
//默认是xlsx,pptx,docx三种格式中的一种,进行第二次匹配.如果未匹配到,结果仍然是file2007
let arr_500_16 = getSliceArrTo16(arr, -500);
for (let type in format2007Map)
let target = format2007Map[type];
if (isListContainsTarget(target, arr_500_16))
result = type;
break;
return result;
if (result == 'file2003')
let arr_end_16 = getSliceArrTo16(arr, -550, -440);
for (let type in format2003Map)
let target = format2003Map[type];
//通过倒数440-550位置判断是否是doc/ppt/xls
if (~(arr_end_16.join('').indexOf(target.join(''))))
result = type;
break
return result;
//未匹配成功
return 'other';
项目地址:
纯前端基于react实现的多类型文件预览:
https://github.com/react-office-viewer/react-office-viewer.git,
通过arraybuffer判断文件类型:
https://github.com/react-office-viewer/getFileTypeFromArrayBuffer.git
结语
最后,本文最希望的就是为大家提供一种区分文件格式的思路,在实际操作中可以用更加丰富细致的标准来不断提升判断的准确率。欢迎大家留言交流。
用java读取多种文件格式的文件(pdf,pptx,ppt,doc,docx..)
本文通过开源pdfbox和poi进行处理多种文件格式的文本读入
1.需要的jar的maven坐标:
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.2</version>
</dependency>
<!-- ppt,xls,docx,pptx,xlsx-->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.xmlbeans</groupId>
<artifactId>xmlbeans</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
处理多种文件格式,详情见代码:
1 package cn.lcg.utils; 2 3 import java.io.File; 4 import java.io.FileInputStream; 5 import java.io.IOException; 6 import java.text.NumberFormat; 7 import java.util.List; 8 9 import org.apache.pdfbox.pdmodel.PDDocument; 10 import org.apache.pdfbox.text.PDFTextStripper; 11 import org.apache.poi.hslf.extractor.PowerPointExtractor; 12 import org.apache.poi.hssf.usermodel.HSSFCell; 13 import org.apache.poi.hssf.usermodel.HSSFRow; 14 import org.apache.poi.hssf.usermodel.HSSFSheet; 15 import org.apache.poi.hssf.usermodel.HSSFWorkbook; 16 import org.apache.poi.hwpf.HWPFDocument; 17 import org.apache.poi.hwpf.usermodel.Range; 18 import org.apache.poi.ss.usermodel.Cell; 19 import org.apache.poi.xslf.usermodel.XMLSlideShow; 20 import org.apache.poi.xslf.usermodel.XSLFSlide; 21 import org.apache.poi.xslf.usermodel.XSLFSlideShow; 22 import org.apache.poi.xssf.usermodel.XSSFCell; 23 import org.apache.poi.xssf.usermodel.XSSFRow; 24 import org.apache.poi.xssf.usermodel.XSSFSheet; 25 import org.apache.poi.xssf.usermodel.XSSFWorkbook; 26 import org.apache.poi.xwpf.extractor.XWPFWordExtractor; 27 import org.apache.poi.xwpf.usermodel.XWPFDocument; 28 import org.openxmlformats.schemas.drawingml.x2006.main.CTRegularTextRun; 29 import org.openxmlformats.schemas.drawingml.x2006.main.CTTextBody; 30 import org.openxmlformats.schemas.drawingml.x2006.main.CTTextParagraph; 31 import org.openxmlformats.schemas.presentationml.x2006.main.CTGroupShape; 32 import org.openxmlformats.schemas.presentationml.x2006.main.CTShape; 33 import org.openxmlformats.schemas.presentationml.x2006.main.CTSlide; 34 35 /** 36 * 37 * @author yujian 38 * @date 2016年10月12日 39 * @version 0.0.1 40 */ 41 public class FileFormat { 42 /** 43 * 用来读取doc文件的方法 44 * @param filePath 45 * @return 46 * @throws Exception 47 */ 48 public static String getTextFromDoc(String filePath) throws Exception{ 49 StringBuilder sb = new StringBuilder(); 50 FileInputStream fis = new FileInputStream(new File(filePath)); 51 HWPFDocument doc = new HWPFDocument(fis); 52 Range rang = doc.getRange(); 53 sb.append(rang.text()); 54 fis.close(); 55 return sb.toString(); 56 57 } 58 /** 59 * 用来读取docx文件 60 * @param filePath 61 * @return 62 * @throws IOException 63 * @throws Exception 64 */ 65 @SuppressWarnings("resource") 66 public static String getTextFromDocx(String filePath) throws IOException { 67 FileInputStream in = new FileInputStream(filePath); 68 XWPFDocument doc = new XWPFDocument(in); 69 XWPFWordExtractor extractor = new XWPFWordExtractor(doc); 70 String text = extractor.getText(); 71 in.close(); 72 return text; 73 } 74 /** 75 * 用来读取pdf文件 76 * @param filePath 77 * @return 78 * @throws IOException 79 */ 80 public static String getTextFromPDF(String filePath) throws IOException{ 81 File input = new File(filePath); 82 PDDocument pd = PDDocument.load(input); 83 PDFTextStripper stripper = new PDFTextStripper(); 84 return stripper.getText(pd); 85 } 86 /** 87 * 用来读取ppt文件 88 * @param filePath 89 * @return 90 * @throws IOException 91 */ 92 public static