音频处理库性能对比:计算mel频谱的速度哪个更快?
Posted CMLab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音频处理库性能对比:计算mel频谱的速度哪个更快?相关的知识,希望对你有一定的参考价值。
介绍
音频信号处理在各种应用中都发挥着重要的作用,如语音识别、音乐信息检索、语音合成等。其中,Mel频谱是一种常用的频域特征表示方法,用于描述人类听觉系统对频率的敏感程度。
在深度学习音频领域,mel频谱是最常用的音频特征。在本文中,我们将对四个常用的音频处理库——audioflux、torchaudio、librosa和essentia——进行性能测试,以评估它们在计算Mel频谱时的效率。
| Library | Language | Version | About |
|---|---|---|---|
| audioFlux | C/Python | 0.1.5 | A library for audio and music analysis, feature extraction |
| torchaudio | Python | 0.11.0 | Data manipulation and transformation for audio signal processing, powered by PyTorch |
| librosa | Python | 0.10.0 | C++ library for audio and music analysis, description and synthesis, including Python bindings |
| essentia | C++/Python | 2.0.1 | Python library for audio and music analysis |
audioFlux:基于C开发和python包装,底层针对不同平台有不同的桥接处理,支持OpenBLAS,MKL等
TorchAudio: 基于pytorch开发,pytorch基于C++开发和python包装,底层使用MKL,pytorch针对CPU是高度优化的(本篇评测不涉及到GPU版pytorch);
librosa: 纯python开发,主要基于numpy和scipy,numpy底层使用OpenBLAS;
Essentia: 基于C++开发和python包装,底层使用Eigen,FFTW;
针对音频领域最常见的mel特征,涉及到性能主要卡点有FFT计算,矩阵计算,多线程并行处理这三部分,其它次要卡点有算法业务实现,python包装等。
针对FFT计算,librosa使用scipy的fftpack实现FFT计算加速,比FFTW3,MKL,Accelerate要慢一些;
针对矩阵计算,MKL比OpenBLAS要快些,OpenBLAS比其Eigen快一些;
针对多线程并行处理,具体各个项目内部是否有支持。
测试脚本
