Whisper
Posted 蝈蝈俊的技术心得
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Whisper相关的知识,希望对你有一定的参考价值。
Whisper 是 OpenAI 公司开源的通用的语音识别模型。(https://github.com/openai/whisper )
它是在包含各种音频的大型数据集上训练的,是一个可以执行多语言语音识别、语音翻译和语言识别的多任务模型。
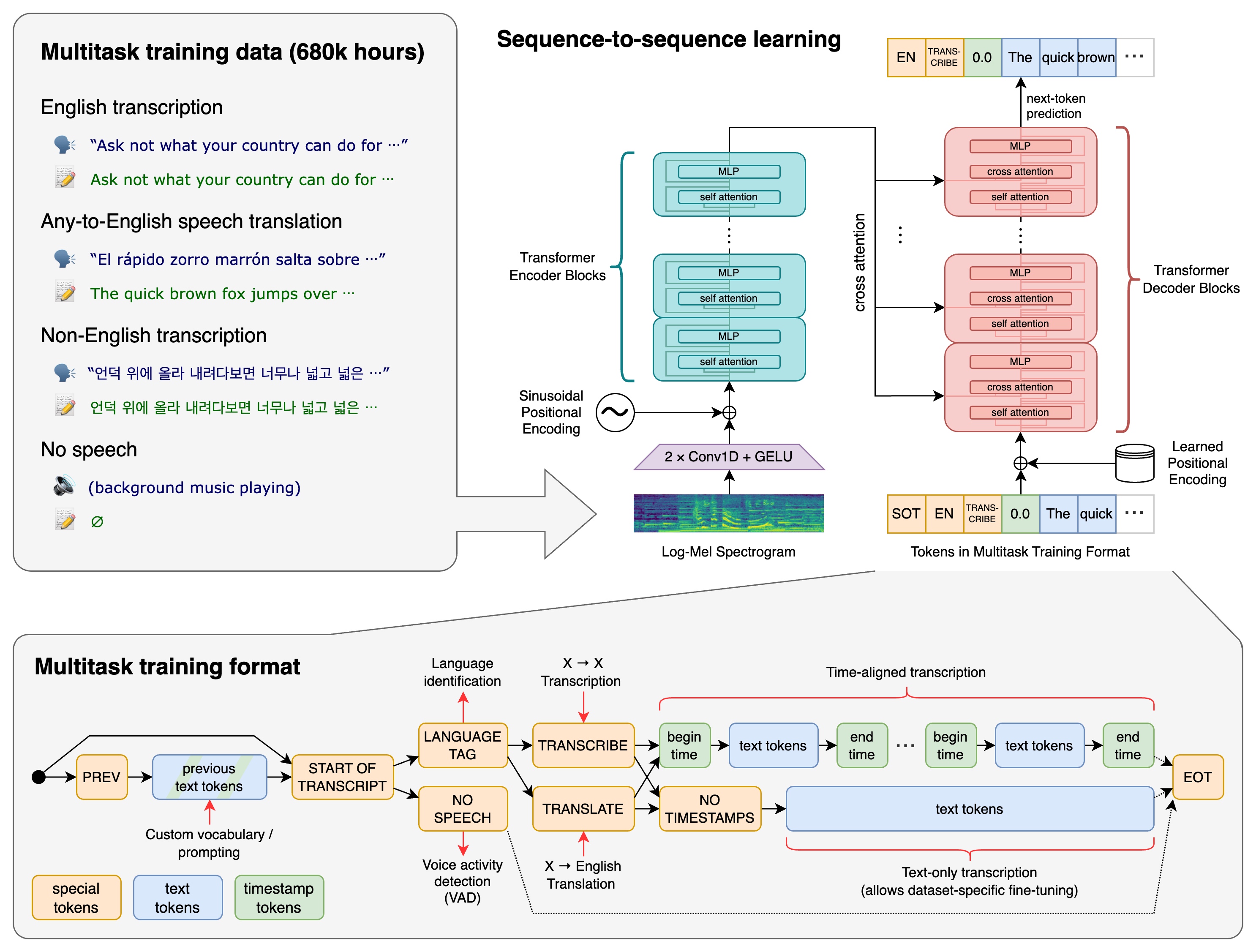
它也是一个针对各种语音处理任务进行训练的 Transformer 序列到序列模型。
Whisper 执行操作的大致过程:
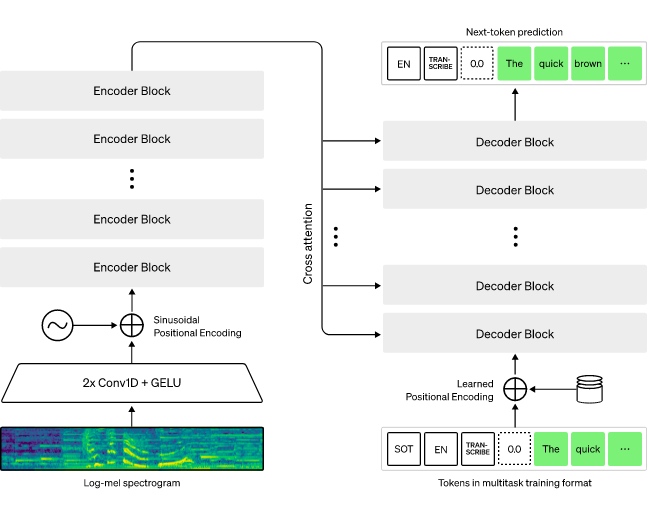
输入的音频被分割成 30 秒的小段、转换为 log-Mel 频谱图,然后传递到编码器。解码器经过训练以预测相应的文字说明,并与特殊的标记进行混合,这些标记指导单一模型执行诸如语言识别、短语级别的时间戳、多语言语音转录和语音翻译等任务。
使用示例
环境配置
brew install python # Python 3.8 以上版本
brew install pytorch # PyTorch 1.10 以上版本
# 依赖 OpenAI 的 tiktoken,用于实现快速分词,可能还需要安装 rust ,
# 以防 tiktoken 不为您的平台提供预构建的轮子。
brew install rust
brew install git # 下载 github 上的whisper
brew install ffmpeg # 处理音频
# 从该存储库中拉取并安装最新的提交及其 Python 依赖项:
pip install git+https://github.com/openai/whisper.git
完成上面配置后,就可以录音转文字了。
录音文件转文字
Whisper提供了两种使用方式:命令行和作为模块在python文件中调用。
命令行
下面是把小朋友读三字经的录音转文字:
$ whisper /Users/ghj1976/Downloads/20230507_185926.m4a --model base --language Chinese
/Users/ghj1976/opt/anaconda3/lib/python3.9/site-packages/whisper/transcribe.py:114: UserWarning: FP16 is not supported on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
[00:00.000 --> 00:07.520] 人之初,心本善,心相信,喜相怨,
[00:07.520 --> 00:10.920] 狗不叫,信乃天,
[00:10.920 --> 00:17.760] 教知到,貴一专,子不學,非死而以,
[00:17.760 --> 00:26.800] 又不學,老何為,一不著,不成氣,人不學,不知意,
其中,/Users/ghj1976/Downloads/20230507_185926.m4a 是你的语音文件路径。
