如何用纯java代码实现word转pdf
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用纯java代码实现word转pdf相关的知识,希望对你有一定的参考价值。
几种方案:方法一:用apachepio读取doc文件,然后转成html文件用Jsoup格式化html文件,最后用itext将html文件转成pdf。方法2:使用jdoctopdf来实现,这是一个封装好的包,可以把doc转换成pdf,html,xml等格式,调用很方便地址:安装完后要启动openOffice的服务,具体启动方法请自行google方法4:效果最好的一种方法,但是需要window环境,而且速度是最慢的需要安装msofficeWord以及SaveAsPDFandXPS.exe(word的一个插件,用来把word转化为pdf)Office版本是2007,因为SaveAsPDFandXPS是微软为office2007及以上版本开发的插件SaveAsPDFandXPS下载地址:/zh-cn/download/details.aspx?id=7jacob包下载地址: 参考技术A 几种方案:方法一:用apache pio 读取doc文件,然后转成html文件用Jsoup格式化html文件,最后用itext将html文件转成pdf。
方法2:使用jdoctopdf来实现,这是一个封装好的包,可以把doc转换成pdf,html,xml等格式,调用很方便
地址:http://www.maxstocker.com/jdoctopdf/downloads.php
需要注意中文字体的写入问题。
方法3:使用jodconverter来调用openOffice的服务来转换,openOffice有个各个平台的版本,所以这种方法跟方法1一样都是跨平台的。
jodconverter的下载地址:http://www.artofsolving.com/opensource/jodconverter
首先要安装openOffice,下载地址:http://www.openoffice.org/download/index.html
安装完后要启动openOffice的服务,具体启动方法请自行google
方法4:效果最好的一种方法,但是需要window环境,而且速度是最慢的需要安装msofficeWord以及SaveAsPDFandXPS.exe(word的一个插件,用来把word转化为pdf)
Office版本是2007,因为SaveAsPDFandXPS是微软为office2007及以上版本开发的插件
SaveAsPDFandXPS下载地址:http://www.microsoft.com/zh-cn/download/details.aspx?id=7
jacob 包下载地址:http://sourceforge.net/projects/jacob-project/
JAVA实现无损word转pdf文件完整代码教程

前言
本来想写word转pdf和pdf转word的代码呢,没想到word转pdf就写了很多很多行代码才实现,为了方便大家消化理解,先写了word转pdf方法实现作为一篇文章。
word转pdf实现思路
代码实现主要依赖两个第三方jar包,一个是pdfbox,一个是aspose-words。pdfbox包完全开源免费,aspose-words免费版生成有水印,且生成数量有限制。单纯用pdfbox 实现word转pdf的话,实现非常复杂,且样式和原来样式,保持一致的的比例很低。所以,我先用aspose-words生成了带水印的pdf,再用pdfbox去除aspose-words生成的水印的,最终得到了一个无水印的pdf。
项目远程仓库
aspose-words 这个需要配置单独的仓库地址才能下载,不会配置的可以去官网直接下载jar引入项目代码中。
<repositories>
<repository>
<id>AsposeJavaAPI</id>
<name>Aspose Java API</name>
<url>https://repository.aspose.com/repo/</url>