- 测试多个库,使用以下方式:
$ python run_benchmark.py -p audioflux,torchaudio,librosa -r 1000 -er 10 -t 1,5,10,100,500,1000,2000,3000
- -p: The library name, list
- -r: The number of sample data, number
- -er: The number of
run_xxx.pycalls, number - -t: The time of each sample data, list
- 测试单个库,使用以下方式:
$ python run_audioflux.py -r 1000 -t 1,5,10,100,500,1000,2000,3000
- 需要更多的命令功能,可以
python run_xxx.py --help
注意
在音频领域,与音频特征提取相关的库具有自己的功能特点,并提供不同类型的特征。本次评估并不旨在详细测试所有特征提取的性能比较,但是由于梅尔频谱是最重要和基础的特征之一,因此所有这些库都支持它。
许多因素会影响性能评估结果,如 CPU 架构、操作系统、编译系统、基本线性代数库的选择以及项目 API 的使用,这些因素都会对评估结果产生一定的影响。为了尽可能公平地反映实际业务需求,本次评估基于以下条件:
- macOS/Linux 操作系统,三种 CPU:Intel/AMD/M1。
- 库使用最新的官方发布版本或使用具有高性能支持的最新官方源代码编译,并选择最快的版本。
- 在 API 使用方面,遵循官方标准,并对每个库的相应方法进行“预热”(不计算第一次执行时间),并不计算初始化的执行时间。
- 在数据长度方面,选择测试数据时考虑各种实际业务需求。
当数据较短时,大多数库的第一次执行时间可能相对较慢。为了反映实际业务需求并保持公平,不计算第一次执行时间。如果库的 API 设计提供了初始化函数,则在实际业务场景中会创建并重复调用它们,初始化的执行时间也不计入评估结果。
警告
⚠️ 当使用 Conda、PyTorch、TensorFlow、XGBoost、LightGBM 等 Python 科学计算相关的库时,几乎所有这些库都使用 Intel Math Kernel Library (MKL)。MKL 使用 OpenMP 进行并行加速,但是在同一进程中只能存在一个 OpenMP 实例。当这些库一起使用时,最好将所有库链接到 libomp 的相同位置,否则会出现错误。根据提示修改环境变量可能会导致程序执行变慢并产生不可靠的结果。相关工具可以用于重写相关库的 libomp 链接路径。
性能
使用 audioFlux/torchaudio/librosa 库, 针对 AMD/Intel/M1 CPUs and Linux/macOS 系统。
