CV语义分割到工作氛围杂谈
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CV语义分割到工作氛围杂谈相关的知识,希望对你有一定的参考价值。
CV语义分割到工作氛围杂谈
华人团队颠覆CV!SEEM完美分割一切爆火,一键分割「瞬息全宇宙」
Meta的「分割一切」的横空出世,让许多人惊呼CV不存在了。
基于这一模型,众网友纷纷做了进一步工作,比如Grounded SAM。




将Stable Diffusion、Whisper、ChatGPT结合使用,就能做到通过语音让一只狗变成一只猴子。而现在,不仅仅是语音,你可以通过多模态提示实现一次性分割所有地方的一切。具体怎么做?鼠标点一下,直接选中分割内容。张口一句话。随手一涂,完整的表情包就来了。甚至,还能分割视频。最新研究SEEM是由威斯康星大学麦迪逊分校、微软研究院等机构的学者共同完成。通过SEEM使用不同种类的提示,视觉提示(点、标记、框、涂鸦和图像片段)、以及语言提示(文本和音频)轻松分割图像。


论文地址:https://arxiv.org/pdf/2304.06718.pdf这个论文标题有意思的地方在于,与2022年上映的一部美国科幻电影「瞬息全宇宙」(Everything Everywhere All at Once)的名字非常相似。英伟达科学家Jim Fan表示,奥斯卡最佳论文标题奖颁给「Segment Everything Everywhere All at Once」拥有一个统一的、多功能的任务规范界面是扩大大型基础模型规模的关键。多模态提示是未来的方向。看过论文后,网友表示,CV现在也要开始拥抱大模型了,研究生未来出路在哪?

奥斯卡最佳标题论文
正是受到基于提示的LLMs通用接口发展的启发,研究人员提出了SEEM。
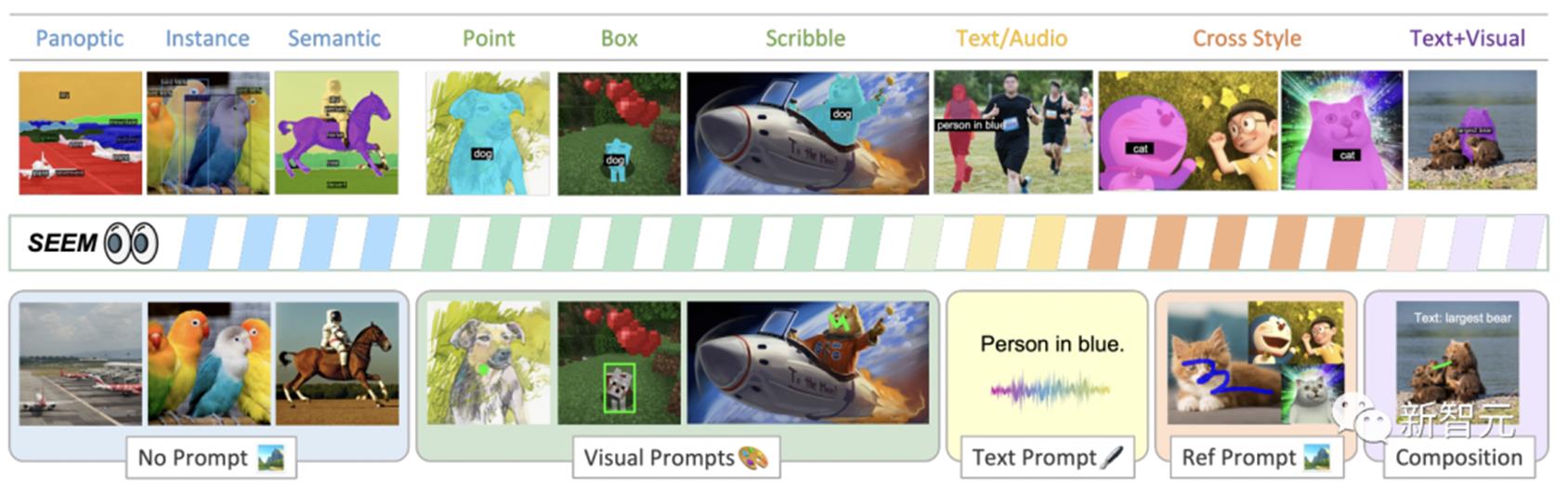
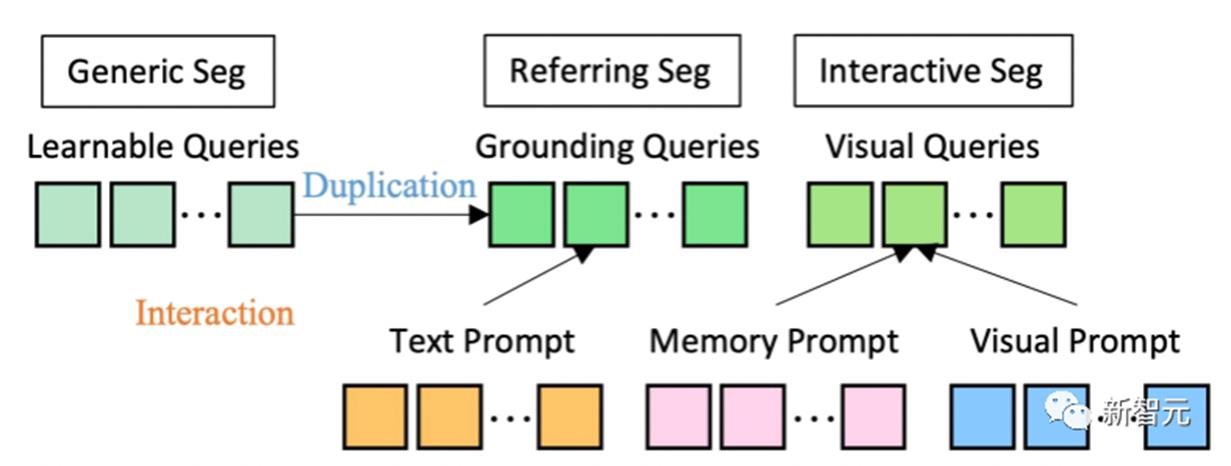
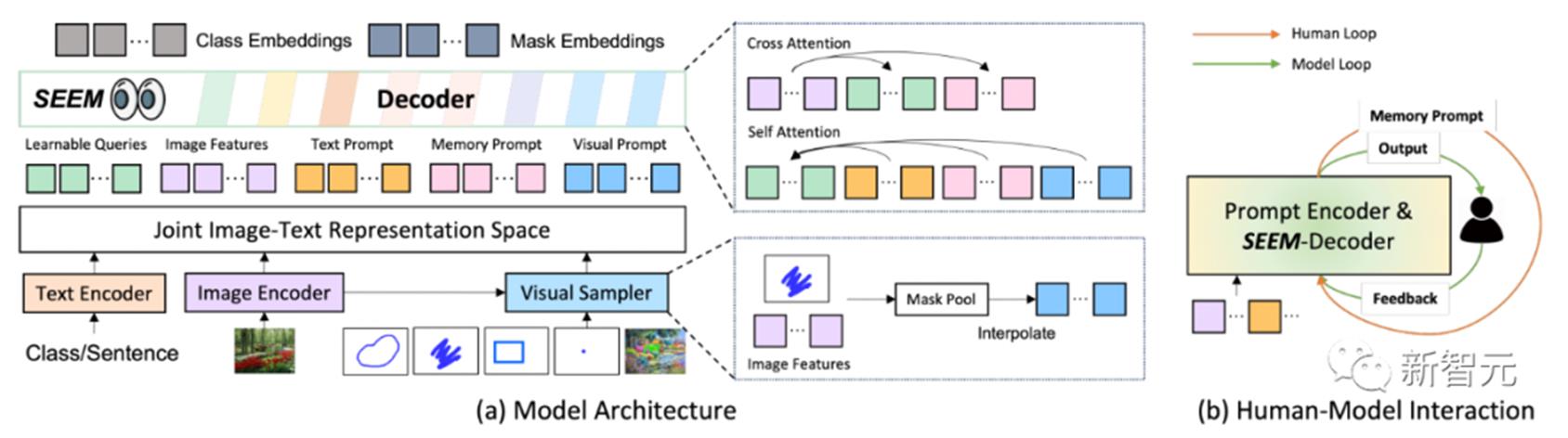
如图所示,SEEM模型可以在没有提示的开放集中执行任何分割任务,比如语义分割、实例分割和全景分割。此外,它还支持任意组合的视觉,文本和引用区域提示,允许多功能和交互式的引用分割。在模型架构上,SEEM采用了常见的编码器-解码器架构。其独特的地方在于具有查询和提示之间复杂的交互。特征和提示被相应的编码器,或采样器编码到一个联合的视觉语义空间。可学习查询是随机初始化,SEEM解码器接受可学习查询、图像特征和文本提示作为输入和输出,包括类和掩码嵌入,用于掩码和语义预测。值得一提的是,SEEM模型有多轮交互。每一轮都包含一个人工循环和一个模型循环。在人工循环中,人工接收上一次迭代的掩码输出,并通过视觉提示给出下一轮解码的正反馈。在模型循环中,模型接收并更新未来预测的记忆提示。通过SEEM,给一个擎天柱卡车的图,就能分割任何目标图像上的擎天柱。通过用户输入的文本生成掩模,进行一键分割。