</repository>
</repositories>Maven项目pom文件依赖
<!-- https://mvnrepository.com/artifact/org.apache.pdfbox/pdfbox -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.github.jai-imageio</groupId>
<artifactId>jai-imageio-jpeg2000</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>com.aspose</groupId>
<artifactId>aspose-words</artifactId>
<version>21.9</version>
<type>pom</type>
</dependency>
核心代码实现
import com.aspose.words.Document;
import com.aspose.words.SaveFormat;
import org.apache.pdfbox.Loader;
import org.apache.pdfbox.contentstream.operator.Operator;
import org.apache.pdfbox.cos.COSArray;
import org.apache.pdfbox.cos.COSDictionary;
import org.apache.pdfbox.cos.COSName;
import org.apache.pdfbox.cos.COSString;
import org.apache.pdfbox.pdfparser.PDFStreamParser;
import org.apache.pdfbox.pdfwriter.ContentStreamWriter;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageTree;
import org.apache.pdfbox.pdmodel.PDResources;
import org.apache.pdfbox.pdmodel.common.PDStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class PDFHelper3 {
public static void main(String[] args) throws IOException {
doc2pdf("C:\\\\Users\\\\liuya\\\\Desktop\\\\word\\\\帆软报表帮助文档.docx");
}
//替换pdf文本内容
public static void replaceText(PDPage page, String searchString, String replacement) throws IOException {
PDFStreamParser parser = new PDFStreamParser(page);
List<?> tokens = parser.parse();
for (int j = 0; j < tokens.size(); j++) {
Object next = tokens.get(j);
if (next instanceof Operator) {
Operator op = (Operator) next;
String pstring = "";
int prej = 0;
if (op.getName().equals("Tj")) {
COSString previous = (COSString) tokens.get(j - 1);
String string = previous.getString();
string = string.replaceFirst(searchString, replacement);
previous.setValue(string.getBytes());