计算1000个样本数据的mel频谱,针对 1/5/10/100/500/1000/2000/3000每个样本尺寸大小。 参数为 fft_len=2048, slide_len=512, sampling_rate=32000。
Linux - AMD
- OS: Ubuntu 20.04.4 LTS
- CPU: AMD Ryzen Threadripper 3970X 32-Core Processor
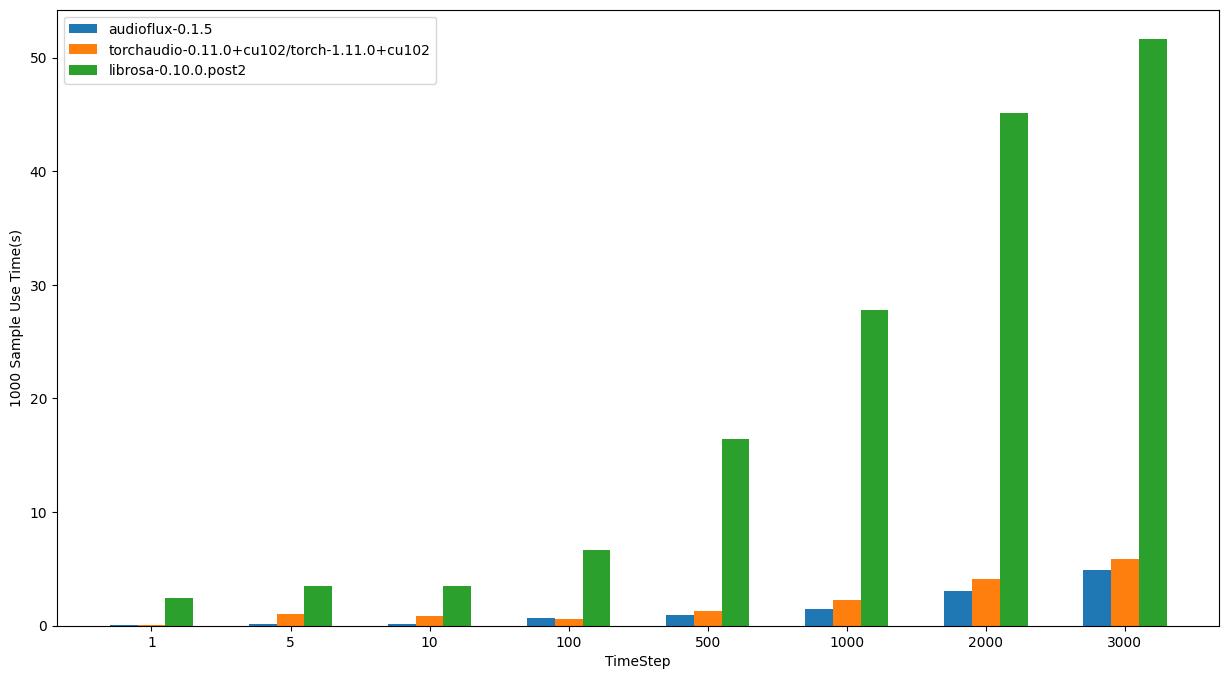
| TimeStep | audioflux | torchaudio | librosa |
|---|---|---|---|
| 1 | 0.04294s | 0.07707s | 2.41958s |
| 5 | 0.14878s | 1.05589s | 3.52610s |
| 10 | 0.18374s | 0.83975s | 3.46499s |
| 100 | 0.67030s | 0.61876s | 6.63217s |
| 500 | 0.94893s | 1.29189s | 16.45968s |
| 1000 | 1.43854s | 2.23126s | 27.78358s |
| 2000 | 3.08714s | 4.10869s | 45.12714s |
| 3000 | 4.90343s | 5.86299s | 51.62876s |
Linux - Intel
- OS: Ubuntu 20.04.4 LTS
- CPU: Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz

| TimeStep | audioflux | torchaudio | librosa |
|---|---|---|---|
| 1 | 0.08106s | 0.11043s | 5.51295s |
| 5 | 0.11654s | 0.16005s | 5.77631s |
| 10 | 0.29173s | 0.15352s | 6.13656s |
| 100 | 1.18150s | 0.39958s | 10.61641s |
| 500 | 2.23883s | 1.58323s | 28.99823s |
| 1000 | 4.42723s | 3.98896s | 51.97518s |
| 2000 | 8.73121s | 8.28444s | 61.13923s |
| 3000 | 13.07378s | 12.14323s | 70.06395s |
macOS - Intel
- OS: 12.6.1 (21G217)
- CPU: 3.8GHz 8‑core 10th-generation Intel Core i7, Turbo Boost up to 5.0GHz
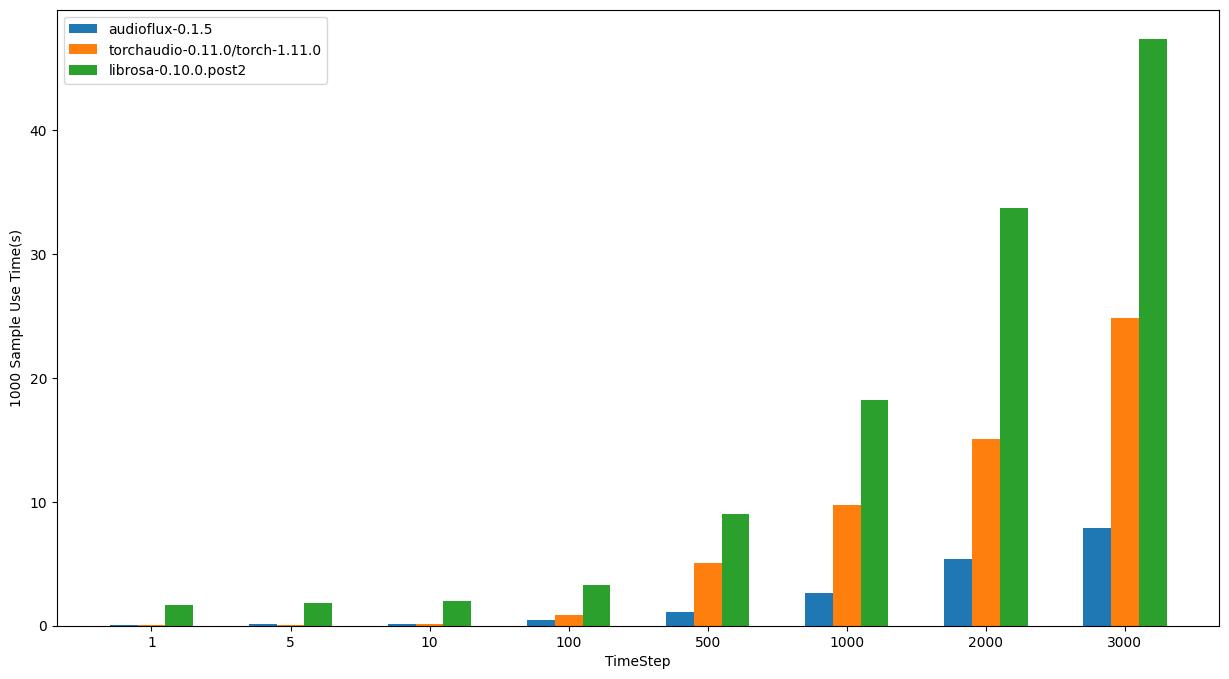
| TimeStep | audioflux | torchaudio | librosa |