另外,SEEM通过对引用图像的简单点击,或涂鸦,就能够对目标图像上有相似语义的对象进行分割。此外,SEEM非常了解解空间关系。左上行斑马被涂鸦后,也会分割出最左边的斑马。SEEM还可以将图像引用到视频掩码,不需要任何视频数据训练,都能完美分割视频。数据集和设置上,SEEM在三种数据集接受了训练:全景分割,引用分割和交互式分割。交互式分割在交互式分割上,研究者将SEEM与最先进的交互式分割模型进行了比较。

作为一个通用模型,SEEM获得了RITM,SimpleClick等相当的性能。而且与SAM取得非常相似的性能,SAM还多用了50个分割数据进行训练。值得注意的是,与现有的交互式模型不同,SEEM是第一个不仅支持经典的分割任务,而且还支持广泛的多模态输入,包括文本、点、涂鸦、边界框和图像,提供了强大的组合能力。
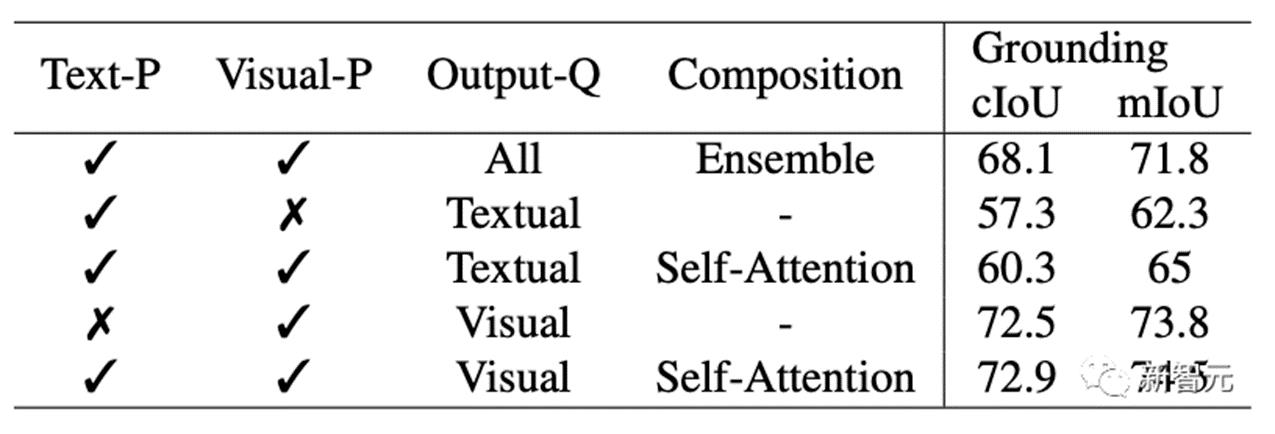