String getTextFromPPT( String filePath) throws IOException{ 93 FileInputStream in = new FileInputStream(filePath); 94 PowerPointExtractor extractor = new PowerPointExtractor(in); 95 String content = extractor.getText(); 96 extractor.close(); 97 return content; 98 } 99 /** 100 * 用来读取pptx文件 101 * @param filePath 102 * @return 103 * @throws IOException 104 */ 105 public static String getTextFromPPTX( String filePath) throws IOException{ 106 String resultString = null; 107 StringBuilder sb = new StringBuilder(); 108 FileInputStream in = new FileInputStream(filePath); 109 try { 110 XMLSlideShow xmlSlideShow = new XMLSlideShow(in); 111 List<XSLFSlide> slides = xmlSlideShow.getSlides(); 112 for(XSLFSlide slide:slides){ 113 CTSlide rawSlide = slide.getXmlObject(); 114 CTGroupShape gs = rawSlide.getCSld().getSpTree(); 115 CTShape[] shapes = gs.getSpArray(); 116 for(CTShape shape:shapes){ 117 CTTextBody tb = shape.getTxBody(); 118 if(null==tb){ 119 continue; 120 } 121 CTTextParagraph[] paras = tb.getPArray(); 122 for(CTTextParagraph textParagraph:paras){ 123 CTRegularTextRun[] textRuns = textParagraph.getRArray(); 124 for(CTRegularTextRun textRun:textRuns){ 125 sb.append(textRun.getT()); 126 } 127 } 128 } 129 } 130 resultString = sb.toString(); 131 xmlSlideShow.close(); 132 } catch (Exception e) { 133 e.printStackTrace(); 134 } 135 return resultString; 136 } 137 /** 138 * 用来读取xls 139 * @param filePath 140 * @return 141 * @throws IOException 142 */ 143 public static String getTextFromxls(String filePath) throws IOException{ 144 FileInputStream in = new FileInputStream(filePath); 145 StringBuilder content = new StringBuilder(); 146 HSSFWorkbook workbook = new HSSFWorkbook(in); 147 for(int sheetIndex=0;sheetIndex<workbook.getNumberOfSheets();sheetIndex++){ 148 HSSFSheet sheet = workbook.getSheetAt(sheetIndex); 149 for(int rowIndex=0;rowIndex<=sheet.getLastRowNum();rowIndex++){ 150 HSSFRow row = sheet.getRow(rowIndex); 151 if(row==null){ 152 continue; 153 } 154 for(int cellnum=0;cellnum<row.getLastCellNum();cellnum++){ 155 HSSFCell cell = row.getCell(cellnum); 156 if(cell!=null){ 157 content.append(cell.getRichStringCellValue().getString()+" "); 158 } 159 160 } 161 } 162 163 } 164 workbook.close(); 165 return content.toString(); 166 167 } 168 /** 169 * 用来读取xlsx文件 170 * @param filePath 171 * @return 172 * @throws IOException 173 */ 174 public static String getTextFromxlsx(String filePath) throws IOException{ 175 StringBuilder content = new StringBuilder(); 176 XSSFWorkbook workbook = new XSSFWorkbook(filePath); 177 for(int sheet=0;sheet<workbook.getNumberOfSheets();sheet++){ 178 if(null!=workbook.getSheetAt(sheet)){ 179 XSSFSheet aSheet =workbook.getSheetAt(sheet); 180 for(int row=0;row<=aSheet.getLastRowNum();row++){ 181 if(null!=aSheet.getRow(row)){ 182 XSSFRow aRow = aSheet.getRow(row); 183 for(int cell=0;cell<aRow.getLastCellNum();cell++){ 184 if(null!=aRow.getCell(cell)){ 185 XSSFCell aCell = aRow.getCell(cell); 186 if(convertCell(aCell).length()>0){ 187 content.append(convertCell(aCell)); 188 } 189 } 190 content.append(" "); 191 } 192 } 193 } 194 } 195 } 196 workbook.close(); 197 return content.toString(); 198 199 } 200 201 private static String convertCell(Cell cell){ 202 NumberFormat formater = NumberFormat.getInstance(); 203 formater.setGroupingUsed(false); 204 String cellValue=""; 205 if(cell==null){ 206 return cellValue; 207 } 208 209 switch(cell.getCellType()){ 210 case HSSFCell.CELL_TYPE_NUMERIC: 211 cellValue = formater.format(cell.getNumericCellValue()); 212 break; 213 case HSSFCell.CELL_TYPE_STRING: 214 cellValue = cell.getStringCellValue(); 215 break; 216 case HSSFCell.CELL_TYPE_BLANK: 217 cellValue = cell.getStringCellValue(); 218 break; 219 case HSSFCell.CELL_TYPE_BOOLEAN: 220 cellValue = Boolean.valueOf(cell.getBooleanCellValue()).toString(); 221 break; 222 case HSSFCell.CELL_TYPE_ERROR: 223 cellValue = String.valueOf(cell.getErrorCellValue()); 224 break; 225 default:cellValue=""; 226 } 227 return cellValue.trim(); 228 } 229 }
解释的话就没有那么多时间,这些代码在我的项目中完全正确,所以你们可以放心使用。
以上是关于纯js判断文件流格式类型:pdf,doc,docx,xls,xlsx,ppt,pptx一次搞定!的主要内容,如果未能解决你的问题,请参考以下文章
antd upload上传格式.doc.docx.pdf.png.jpg.rar和大小100兆限制