目前 Whisper 有 9 种模型(分为纯英文和多语言),其中四种只有英文版本,开发者可以根据需求在速度和准确性之间进行权衡,以下是现有模型的大小,及其内存要求和相对速度,我们这里用的 base 模型。:
| Size 大小 |
Parameters 参数 |
English-only model 纯英文模型 |
Multilingual model 多语言模型 |
Required VRAM 所需显存 |
Relative speed 相对速度 |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
作为模块在python文件中调用
这里我们重点介绍下 initial_prompt 参数,它可以提高未知单词的识别准确性、按需生成文字。
initial_prompt 参数 提高未知单词的识别准确性
我们可以通过 initial_prompt 参数提升 Whisper 语音生成文字的质量,使用这个参数,模型会尝试尽量匹配提示的样式。
import whisper
import arrow
# 定义模型、音频地址、录音开始时间
def excute(model_name,file_path,start_time,initial_prompt):
model = whisper.load_model(model_name)
result = model.transcribe(file_path,initial_prompt=initial_prompt)
for segment in result["segments"]:
now = arrow.get(start_time)
start = now.shift(seconds=segment["start"]).format("YYYY-MM-DD HH:mm:ss")
end = now.shift(seconds=segment["end"]).format("YYYY-MM-DD HH:mm:ss")
print("【"+start+"->" +end+"】:"+segment["text"])
if __name__ == \'__main__\':
excute("base","480803359.mp3","2023-05-08 05:41:00", "Hum, you know, I I I would like to to say that... OK")
典型的使用场景如下:
- 更正模型在音频中经常错误识别的特定单词,或首字母缩略词。 比如以下提示改进了单词 DALL·E 和 GPT-3,,没有这个提示则会写成“GDP 3”和“DALI”。
The transcript is about OpenAI which makes technology like DALL·E, GPT-3, and ChatGPT with the hope of one day building an AGI system that benefits all of humanity
或者下面方式,可以转换出 DALL·E:
whisper audio.mp3 --initial_prompt "So we were just talking about DALL·E"
- 模型可能会跳过标点符号。您可以通过使用包含标点符号的简单提示来避免这种情况,如下面这个提示:
Hello, welcome to my lecture.
