Python Scrapy 验证码登录处理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python Scrapy 验证码登录处理相关的知识,希望对你有一定的参考价值。
一、Form表单分析
以豆瓣登录页面为例分析,豆瓣登录页是:https://accounts.douban.com/login,浏览器打开之后查看源码,查找登录的form表单HTML结构。如下:
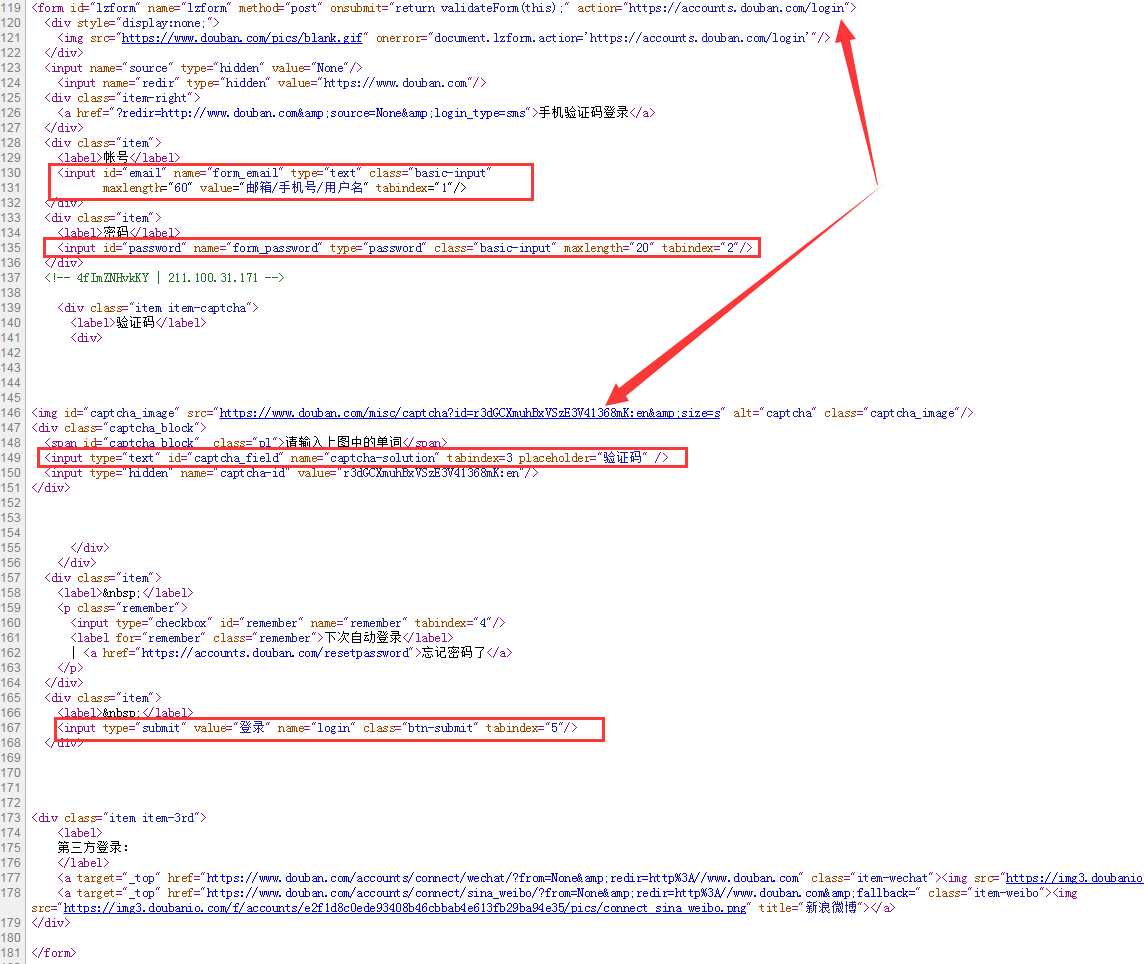
包括了form_email、form_password、captcha-solution四个表单参数,需要注意之处是name,而不是id。
二、验证码图片处理
1、分析验证码参数图片的构建如下图,获取id为captcha_image的src图片即可。可以采用人工输入,或第三方图片验证码识别API获得。

2、点击该url,图片是:

获取url之后,使用urllib.request.urlretrieve(url,filename="d:/captcha.jpg")下载图片
3、接下来通过python脚本获取该图片,保存在本地,在python命令行中采用input()方式,人工识别后输入该验证码:captcha_value = credit。
三、登录参数构建
通过预先注册的用户名、密码,获得验证码,构建表单参数如下:
data={
"form_email":"XXXXX",
"form_password":"******",
"captcha-solution":captcha_value,
}
四、Session参数存储
1、cookiejar学习:http://cuiqingcai.com/968.html
2、在request参数中指定cookiejar,如下:
首次访问目标网站:

构建登录参数后,开始登录。

五、登录后数据爬取
通过formdata认证通过后,在回调函数crawlerdata中处理爬取的网页,通过response对象进行数据解析。

六、主要代码
import scrapy
from scrapy.http import Request,FormRequest
import urllib.request
class DoubanSpider(scrapy.Spider):
name = "Douban"
allowed_domains = ["douban.com"]
UserAgent = {"User-Agent:":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2050.400 QQBrowser/9.5.10169.400"}
def start_requests(self):
return [Request("https://accounts.douban.com/login",callback=self.Login,meta={"cookiejar":1})]
def Login(self, response):
captcha = response.xpath("//img[@id=‘captcha_image‘]/@src").extract()
url = "https://accounts.douban.com/login"
print("正在保存验证码图片")
captchapicfile = "F:/20_Python/2000_PythonData/SelfStudy/douban/douban/captcha.png"
urllib.request.urlretrieve(captcha[0],filename = captchapicfile)
print("打开图片文件,查看验证码,输入单词......")
captcha_value = input()
data = {
"form_email":"XXXX",
"form_password":"XXXX",
"captcha-solution":captcha_value,
}
print("正在登陆中……")
return [FormRequest.from_response(response,
meta={"cookiejar":response.meta["cookiejar"]},
headers = self.UserAgent,
formdata = data,
callback=self.crawlerdata,
)]
def crawlerdata(self,response):
print("完成登录.........")
title = response.xpath("/html/head/title/text()").extract()
content2 = response.xpath("//meta[@name=‘description‘]/@content").extract()
print(title[0])
print(content2[0])
以上是关于Python Scrapy 验证码登录处理的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫scrapy框架——人工识别知乎登录知乎倒立文字验证码和数字英文验证码