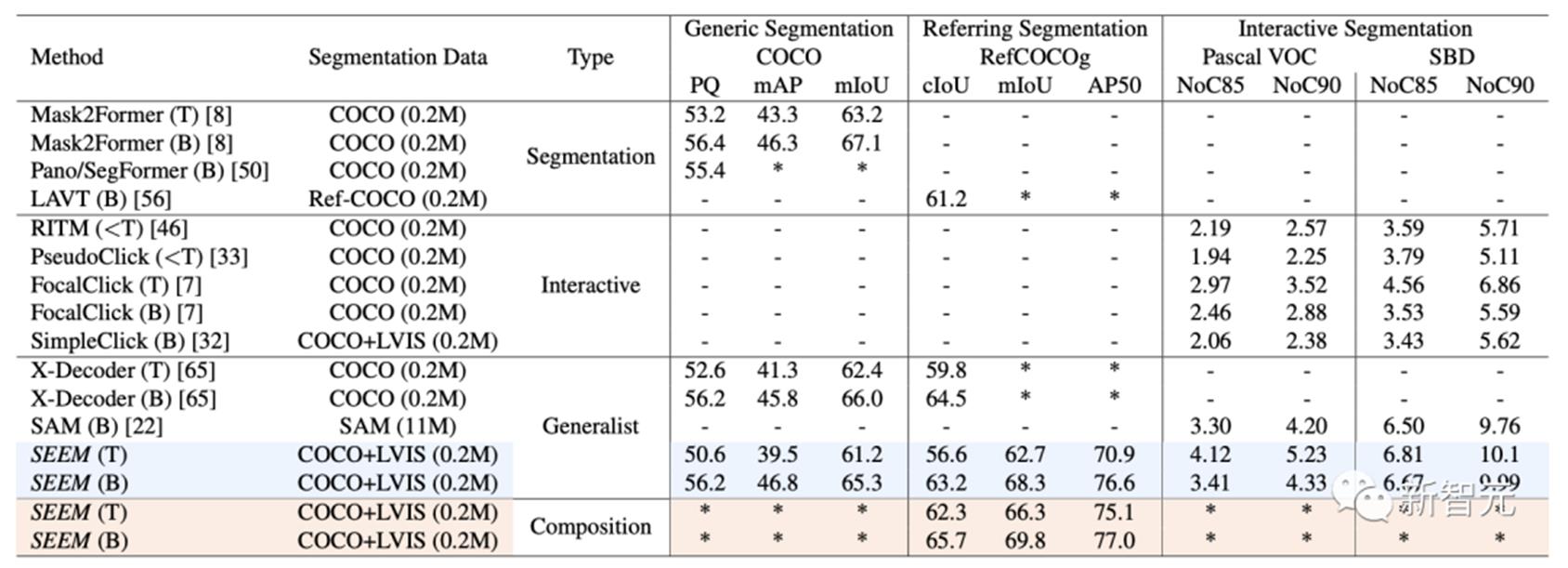
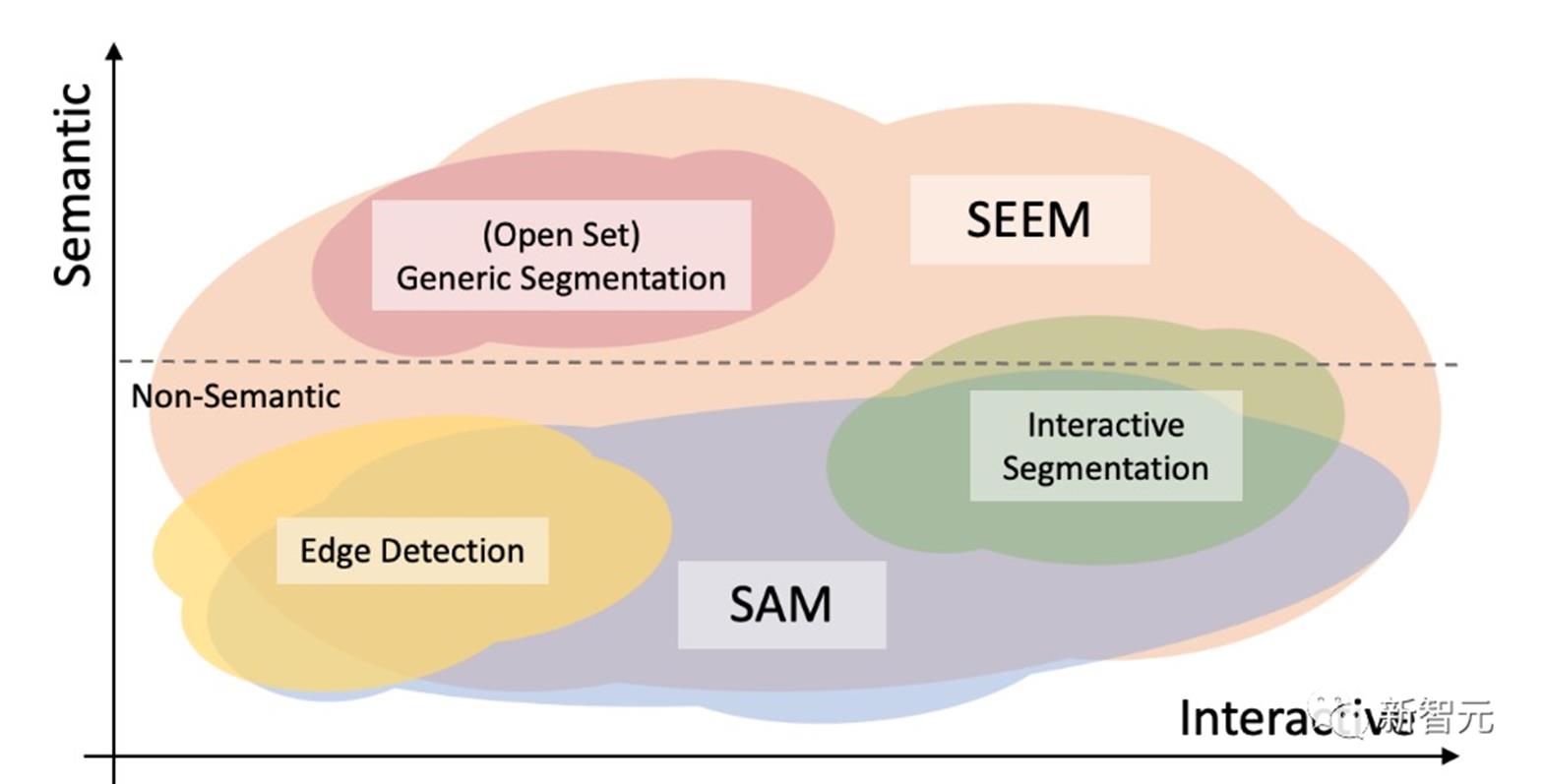
通用分割通过对所有分割任务预先训练的一组参数,研究者可以直接评估它在通用分割数据集上的性能。SEEM实现了比较好的全景视图,实例和语义分割性能。研究人员对SEEM有四个期望目标:1. 多功能性:通过引入多功能提示引擎处理不同类型的提示,包括点、框、涂鸦、遮罩、文本和另一图像的引用区域;2. 复合性:通过学习一个联合视觉-语义空间,为视觉和文本提示组合即时查询进行推理;3. 交互性:通过整合可学习的记忆提示,通过掩码引导的交叉注意力保留对话历史信息;4. 语义感知:通过使用文本编码器对文本查询和遮罩标签进行编码,实现开放词汇表的分割。和SAM区别Meta提出的SAM模型,可以在一个统一框架prompt encoder内,指定一个点、一个边界框、一句话,一键分割出物体。


SAM具有广泛的通用性,即具有了零样本迁移的能力,足以涵盖各种用例,不需要额外训练,就可以开箱即用地用于新的图像领域,无论是水下照片,还是细胞显微镜。研究者就三个分割任务(边缘检测、开放集和交互式分割)的交互和语义能力对SEEM和SAM进行了比较。在开放集分割上,同样需要高水平的语义,并且不需要交互。与SAM相比,SEEM涵盖了更广泛的交互和语义层次。SAM只支持有限的交互类型,比如点和边界框,而忽视了高语义任务,因为它本身不输出语义标签。对于SEEM,研究者点出了两个亮点:首先,SEEM有一个统一的提示编码器,将所有的视觉和语言提示编码到一个联合表示空间中。因此,SEEM可以支持更通用的用法,它有可能扩展到自定义提示。其次,SEEM在文本掩码和输出语义感知预测方面做得很好。
参考资料:
https://twitter.com/DrJimFan/status/1649835393163091969https://www.reddit.com/r/MachineLearning/comments/12lf2l3/r_seem_segment_everything_everywhere_all_at_once/https://t.co/U6so7iuxpv有点想离开谷歌了……
“这次是真的要离开狗家了...本来老板答应我今年可以升L6,但眼看又没戏了。不如跳出去寻找新的机会!”
Eric在狗家L5上已经待了3年。3月初,Google官宣今年将减少Senior Roles的晋升比例,Eric的晋升之梦也随之破裂。这更加坚定了他离开的决心。

2023年算法面试新预测的押题宝典
⭐ 23年最新算法面试考点预测:FANNG大厂押题宝典
⭐ 算法模版:刷题万用模板,理解解题思路
⭐仅展示部分,完整礼包拉至文末领取⭐
Googlers集体出逃,Start-ups成下一个财富自由风口
“不少老狗已经离开了...一个公司如果是到了连鸡毛蒜皮的福利都开始砍的时候,就是很明确的该跑路的信号了!”
但今年这情况,能接住Googlers的公司少之又少。一些Googler开始把目光投到Start-ups身上,寻求下一个财富自由的风口。

“有一个Meta E8 的朋友,他今年也离开了,跳槽到了一家做AI的start-up,据说股票给得不错。”
Googlers被刷率高于Amazoners/Facebookers?
有个在某独角兽公司的小伙伴透露,最近有不少大厂的程序员在面独角兽。而谷歌员工面试start-up被刷的概率,是远远高于亚麻脸书的。
有网友猜测,start-up更想要会吃苦的卷王!因为一般来说,startup都在抢占市场的攻坚阶段,会更倾向于能冲锋陷阵的人。而像谷歌这种大厂出来的人,比较讲究代码质量,行动较“迟缓”,而且对于perks福利待遇要求高,并不是很符合start-up的culture。

