Python分布式爬虫必学框架scrapy打造搜索引擎???
Posted look-789
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python分布式爬虫必学框架scrapy打造搜索引擎???相关的知识,希望对你有一定的参考价值。
Python分布式爬虫必学框架scrapy打造搜索引擎
Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能
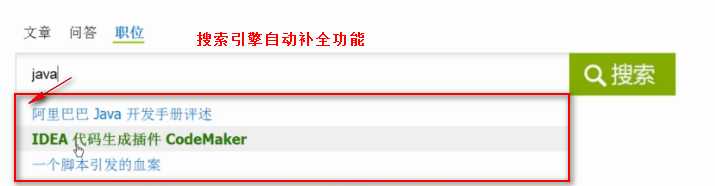
elasticsearch(搜索引擎)提供了自动补全接口
1、创建搜索自动补全字段suggest
自动补全需要用到一个字段名称为suggest类型为Completion类型的一个字段
所以我们需要用将前面的elasticsearch-dsl操作elasticsearch(搜索引擎)增加suggest类型为Completion
注意:因为elasticsearch-dsl源码问题,设置字段为Completion类型指定分词器时会报错,所以我们需要重写CustomAnalyzer类
只有Completion类型才是,其他类型不用,其他类型直接指定分词器即可
#!/usr/bin/env python
from datetime import datetime
from elasticsearch_dsl import DocType, Date, Nested, Boolean,
analyzer, InnerObjectWrapper, Completion, Keyword, Text, Integer
# 更多字段类型见第三百六十四节elasticsearch(搜索引擎)的mapping映射管理
from elasticsearch_dsl.analysis import CustomAnalyzer as _CustomAnalyzer #导入CustomAnalyzer类
from elasticsearch_dsl.connections import connections # 导入连接elasticsearch(搜索引擎)服务器方法
connections.create_connection(hosts=[‘127.0.0.1‘])
class CustomAnalyzer(_CustomAnalyzer): # 自定义CustomAnalyzer类,来重写CustomAnalyzer类
def get_analysis_definition(self):
return {}
ik_analyzer = CustomAnalyzer("ik_max_word", filter=["lowercase"]) # 实例化重写的CustomAnalyzer类传入分词器和大小写转,将大写转换成小写
class lagouType(DocType): # 自定义一个类来继承DocType类
suggest = Completion(analyzer=ik_analyzer)
# Text类型需要分词,所以需要知道中文分词器,ik_max_wordwei为中文分词器
title = Text(analyzer="ik_max_word") # 设置,字段名称=字段类型,Text为字符串类型并且可以分词建立倒排索引
description = Text(analyzer="ik_max_word")
keywords = Text(analyzer="ik_max_word")
url = Keyword() # 设置,字段名称=字段类型,Keyword为普通字符串类型,不分词
riqi = Date() # 设置,字段名称=字段类型,Date日期类型
class Meta: # Meta是固定写法
index = "lagou" # 设置索引名称(相当于数据库名称)
doc_type = ‘biao‘ # 设置表名称
if __name__ == "__main__": # 判断在本代码文件执行才执行里面的方法,其他页面调用的则不执行里面的方法
lagouType.init() # 生成elasticsearch(搜索引擎)的索引,表,字段等信息
# 使用方法说明:
# 在要要操作elasticsearch(搜索引擎)的页面,导入此模块
# lagou = lagouType() #实例化类
# lagou.title = ‘值‘ #要写入字段=值
# lagou.description = ‘值‘
# lagou.keywords = ‘值‘
# lagou.url = ‘值‘
# lagou.riqi = ‘值‘
# lagou.save() #将数据写入elasticsearch(搜索引擎)
2、搜索自动补全字段suggest写入数据
搜索自动补全字段suggest接收的要搜索的字段分词数据,详情见下面的自定义分词函数
elasticsearch-dsl操作elasticsearch(搜索引擎)
#!/usr/bin/env python
# -*- coding:utf8 -*-
#!/usr/bin/env python
from datetime import datetime
from elasticsearch_dsl import DocType, Date, Nested, Boolean,
analyzer, InnerObjectWrapper, Completion, Keyword, Text, Integer
from elasticsearch_dsl.connections import connections # 导入连接elasticsearch(搜索引擎)服务器方法
# 更多字段类型见第三百六十四节elasticsearch(搜索引擎)的mapping映射管理
from elasticsearch_dsl.analysis import CustomAnalyzer as _CustomAnalyzer #导入CustomAnalyzer类
connections.create_connection(hosts=[‘127.0.0.1‘])
class CustomAnalyzer(_CustomAnalyzer): # 自定义CustomAnalyzer类,来重写CustomAnalyzer类
def get_analysis_definition(self):
return {}
ik_analyzer = CustomAnalyzer("ik_max_word", filter=["lowercase"]) # 实例化重写的CustomAnalyzer类传入分词器和大小写转,将大写转换成小写
