Python Scrapy 自动爬虫注意细节
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python Scrapy 自动爬虫注意细节相关的知识,希望对你有一定的参考价值。
一、自动爬虫的创建,需要指定模版
如:
scrapy genspider -t crawl stockinfo quote.eastmoney.com
crawl : 爬虫模版
stockinfo :爬虫名称,后续敲命令执行爬虫需要输入的
quote.eastmoney.com :起始网址
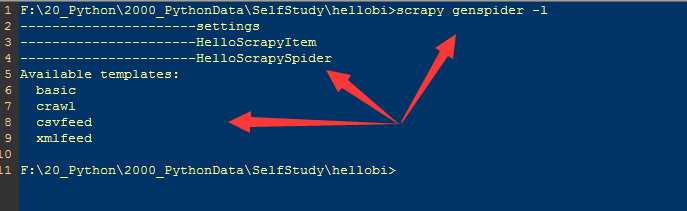
通过 scrapy genspider -l 查看可用模版
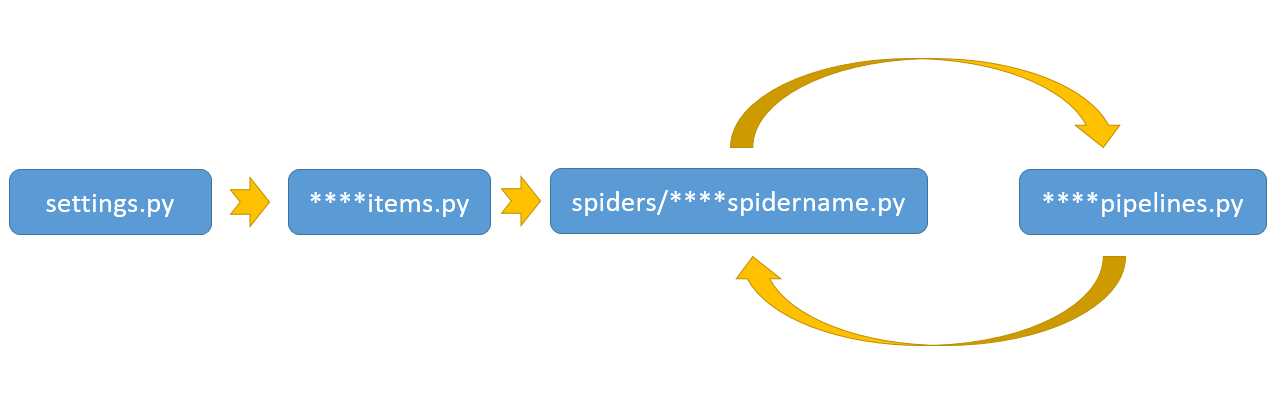
二、settings、items、pipeline、spider的执行顺序
settings--->items---->spider<---->pipeline,即第一次从settings读取爬虫配置,创建需要处理的数据项,根据starturl来启动爬虫,爬取到数据后,发送给管道处理数据(或放到文件中、或存到数据库)
三、页面过滤规则

这一步错误,很容易漏掉网址,通过在parse_item函数中输出response.url跟踪是否有遗漏的网页
如:print(response.url)
四、指定起始页
1、starts_urls数据
2、start_requests函数
以上是关于Python Scrapy 自动爬虫注意细节的主要内容,如果未能解决你的问题,请参考以下文章