这也许是考虑的一个方面,另一方面也有start-up对于“面试资源浪费”的担忧。
某saas独角兽公司HR透露,来自于FAANG的申请者的offer接受率都比较低。因为这些大厂申请者,他们手中有的offer往往比较多,最后不一定会选择自己的公司,所以给offer前也会更“谨慎”一些,怕被“鸽”了。
Googlers在涌入的start-up,哪些能实现财富自由?
每一个来硅谷的人可能都有一个谷歌梦,每一个程序员都有一个财富自由的梦。曾经的Uber, Airbnb, 帮助不少程序员蹭到互联网的红利,实现财富自由。
如今,Googler们都在看哪些有机会实现财富自由的start-ups呢?
Moloco:新开两条业务线,砸大包挖人
AI核心数位广告公司Moloco最近正在招人,招的都是mid level及以上的岗位,平均薪资能达到$196k。
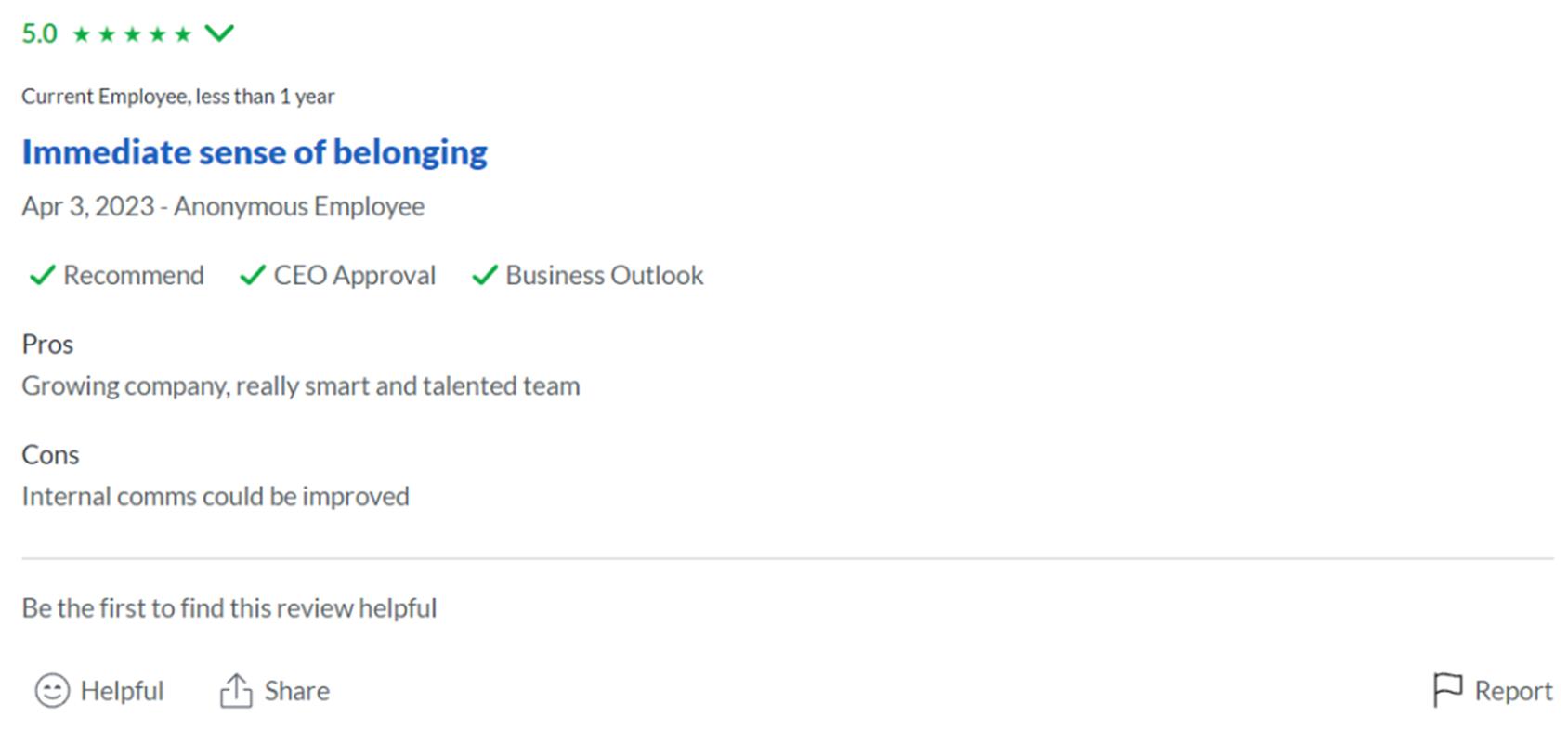
Moloco现有员工500-1000人,主营DSP业务,就算现在这种经济形势下也保持了高增长,还新开了两条业务线。目前,Moloco融资已经到了C轮,上次融资是2021年,有$150M估值,实现盈利已经有一段时间,目前现金充足。
员工们对公司文化很满意,工作自由度高,同事之间合作氛围好,在glassdoor上面许多人打出来5.0的高分。