class lagouType(DocType): # 自定义一个类来继承DocType类
suggest = Completion(analyzer=ik_analyzer)
# Text类型需要分词,所以需要知道中文分词器,ik_max_wordwei为中文分词器
title = Text(analyzer="ik_max_word") # 设置,字段名称=字段类型,Text为字符串类型并且可以分词建立倒排索引
description = Text(analyzer="ik_max_word")
keywords = Text(analyzer="ik_max_word")
url = Keyword() # 设置,字段名称=字段类型,Keyword为普通字符串类型,不分词
riqi = Date() # 设置,字段名称=字段类型,Date日期类型
class Meta: # Meta是固定写法
index = "lagou" # 设置索引名称(相当于数据库名称)
doc_type = ‘biao‘ # 设置表名称
def gen_suggest(index, info_tuple):
# 根据字符串生成搜索建议数组
"""
此函数主要用于,连接elasticsearch(搜索引擎),使用ik_max_word分词器,将传入的字符串进行分词,返回分词后的结果
此函数需要两个参数:
第一个参数:要调用elasticsearch(搜索引擎)分词的索引index,一般是(索引操作类._doc_type.index)
第二个参数:是一个元组,元祖的元素也是元组,元素元祖里有两个值一个是要分词的字符串,第二个是分词的权重,多个分词传多个元祖如下
书写格式:
gen_suggest(lagouType._doc_type.index, ((‘字符串‘, 10),(‘字符串‘, 8)))
"""
es = connections.create_connection(lagouType._doc_type.using) # 连接elasticsearch(搜索引擎),使用操作搜索引擎的类下面的_doc_type.using连接
used_words = set()
suggests = []
for text, weight in info_tuple:
if text:
# 调用es的analyze接口分析字符串,
words = es.indices.analyze(index=index, analyzer="ik_max_word", params={‘filter‘:["lowercase"]}, body=text)
anylyzed_words = set([r["token"] for r in words["tokens"] if len(r["token"])>1])
new_words = anylyzed_words - used_words
else:
new_words = set()
if new_words:
suggests.append({"input":list(new_words), "weight":weight})
# 返回分词后的列表,里面是字典,
# 如:[{‘input‘: [‘录音‘, ‘广告‘], ‘weight‘: 10}, {‘input‘: [‘新能源‘, ‘汽车‘,], ‘weight‘: 8}]
return suggests
if __name__ == "__main__": # 判断在本代码文件执行才执行里面的方法,其他页面调用的则不执行里面的方法
lagouType.init() # 生成elasticsearch(搜索引擎)的索引,表,字段等信息
# 使用方法说明:
# 在要要操作elasticsearch(搜索引擎)的页面,导入此模块
# lagou = lagouType() #实例化类
# lagou.title = ‘值‘ #要写入字段=值
# lagou.description = ‘值‘
# lagou.keywords = ‘值‘
# lagou.url = ‘值‘
# lagou.riqi = ‘值‘
# lagou.save() #将数据写入elasticsearch(搜索引擎)
suggest字段写入数据
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
# items.py,文件是专门用于,接收爬虫获取到的数据信息的,就相当于是容器文件
import scrapy
from scrapy.loader.processors import MapCompose, TakeFirst
from scrapy.loader import ItemLoader # 导入ItemLoader类也就加载items容器类填充数据
from adc.models.elasticsearch_orm import lagouType, gen_suggest # 导入elasticsearch操作模块
class LagouItemLoader(ItemLoader): # 自定义Loader继承ItemLoader类,在爬虫页面调用这个类填充数据到Item类
default_output_processor = TakeFirst() # 默认利用ItemLoader类,加载items容器类填充数据,是列表类型,可以通过TakeFirst()方法,获取到列表里的内容
def tianjia(value): # 自定义数据预处理函数
return value # 将处理后的数据返给Item
class LagouItem(scrapy.Item): # 设置爬虫获取到的信息容器类
title = scrapy.Field( # 接收爬虫获取到的title信息
input_processor=MapCompose(tianjia), # 将数据预处理函数名称传入MapCompose方法里处理,数据预处理函数的形式参数value会自动接收字段title
)
description = scrapy.Field()
keywords = scrapy.Field()
url = scrapy.Field()
riqi = scrapy.Field()
def save_to_es(self):
lagou = lagouType() # 实例化elasticsearch(搜索引擎对象)
lagou.title = self[‘title‘] # 字段名称=值
lagou.description = self[‘description‘]
lagou.keywords = self[‘keywords‘]