} else if (op.getName().equals("TJ")) {
COSArray previous = (COSArray) tokens.get(j - 1);
for (int k = 0; k < previous.size(); k++) {
Object arrElement = previous.getObject(k);
if (arrElement instanceof COSString) {
COSString cosString = (COSString) arrElement;
String string = cosString.getString();
if (j == prej) {
pstring += string;
} else {
prej = j;
pstring = string;
}
}
}
if (searchString.equals(pstring.trim())) {
COSString cosString2 = (COSString) previous.getObject(0);
cosString2.setValue(replacement.getBytes());
int total = previous.size() - 1;
for (int k = total; k > 0; k--) {
previous.remove(k);
}
}
}
}
}
List<PDStream> contents = new ArrayList<>();
Iterator<PDStream> streams = page.getContentStreams();
while (streams.hasNext()) {
PDStream updatedStream = streams.next();
OutputStream out = updatedStream.createOutputStream(COSName.FLATE_DECODE);
ContentStreamWriter tokenWriter = new ContentStreamWriter(out);
tokenWriter.writeTokens(tokens);
contents.add(updatedStream);
out.close();
}
page.setContents(contents);
}
//移除图片水印
public static void removeImage(PDPage page, String cosName) {
PDResources resources = page.getResources();
COSDictionary dict1 = resources.getCOSObject();
resources.getXObjectNames().forEach(e -> {
if (resources.isImageXObject(e)) {
COSDictionary dict2 = dict1.getCOSDictionary(COSName.XOBJECT);
if (e.getName().equals(cosName)) {
dict2.removeItem(e);
}
}
page.setResources(new PDResources(dict1));
});
}
//移除文字水印
public static boolean removeWatermark(File file) {
try {
//通过文件名加载文档
PDDocument document = Loader.loadPDF(file);
PDPageTree pages = document.getPages();
Iterator<PDPage> iter = pages.iterator();
while (iter.hasNext()) {
PDPage page = iter.next();
//去除文字水印
replaceText(page, "Evaluation Only. Created with Aspose.Words. Copyright 2003-2021 Aspose", "");