- 模型还可能省略音频中的常见填充词。如果要在结果中保留填充词,可以使用包含它们的提示:
Umm, let me think like, hmm... Okay, here\'s what I\'m, like, thinking."
- 有些语言可以用不同的方式书写,例如简体中文或繁体中文。默认情况下,模型可能并不总是使用您希望的成绩单写作风格。您可以通过使用首选写作风格的提示来改善这一点。
audio_file_path = "path/to/audio/file.wav"
prompt = "请将此转录为简体中文。"
transcription = whisper.transcribe(audio_file_path, prompt=prompt)
参考资料
OpenAI 开源语音识别 Whisper
Whisper是一个通用语音识别模型。它是在各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。
人工智能公司 OpenAI 拥有 GTP-3 语言模型,并为 GitHub Copilot 提供技术支持的 ,宣布开源了Whisper 自动语音识别系统,Open AI 强调 Whisper 的语音识别能力已达到人类水准。
在各种语音处理任务中训练Transformer序列到序列模型,包括多语言语音识别、语音翻译、口语识别和语音活动检测。所有这些任务都被联合表示为由解码器预测的令牌序列,允许单一模型取代传统语音处理管道的许多不同阶段。多任务训练格式使用一组特殊的令牌作为任务说明符或分类目标。

Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础

Whisper体系结构是一种简单的端到端方法,实现为编码器-解码器Transformer。输入音频被分成30秒的片段,转换成log-Mel谱图,然后传入编码器。解码器被训练来预测相应的文本标题,并混合特殊标记,指示单一模型执行诸如语言识别、短语级时间戳、多语言语音转录和英语语音翻译等任务。
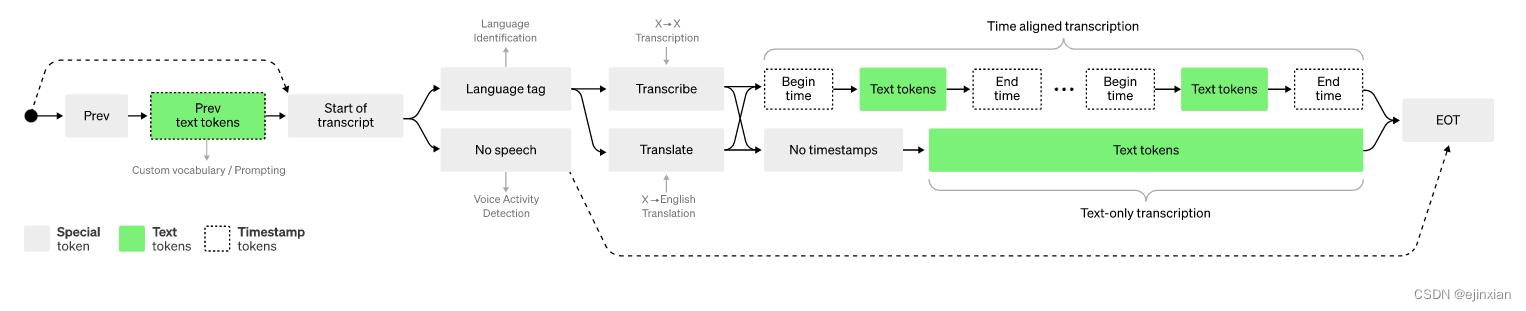
OpenAI 希望 Whisper 的高准确性和易用性可以让开发者在更广泛的应用中加入语音识别功能,尤其是用来协助改善无障碍工具。
参考:
https://cdn.openai.com/papers/whisper.pdf
以上是关于Whisper的主要内容,如果未能解决你的问题,请参考以下文章
为啥 Carbon 不根据更新的存储模式保留写入 Whisper 数据点?