lagou.url = self[‘url‘]
lagou.riqi = self[‘riqi‘]
# 将title和keywords数据传入分词函数,进行分词组合后返回写入搜索建议字段suggest
lagou.suggest = gen_suggest(lagouType._doc_type.index, ((lagou.title, 10),(lagou.keywords, 8)))
lagou.save() # 将数据写入elasticsearch(搜索引擎对象)
return
写入elasticsearch(搜索引擎)后的情况
{
"_index": "lagou",
"_type": "biao",
"_id": "AV5MDu0NXJs9MkF5tFxW",
"_version": 1,
"_score": 1,
"_source": {
"title": "LED光催化灭蚊灯广告录音_广告录音网-火红广告录音_叫卖录音下载_语音广告制作",
"keywords": "各类小商品,广告录音,叫卖录音,火红广告录音",
"url": "http://www.luyin.org/post/2486.html",
"suggest": [
{
"input": [
"广告"
,
"火红"
,
"制作"
,
"叫卖"
,
"灭蚊灯"
,
"语音"
,
"下载"
,
"led"
,
"录音"
,
"灭蚊"
,
"光催化"
,
"催化"
],
"weight": 10
}
,
{
"input": [
"小商品"
,
"广告"
,
"各类"
,
"火红"
,
"叫卖"
,
"商品"
,
"小商"
,
"录音"
],
"weight": 8
}
],
"riqi": "2017-09-04T16:43:20",
"description": "LED光催化灭蚊灯广告录音 是广告录音网-火红广告录音中一篇关于 各类小商品 的文章,欢迎您阅读和评论,专业叫卖录音-广告录音-语音广告制作"
}
}
用Django实现搜索的自动补全功能说明
1.将搜索框绑定一个事件,每输入一个字触发这个事件,获取到输入框里的内容,用ajax将输入的词请求到Django的逻辑处理函数。
2.在逻辑处理函数里,将请求词用elasticsearch(搜索引擎)的fuzzy模糊查询,查询suggest字段里存在请求词的数据,将查询到的数据添加到自动补全
html代码:
<!DOCTYPE html >
<html xmlns="http://www.w3.org/1999/xhtml">
{#引入静态文件路径#}
{% load staticfiles %}
<head>
<meta http-equiv="X-UA-Compatible" content="IE=emulateIE7" />
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>lcv-search 搜索引擎</title>
<link href="{% static ‘css/style.css‘%}" rel="stylesheet" type="text/css" />
<link href="{% static ‘css/index.css‘%}" rel="stylesheet" type="text/css" />
</head>
<body>
<div id="container">
<div id="bd">
<div id="main">
<h1 class="title">
<div class="logo large"></div>
</h1>
<div class="nav ue-clear">
<ul class="searchList">
<li class="searchItem current" data-type="article">文章</li>
<li class="searchItem" data-type="question">问答</li>
<li class="searchItem" data-type="job">职位</li>
</ul>
</div>
<div class="inputArea">
{% csrf_token %}
<input type="text" class="searchInput" />
<input type="button" class="searchButton" onclick="add_search()" />
<ul class="dataList">
<li>如何学好设计</li>
<li>界面设计</li>
<li>UI设计培训要多少钱</li>
<li>设计师学习</li>
<li>哪里有好的网站</li>
</ul>
</div>
<div class="historyArea">
<p class="history">
<label>热门搜索:</label>
</p>
<p class="history mysearch">
<label>我的搜索:</label>
<span class="all-search">
<a href="javascript:;">专注界面设计网站</a>
<a href="javascript:;">用户体验</a>
<a href="javascript:;">互联网</a>
<a href="javascript:;">资费套餐</a>
</span>
</p>
</div>
</div><!-- End of main -->
</div><!--End of bd-->
<div class="foot">
<div class="wrap">
<div class="copyright">Copyright ©uimaker.com 版权所有 E-mail:admin@uimaker.com</div>
</div>
</div>
</div>
</body>
<script type="text/javascript" src="{% static ‘js/jquery.js‘%}"></script>
<script type="text/javascript" src="{% static ‘js/global.js‘%}"></script>
<script type="text/javascript">
var suggest_url = "/suggest/"
var search_url = "/search/"
$(‘.searchList‘).on(‘click‘, ‘.searchItem‘, function(){
$(‘.searchList .searchItem‘).removeClass(‘current‘);