现在公司处于高速增长期,后面想IPO,所以有很多功课要补,除了基础的招聘之外,也在花大价钱挖业内牛人,比如最近来的Tal Shaked。
MathWorks:一周工作几小时,稳如国企
MathWorks是一家开发技术性计算软件的公司,著名的产品有MATLAB和Simulink,客户遍布世界各大洲100多个国家,是一家低调且佛系的大厂!
MathWorks的早中晚饭都是免费的,WFH可以协商,WLB也很优秀,据内部人员透露,有些闲的组,一周只需工作几小时!
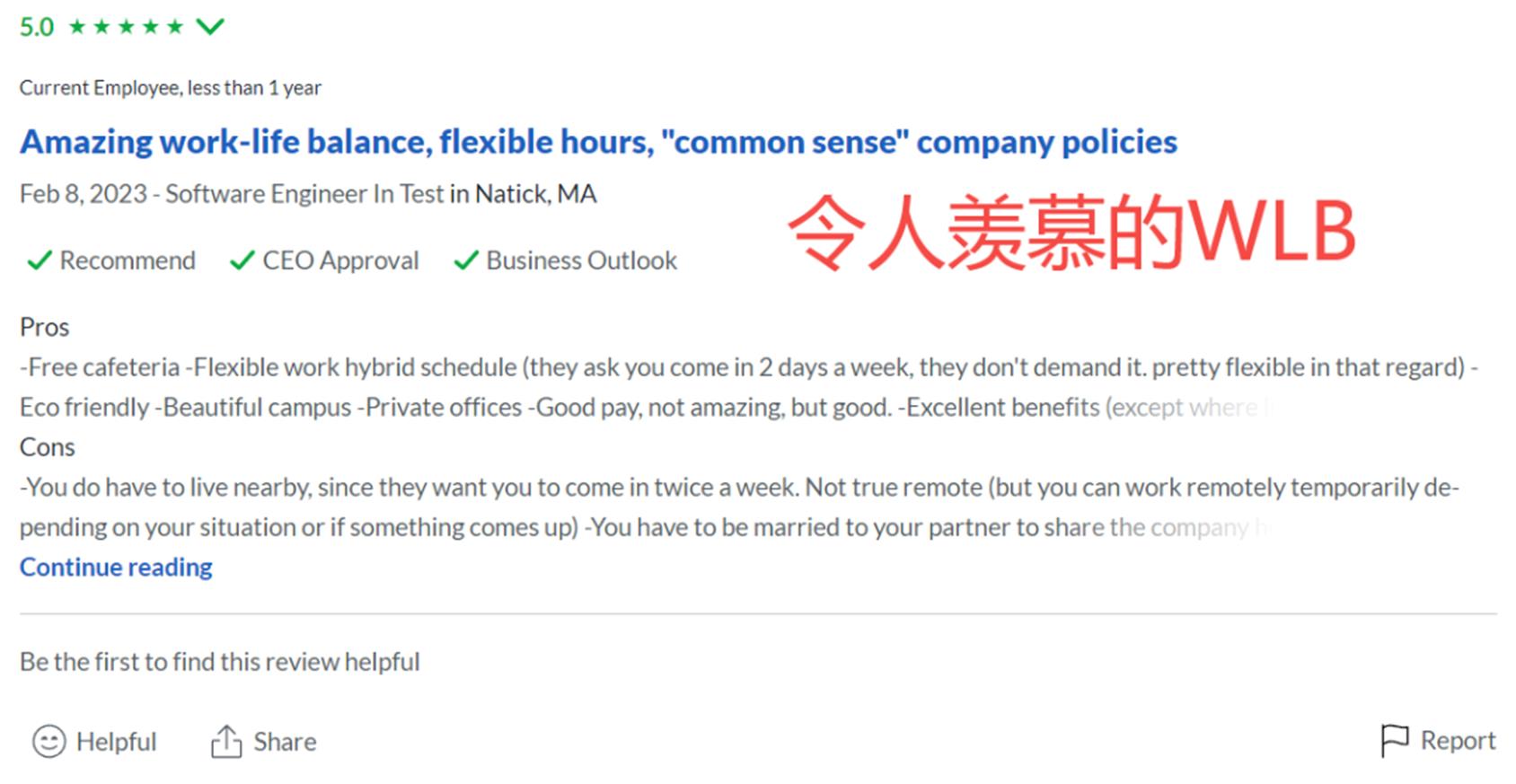
更贴心的是,MathWorks入职一年就可办H-1b,2-3年办绿卡,即使屡抽不中也问题不大,公司会先把人送到欧洲等地的分部再想方法捞回来,简直操碎了心。
MathWorks面试很爽快,没有冷冻期,面试回复和流程超快,HR鼓励一个职位挂了马上下一个!
据在MathWorks的朋友说,他们公司业务很稳,从去年11月至今都在猛招人!目前也放出了近百个技术岗位!跳槽的小伙伴一定要抓住机会!
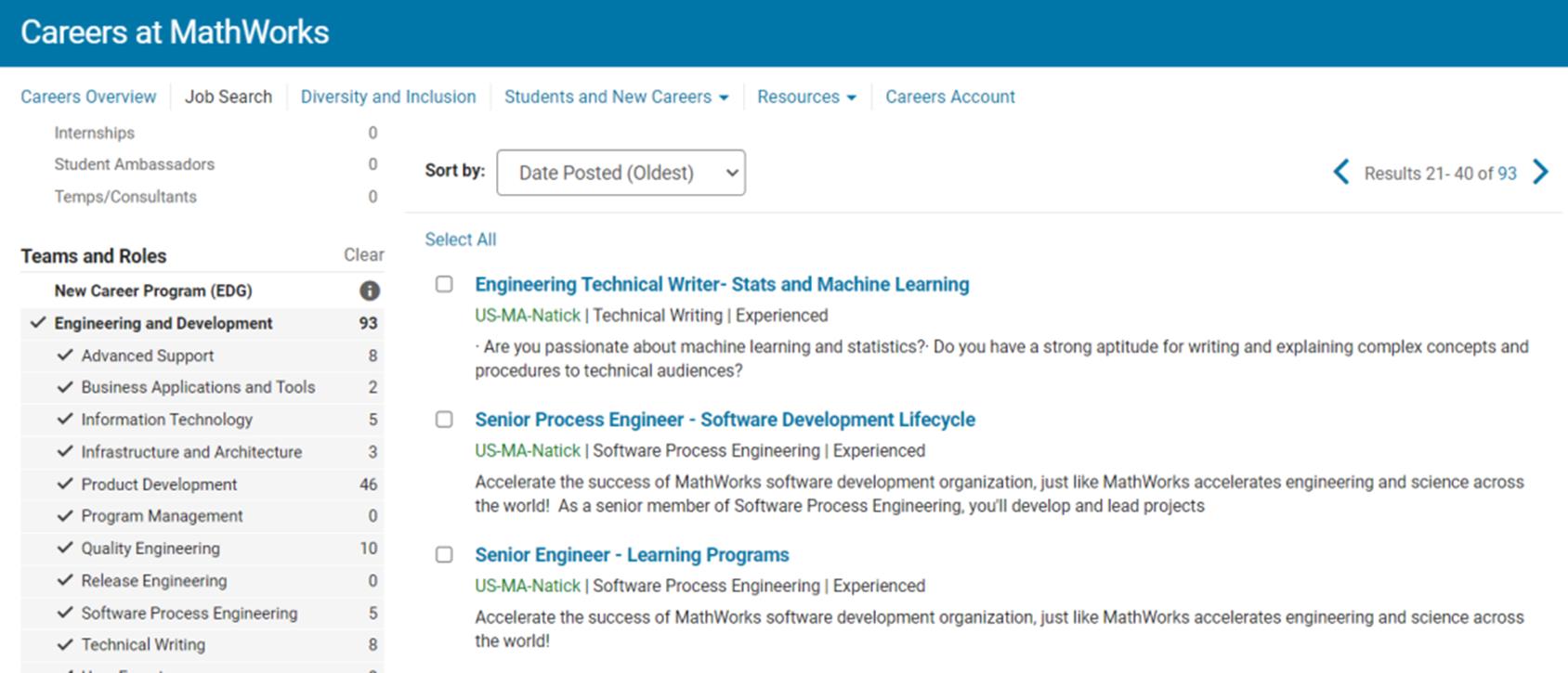
Applied Intuition:毕业就给$190K+,圆你“带薪旅游”
Applied Intuition总部位于Mountain View,主要做自动驾驶汽车研发仿真软件,致力于让工程和产品开发团队能够安全地大规模开发、测试和部署自动驾驶汽车。
Applied Intuition在21年的D轮融资中融到1.75亿美元,估值36亿美元,并且早在B轮融资就已经实现了盈利。
“钱多多”的Applied Intuition对待自己员工也很大方。NG的薪资能达到$190K+,而高级工程师给到$260K+也是常有的事。

Applied Intuition办公室文化清奇,倡导“无鞋文化”,大家都穿着舒适的拖鞋上班,工作氛围轻松友好。

Applied Intuition有一个“Global rotations”,在 Applied 工作一年或更长时间后,员工可以选择轮换到慕尼黑、斯德哥尔摩、东京和首尔的任何全球办事处,让员工有机会去了解不同的文化,获得宝贵的生活和工作经验。