replaceText(page, "Pty Ltd.", "");
replaceText(page, "Created with an evaluation copy of Aspose.Words. To discover the full", "");
replaceText(page, "versions of our APIs please visit: https://products.aspose.com/words/", "");
replaceText(page, "This document was truncated here because it was created in the Evaluation", "");
//去除图片水印
removeImage(page, "X1");
}
document.removePage(document.getNumberOfPages() - 1);
file.delete();
document.save(file);
document.close();
return true;
} catch (IOException ex) {
ex.printStackTrace();
return false;
}
}
//doc文件转pdf(目前最大支持21页)
public static void doc2pdf(String wordPath) {
long old = System.currentTimeMillis();
try {
//新建一个pdf文档
String pdfPath=wordPath.substring(0,wordPath.lastIndexOf("."))+".pdf";
File file = new File(pdfPath);
FileOutputStream os = new FileOutputStream(file);
//Address是将要被转化的word文档
Document doc = new Document(wordPath);
//全面支持DOC, DOCX, OOXML, RTF HTML, OpenDocument, PDF, EPUB, XPS, SWF 相互转换
doc.save(os, SaveFormat.PDF);
os.close();
//去除水印
removeWatermark(new File(pdfPath));
//转化用时
long now = System.currentTimeMillis();
System.out.println("Word 转 Pdf 共耗时:" + ((now - old) / 1000.0) + "秒");
} catch (Exception e) {
System.out.println("Word 转 Pdf 失败...");
e.printStackTrace();
}
}
}
结果分析
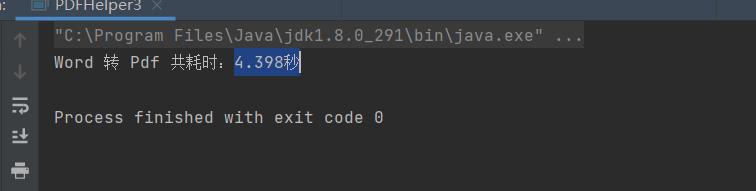
以一个带文字和图片,工21页的doc文件为例,word转pdf花费时长4.398秒
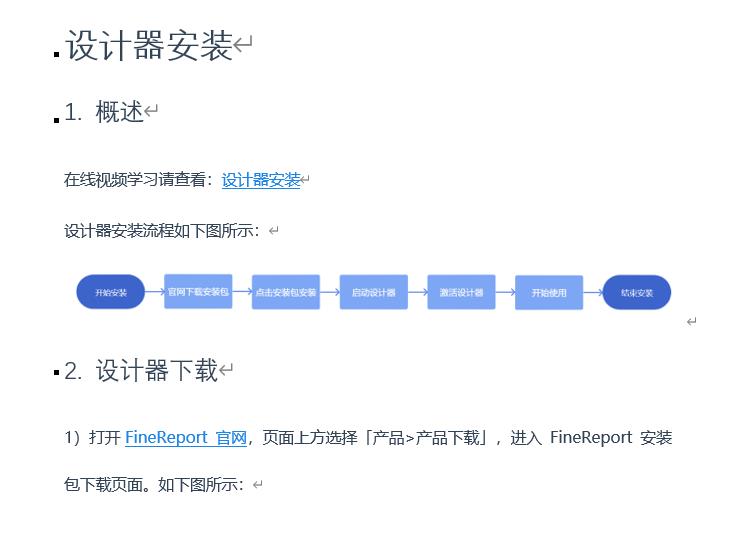
原word样式
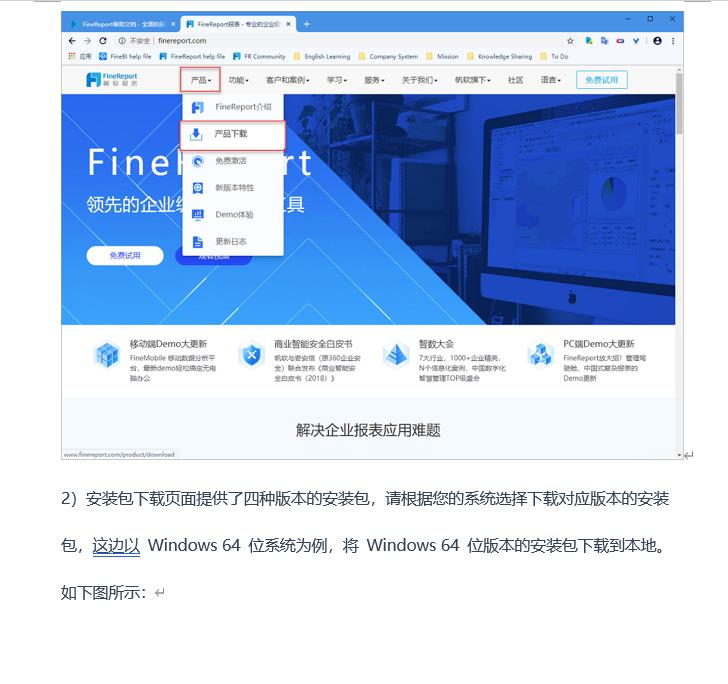 转化后pdf效果图
转化后pdf效果图
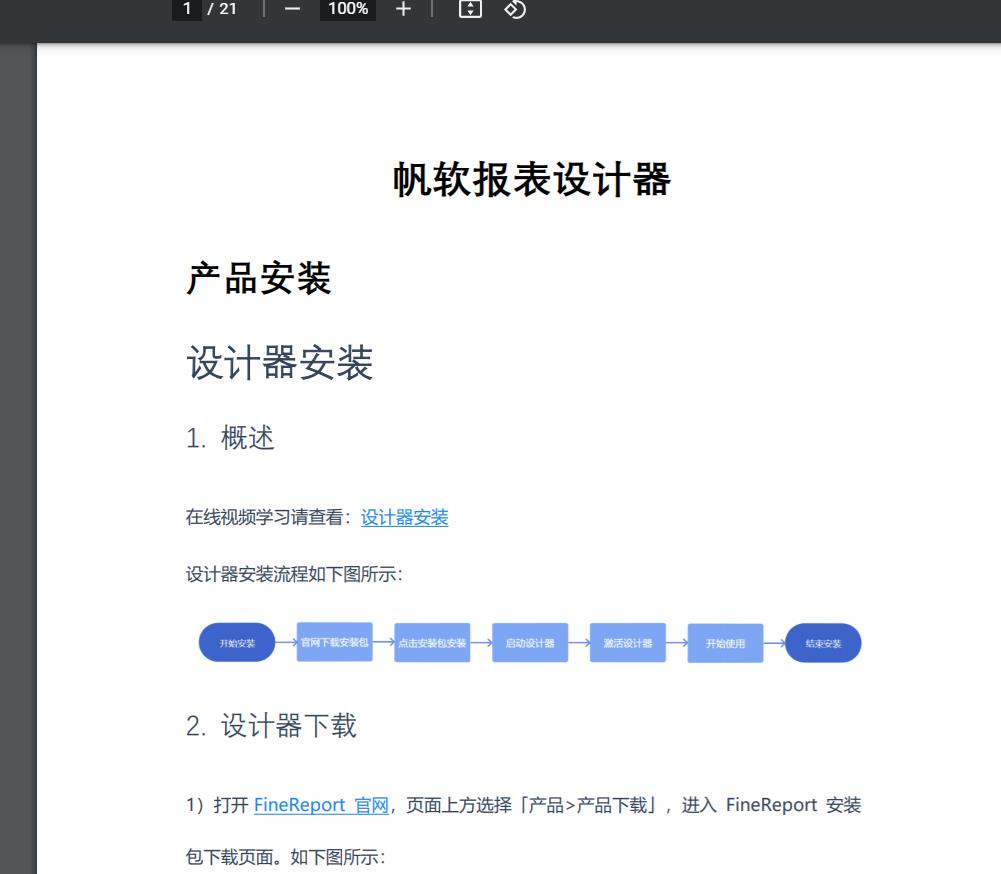
通过对比,word原来的样式和转换pdf文件后的样式基本没有变化。
相关文章推荐
JAVA实现PDF合并、拆分代码工具类 https://blog.csdn.net/weixin_40986713/article/details/120065363
https://blog.csdn.net/weixin_40986713/article/details/120065363
以上是关于如何用纯java代码实现word转pdf的主要内容,如果未能解决你的问题,请参考以下文章
Java 代码实现pdf转word文件 | 无损转换完整代码教程