|---|---|---|---|
| 1 | 0.07605s | 0.06451s | 1.70139s |
| 5 | 0.14946s | 0.08464s | 1.86964s |
| 10 | 0.16641s | 0.10762s | 2.00865s |
| 100 | 0.46902s | 0.83551s | 3.28890s |
| 500 | 1.08860s | 5.05824s | 8.98265s |
| 1000 | 2.64029s | 9.78269s | 18.24391s |
| 2000 | 5.40025s | 15.08991s | 33.68184s |
| 3000 | 7.92596s | 24.84823s | 47.35941s |
macOS - M1
- OS: 12.4 (21F79)
- CPU: Apple M1
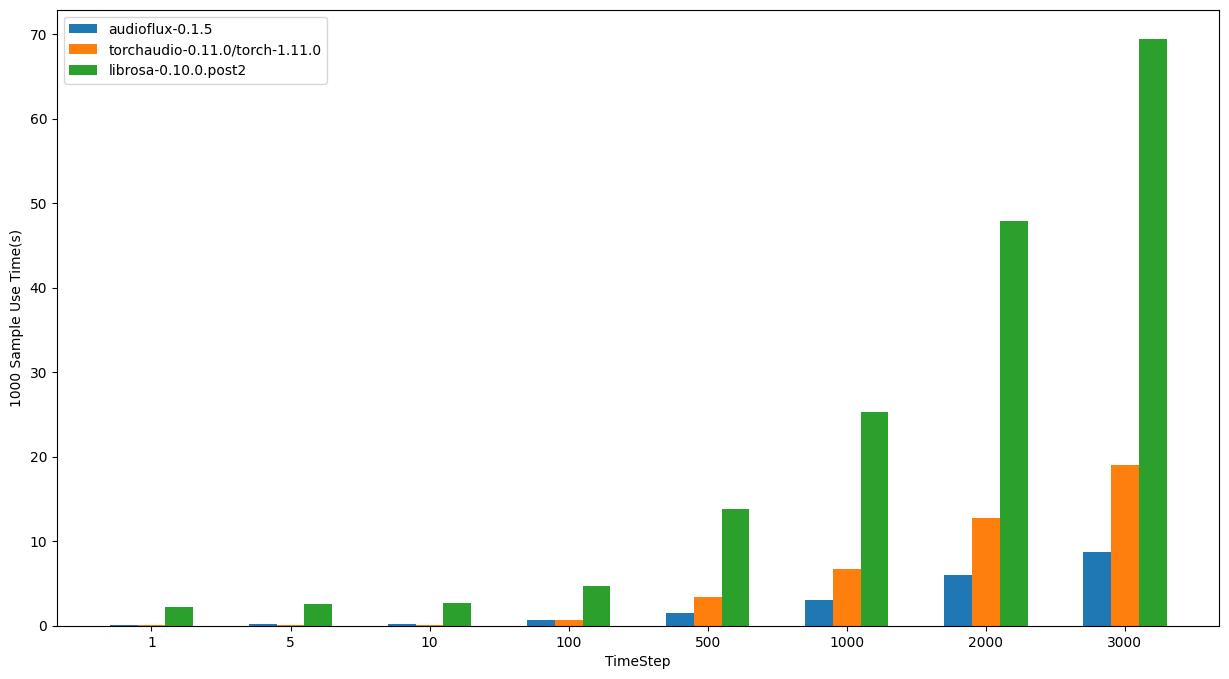
| TimeStep | audioflux | torchaudio | librosa |
|---|---|---|---|
| 1 | 0.06110s | 0.06874s | 2.22518s |
| 5 | 0.23444s | 0.07922s | 2.55907s |
| 10 | 0.20691s | 0.11090s | 2.71813s |
| 100 | 0.68694s | 0.63625s | 4.74433s |
| 500 | 1.47420s | 3.37597s | 13.83887s |
| 1000 | 3.00926s | 6.76275s | 25.24646s |
| 2000 | 5.99781s | 12.69573s | 47.84029s |
| 3000 | 8.76306s | 19.03391s | 69.40428s |
详细Benchmark和脚本: https://github.com/libAudioFlux/audioFlux/tree/master/benchmark
总结
总的来说,从三个库的性能比较结果来看,librosa 执行时间最长,这也符合常识。
在 linux/amd 处理器上,audioflux 比 torchaudio 稍快,但在 linux/intel 上稍慢。
在 macOS 系统上,对于大尺寸样本数据,audioflux 比 torchaudio 快,intel 比 m1 明显;对于小尺寸样本数据,torchaudio 比 audioflux 更快。
⚠️尽管本次基准测试的开发旨在尽可能客观和公正,但每个基准测试都有其缺点,并且限于特定的测试程序、数据集和平台。此外,本次基准测试未比较库可能支持的其他功能或其他 API、跨平台等。我们鼓励用户使用自己的数据集和平台进行基准测试。
如何从 librosa 中的 mel 频谱图重建 STFT 矩阵,以便重建原始音频?