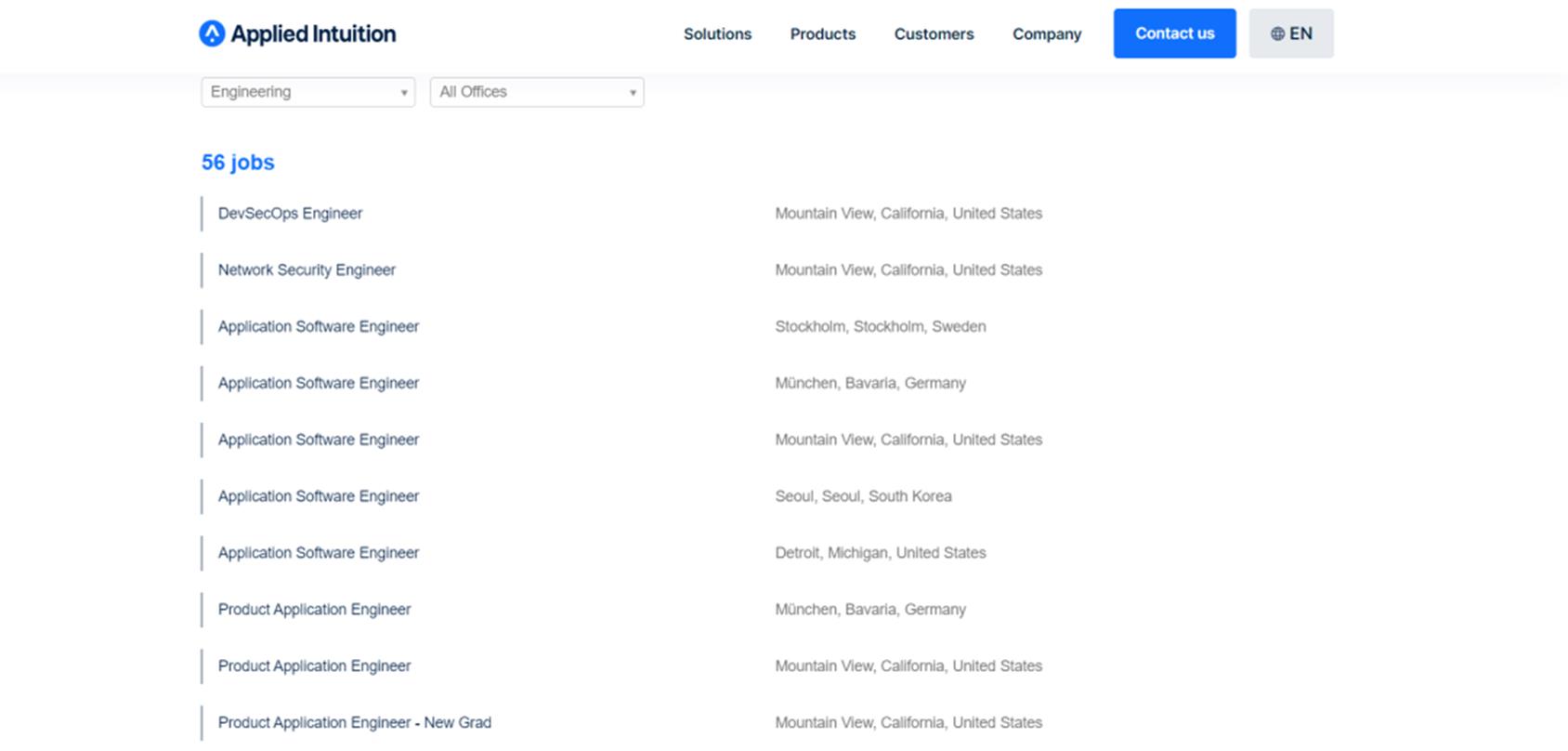
Applied Intuition在官网放出许多工程师岗位,想要体验“带薪旅游”的宝子,可冲!
Stripe:美版支付宝撒钱招人
Stripe主营数字支付处理服务,可以理解为“美版支付宝”。Stripe在2021年曾以950 亿美元的估值融资6亿美元,成为美国此前最有价值的初创公司之一。
今年1月,有消息人士曾透露,Stripe联席创始人Patrick 和John Collison 告诉员工,高管们设定的目标是在未来12个月内要么将公司上市,要么允许员工在私募市场交易中出售股份。
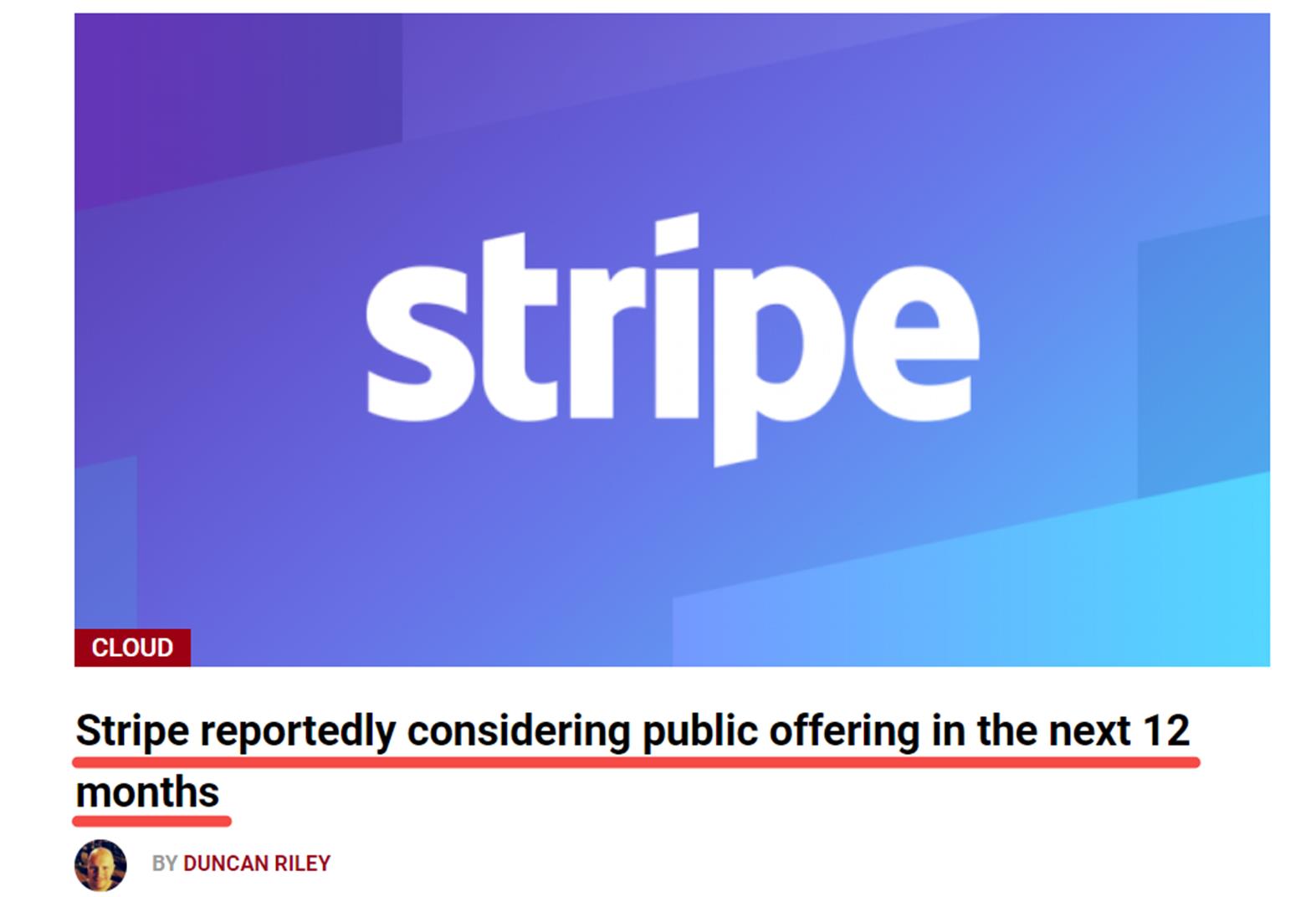
Stripe在招人上简直是壕无人性,以软件工程师为例,Stripe最初级的总包都有$246k。在2022年度技术薪资排行榜Entry-Level Engineer (l) 中,Stripe排名第二。
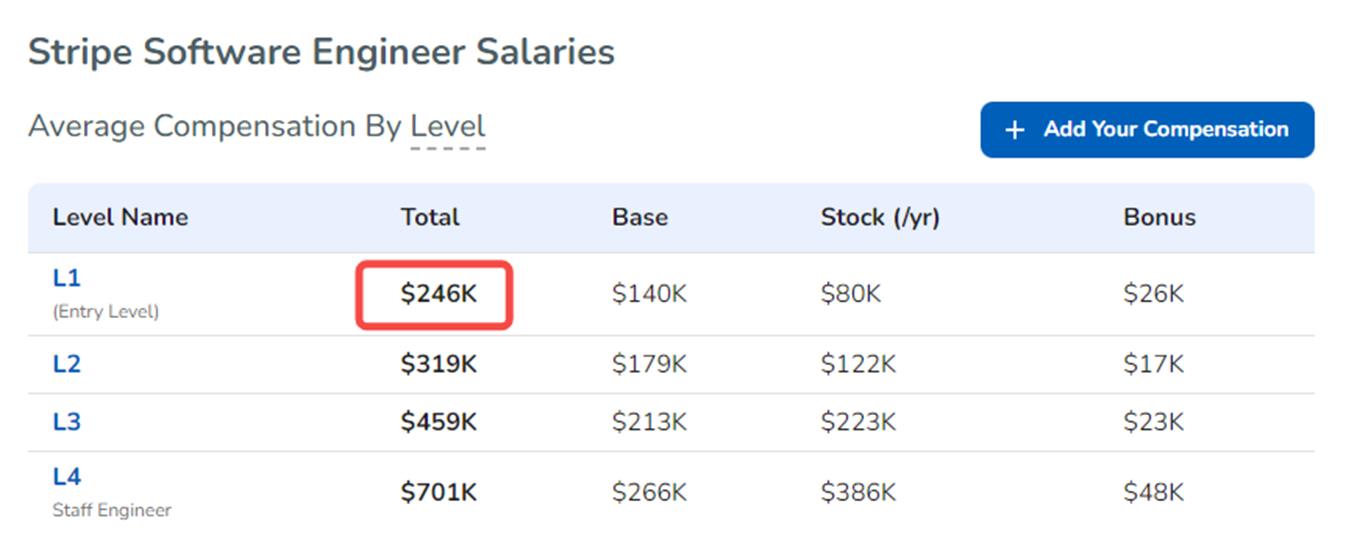
Stripe近期放出了一些岗位,虽然有“小亚麻”之称,WLB很糟糕,员工工作量大,节奏快。但是“有钱能使鬼推磨”,凭借其丰厚的待遇,它还是很多人心中的dream company。
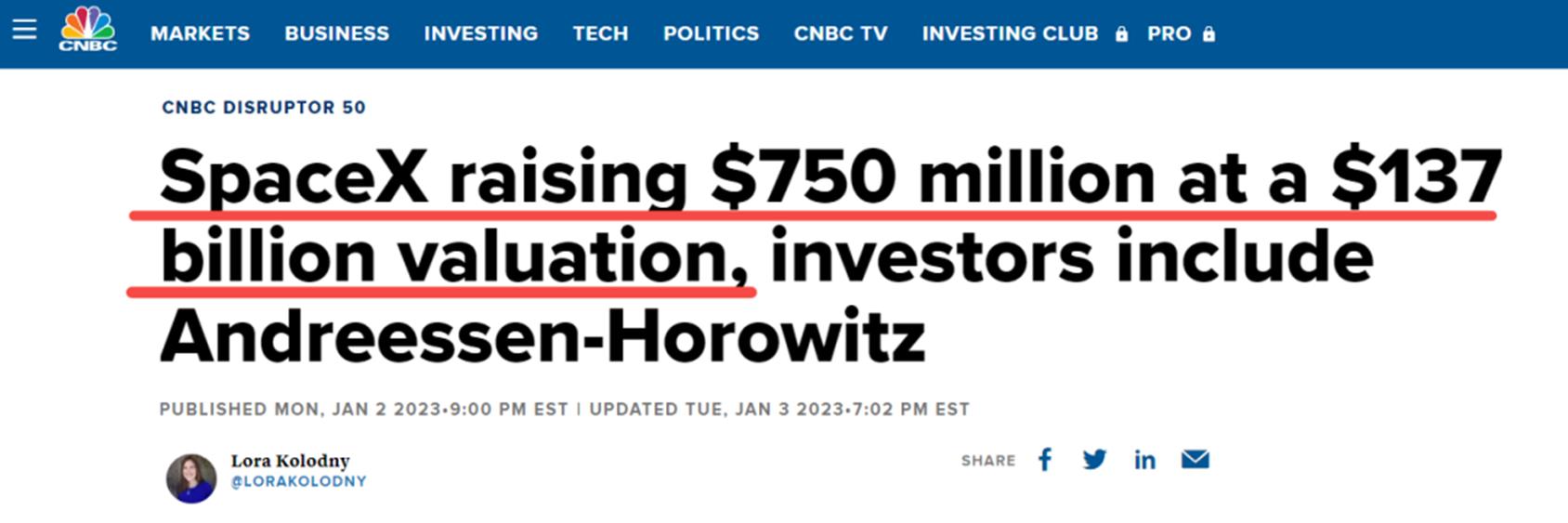
SpaceX:估值达$137B的超级独角兽,每周工作80小时
太空探索技术公司(SpaceX),是一家由PayPal早期投资人Elon Musk于2002年6月建立的美国太空运输公司。
今年1月初,SpaceX在新一轮融资中筹集了7.5亿美元,公司的估值达到了1370亿美元。
在SpaceX工作是什么样的体验,收到最多的反馈就是:太累了!每周工作70-80个小时,完全没有个人生活!不少员工们吐槽只有没有成家的年轻人以及野心勃勃的工作狂才是最适合在SpaceX工作的。
当然,如果能在SpaceX工作是“幸运”的,有了这段工作经历,想去其他类似的公司就是极其容易的了,大概这就是Big Brand的巨大优势吧。
参考文献链接
https://mp.weixin.qq.com/s/E9P28xCAR-8ZfFLuFzhLUQ
https://mp.weixin.qq.com/s/BrFZFYNZ9f5T5iR5fyg0IA
动手实践系列:CV语义分割!
Datawhale干货
作者:游璐颖,福州大学,Datawhale成员
图像分割是计算机视觉中除了分类和检测外的另一项基本任务,它意味着要将图片根据内容分割成不同的块。相比图像分类和检测,分割是一项更精细的工作,因为需要对每个像素点分类。
如下图的街景分割,由于对每个像素点都分类,物体的轮廓是精准勾勒的,而不是像检测那样给出边界框。

图像分割可以分为以下三个子领域:语义分割、实例分割、全景分割。

由对比图可发现,语义分割是从像素层次来识别图像,为图像中的每个像素制定类别标记,目前广泛应用于医学图像和无人驾驶等;实例分割相对更具有挑战性,不仅需要正确检测图像中的目标,同时还要精确的分割每个实例;全景分割综合了两个任务,要求图像中的每个像素点都必须被分配给一个语义标签和一个实例id。
01 语义分割中的关键步骤
在进行网络训练时,时常需要对语义标签图或是实例分割图进行预处理。如对于一张彩色的标签图,通过颜色映射表得到每种颜色所代表的类别,再将其转换成相应的掩膜或Onehot编码完成训练。这里将会对于其中的关键步骤进行讲解。
首先,以语义分割任务为例,介绍标签的不同表达形式。
1.1 语义标签图
语义分割数据集中包括原图和语义标签图,两者的尺寸大小相同,均为RGB图像。
在标签图像中,白色和黑色分别代表边框和背景,而其他不同颜色代表不同的类别:
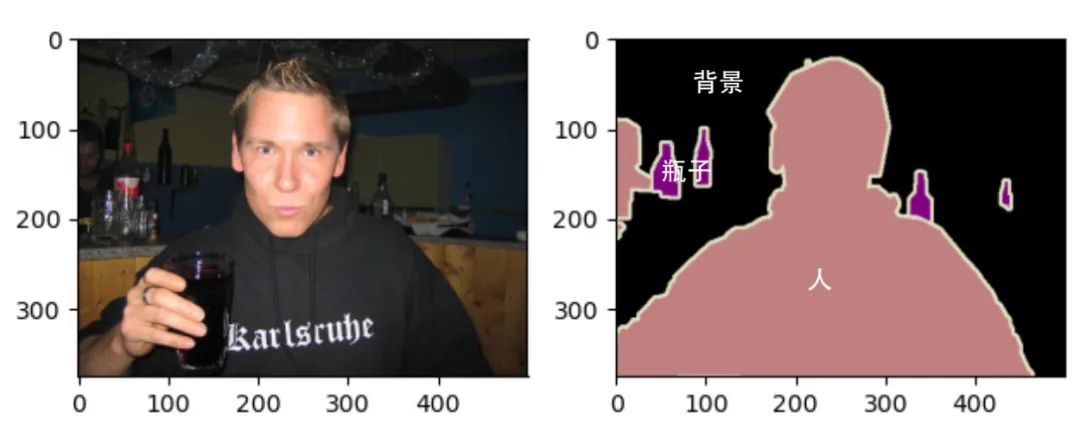
1.2 单通道掩膜
每个标签的RGB值与各自的标注类别对应,则可以很容易地查找标签中每个像素的类别索引,生成单通道掩膜Mask。
如下面这种图,标注类别包括:Person、Purse、Plants、Sidewalk、Building。将语义标签图转换为单通道掩膜后为右图所示,尺寸大小不变,但通道数由3变为1。
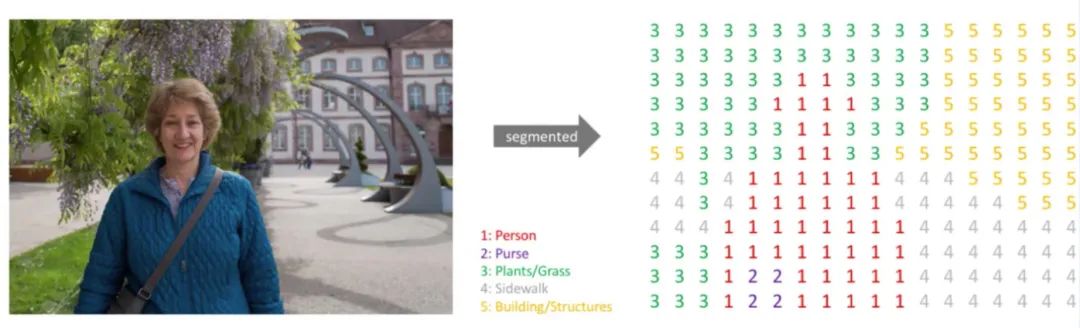
每个像素点位置一一对应。