【中文标题】如何从 librosa 中的 mel 频谱图重建 STFT 矩阵,以便重建原始音频?【英文标题】:How can I reconstruct the STFT matrix from a mel spectrogram in librosa so I reconstruct the original audio? 【发布时间】:2020-08-31 02:06:26 【问题描述】:我使用以下代码在 librosa 中生成了一个 melspectrogram
import os
from matplotlib import pyplot as plt
import librosa
import librosa.display
import pylab
import numpy as np
x, sr = librosa.load('audio/example.wav')
mel = librosa.feature.melspectrogram(x,sr)
P = librosa.power_to_db(mel, ref=np.max)
librosa.display.specshow(P)
pylab.savefig("example.png", bbox_inches=None, pad_inches=0)
据我了解,频谱图只是音频信号的 STFT 矩阵的直观表示。我正在尝试重建用于生成频谱图的 STFT 矩阵,以便将其传递给 griffin lim 函数。我该怎么做?
使用 STFT 数据生成频谱图
def generate_spectrogram(x, sr):
X = librosa.stft(x)
Xdb = librosa.amplitude_to_db(abs(X))
fig = plt.figure(figsize=(10, 10), dpi=100, frameon=False)
ax = fig.add_axes([0, 0, 1, 1], frameon=False)
ax.axis('off')
librosa.display.specshow(Xdb, sr=sr, cmap='gray', x_axis='time', y_axis='hz')
plt.savefig('example.png', quality=100, bbox_inches=0, pad_inches=0)
librosa.cache.clear()
【问题讨论】:
【参考方案1】:我不确定这个问题是否适合这个论坛的当前形式(堆栈交换可能更合适),但由于它与基于 DNN 的语音合成管道非常相关,我认为这是一个好主意稍微扩展一下。
我们不能从梅尔谱图中准确地重建 STFT。原因是我们 Mel 是 STFT 的“压缩”版本,其频率来自 Mel 标度,然后在这些频率上应用(到 STFT)三角滤波器。通常,我们会丢失从 STFT 到 mel 的信息。有关详细说明,请参阅这篇出色的文章。
https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
现在,回到您的问题 - 我假设您正在以 Tacotron [1] 工作的方式进行语音合成 - 为了应用 Griffin Lim,正如您正确指出的那样,我们需要线性频谱图。论文中的做法是使用神经网络将 Mel 转换为 STFT。他们称之为 postnet,因为它在 Mels 被预测后充当后处理器。
要设置此网络,请将地面实况(目标)音频转换为 Mels,并创建一个循环网络(CBHG 或其他任何东西)将其转换为 STFT 等价物。最大限度地减少这些 STFT 预测与我们可以从目标音频创建的实际 STFT 之间的损失。
[1]https://arxiv.org/abs/1703.10135
【讨论】:
我实际上正在使用频谱图进行音频风格传输,使用 cyclegans。我不确定您上面描述的将 Mel 转换为 STFT 的过程是否相同。如果我从 STFT 矩阵构造一个常规频谱图,而不是使用 librosa 的内置 melspectrogram 函数呢?由于 STFT 矩阵是从 librosa.stft 函数生成的,因此我能否将其从该频谱图中提取出来? 不确定我是否了解上下文(好像您正在尝试获取 STFT,但从 Mels 开始)。在 librosa 中,您可以通过 librosa.stft 直接获取 STFT,然后在 Griffin Lim 上使用它。您已经在 generate_spectrogram() 中这样做了。 librosa.org/doc/latest/generated/librosa.stft.html#librosa.stft 和 ***.com/questions/57058875/… 是的,如果我不清楚,这就是我想要做的对不起。我希望能够从生成的频谱图(以 png 形式)回到 STFT 矩阵。我正在将频谱图传递给循环器进行风格转换,并希望在频谱图被修改后重建音频。由于我使用 STFT 数据构建了频谱图,因此我正在寻找一种方法来反转该过程并检索 STFT,以便从修改后的图像中重建音频。 应该可以使用 Griffin Lim 程序从 STFT(这里将是 CycleGAN 的输出)恢复音频。网上有几个地方可以实现。请注意,频谱图不是“png”。该图像是光谱能量的视觉表示,但我们必须将其作为 numpy 数组存储在磁盘中。如果将其存储为图像,要获取频谱图,我们必须应用适当的缩放因子。 Griffin Lim 实施示例:zhuanlan.zhihu.com/p/25002923以上是关于音频处理库性能对比:计算mel频谱的速度哪个更快?的主要内容,如果未能解决你的问题,请参考以下文章