1.3 Onehot编码
Onehot作为一种编码方式,可以对每一个单通道掩膜进行编码。
比如对于上述掩膜图Mask,图像尺寸为,标签类别共有5类,我们需要将这个Mask变为一个5个通道的Onehot输出,尺寸为,也就是将掩膜中值全为1的像素点抽取出生成一个图,相应位置置为1,其余为0。再将全为2的抽取出再生成一个图,相应位置置为1,其余为0,以此类推。
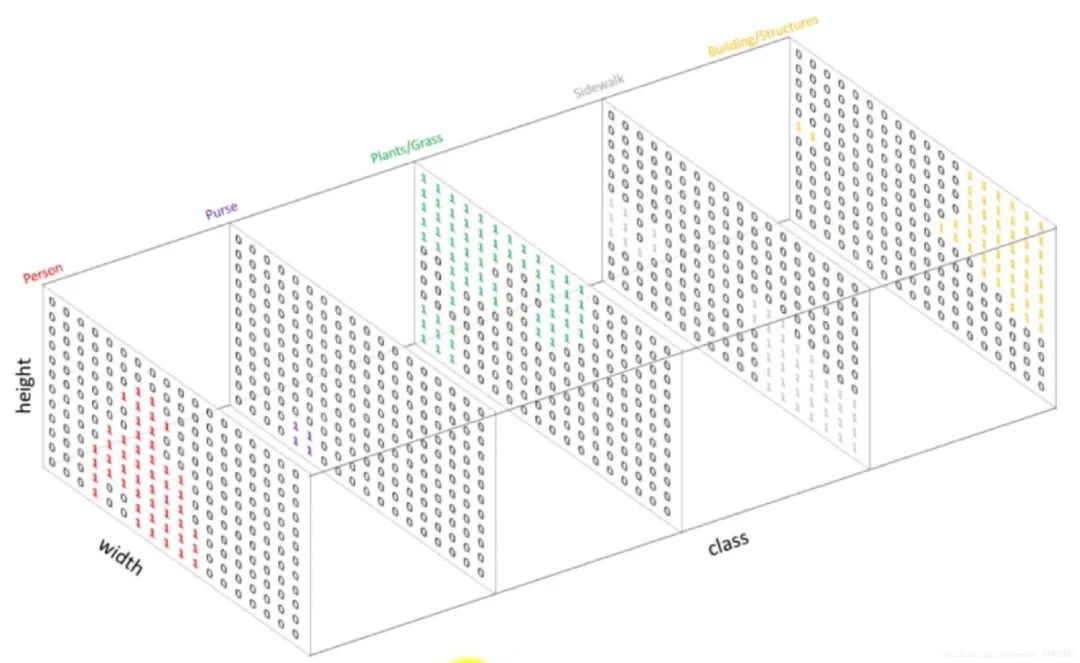
02 语义分割实践
接下来以Pascal VOC 2012语义分割数据集为例,介绍不同表达形式之间应该如何相互转换。
实践采用的是Pascal VOC 2012语义分割数据集,它是语义分割任务中十分重要的数据集,有 20 类目标,这些目标包括人类、机动车类以及其他类,可用于目标类别或背景的分割。
数据集开源地址:
https://gas.graviti.cn/dataset/yluy/VOC2012Segmentation
2.1 数据集读取
本次使用格物钛数据平台服务来完成数据集的在线读取,平台支持多种数据集类型,且提供了很多公开数据集便于使用。在使用之前先进行一些必要的准备工作:
Fork数据集:如果需要使用公开数据集,则需要将其先fork到自己的账户。
获取AccessKey:获取使用SDK与格物钛数据平台交互所需的密钥,链接为https://gas.graviti.cn/tensorbay/developer
理解Segment:数据集的进一步划分,如VOC数据集分成了“train”和“test”两个部分。
import os
from tensorbay import GAS
from tensorbay.dataset import Data, Dataset
from tensorbay.label import InstanceMask, SemanticMask
from PIL import Image
import numpy as np
import torchvision
import matplotlib.pyplot as plt
ACCESS_KEY = "<YOUR_ACCESSKEY>"
gas = GAS(ACCESS_KEY)
def read_voc_images(is_train=True, index=0):
"""
read voc image using tensorbay
"""
dataset = Dataset("VOC2012Segmentation", gas)
if is_train:
segment = dataset["train"]
else:
segment = dataset["test"]
data = segment[index]
feature = Image.open(data.open()).convert("RGB")
label = Image.open(data.label.semantic_mask.open()).convert("RGB")
visualize(feature, label)
return feature, label # PIL Image
def visualize(feature, label):
"""
visualize feature and label
"""
fig = plt.figure()
ax = fig.add_subplot(121) # 第一个子图
ax.imshow(feature)
ax2 = fig.add_subplot(122) # 第二个子图
ax2.imshow(label)
plt.show()
train_feature, train_label = read_voc_images(is_train=True, index=10)
train_label = np.array(train_label) # (375, 500, 3)
2.2 颜色映射表
在得到彩色语义标签图后,则可以构建一个颜色表映射,列出标签中每个RGB颜色的值及其标注的类别。
def colormap_voc():
"""
create a colormap
"""
colormap = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]]
classes = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person',
'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']
return colormap, classes2.3 Label与Onehot转换
根据映射表,实现语义标签图与Onehot编码的相互转换:
def label_to_onehot(label, colormap):
"""
Converts a segmentation label (H, W, C) to (H, W, K) where the last dim is a one
hot encoding vector, C is usually 1 or 3, and K is the number of class.
"""
semantic_map = []
for colour in colormap:
equality = np.equal(label, colour)
class_map = np.all(equality, axis=-1)
semantic_map.append(class_map)
semantic_map = np.stack(semantic_map, axis=-1).astype(np.float32)
return semantic_map
def onehot_to_label(semantic_map, colormap):
"""
Converts a mask (H, W, K) to (H, W, C)
"""
x = np.argmax(semantic_map, axis=-1)
colour_codes = np.array(colormap)
label = np.uint8(colour_codes[x.astype(np.uint8)])
return label
colormap, classes = colormap_voc()
semantic_map = mask_to_onehot(train_label, colormap)
print(semantic_map.shape) # [H, W, K] = [375, 500, 21] 包括背景共21个类别
label = onehot_to_label(semantic_map, colormap)
print(label.shape) # [H, W, K] = [375, 500, 3]2.4 Onehot与Mask转换
同样,借助映射表,实现单通道掩膜Mask与Onehot编码的相互转换:
def onehot2mask(semantic_map):
"""
Converts a mask (K, H, W) to (H,W)
"""
_mask = np.argmax(semantic_map, axis=0).astype(np.uint8)
return _mask
def mask2onehot(mask, num_classes):
"""
Converts a segmentation mask (H,W) to (K,H,W) where the last dim is a one
hot encoding vector
"""
semantic_map = [mask == i for i in range(num_classes)]
return np.array(semantic_map).astype(np.uint8)
mask = onehot2mask(semantic_map.transpose(2,0,1))
print(np.unique(mask)) # [ 0 1 15] 索引相对应的是背景、飞机、人
print(mask.shape) # (375, 500)
semantic_map = mask2onehot(mask, len(colormap))
print(semantic_map.shape) # (21, 375, 500)
游璐颖
福州大学,datawhale成员
个人博客:https://sonatau.github.io
点击阅读原文直接获取数据集
以上是关于CV语义分割到工作氛围杂谈的主要内容,如果未能解决你的问题,请参考以下文章
天池赛题解析:零基础入门语义分割-地表建筑物识别-CV语义分割实战(附部分代码)