$(this).addClass(‘current‘);
});
function removeByValue(arr, val) {
for(var i=0; i<arr.length; i++) {
if(arr[i] == val) {
arr.splice(i, 1);
break;
}
}
}
// 搜索建议
$(function(){
$(‘.searchInput‘).bind(‘ input propertychange ‘,function(){
var searchText = $(this).val();
var tmpHtml = ""
$.ajax({
cache: false,
type: ‘get‘,
dataType:‘json‘,
url:suggest_url+"?s="+searchText+"&s_type="+$(".searchItem.current").attr(‘data-type‘),
async: true,
success: function(data) {
for (var i=0;i<data.length;i++){
tmpHtml += ‘<li><a href="‘+search_url+‘?q=‘+data[i]+‘">‘+data[i]+‘</a></li>‘
}
$(".dataList").html("")
$(".dataList").append(tmpHtml);
if (data.length == 0){
$(‘.dataList‘).hide()
}else {
$(‘.dataList‘).show()
}
}
});
} );
})
hideElement($(‘.dataList‘), $(‘.searchInput‘));
</script>
<script>
var searchArr;
//定义一个search的,判断浏览器有无数据存储(搜索历史)
if(localStorage.search){
//如果有,转换成 数组的形式存放到searchArr的数组里(localStorage以字符串的形式存储,所以要把它转换成数组的形式)
searchArr= localStorage.search.split(",")
}else{
//如果没有,则定义searchArr为一个空的数组
searchArr = [];
}
//把存储的数据显示出来作为搜索历史
MapSearchArr();
function add_search(){
var val = $(".searchInput").val();
if (val.length>=2){
//点击搜索按钮时,去重
KillRepeat(val);
//去重后把数组存储到浏览器localStorage
localStorage.search = searchArr;
//然后再把搜索内容显示出来
MapSearchArr();
}
window.location.href=search_url+‘?q=‘+val+"&s_type="+$(".searchItem.current").attr(‘data-type‘)
}
function MapSearchArr(){
var tmpHtml = "";
var arrLen = 0
if (searchArr.length >= 5){
arrLen = 5
}else {
arrLen = searchArr.length
}
for (var i=0;i<arrLen;i++){
tmpHtml += ‘<a href="‘+search_url+‘?q=‘+searchArr[i]+‘">‘+searchArr[i]+‘</a>‘
}
$(".mysearch .all-search").html(tmpHtml);
}
//去重
function KillRepeat(val){
var kill = 0;
for (var i=0;i<searchArr.length;i++){
if(val===searchArr[i]){
kill ++;
}
}
if(kill<1){
searchArr.unshift(val);
}else {
removeByValue(searchArr, val)
searchArr.unshift(val)
}
}
</script>
</html>
Django路由映射
"""pachong URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/1.10/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: url(r‘^$‘, views.home, name=‘home‘)
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: url(r‘^$‘, Home.as_view(), name=‘home‘)
Including another URLconf
1. Import the include() function: from django.conf.urls import url, include
2. Add a URL to urlpatterns: url(r‘^blog/‘, include(‘blog.urls‘))
"""
from django.conf.urls import url
from django.contrib import admin
from app1 import views
urlpatterns = [
url(r‘^admin/‘, admin.site.urls),
url(r‘^$‘, views.indexluoji),
url(r‘^index/‘, views.indexluoji),
url(r‘^suggest/$‘, views.suggestluoji,name="suggest"), # 搜索字段补全请求
]
Django静态文件配置
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/1.10/howto/static-files/
#配置静态文件前缀
STATIC_URL = ‘/static/‘
#配置静态文件目录
STATICFILES_DIRS = [
os.path.join(BASE_DIR, ‘static‘)
]
备注:搜索自动补全fuzzy查询
#搜索自动补全fuzzy查询
POST lagou/biao/_search?pretty
{
"suggest":{ #字段名称
"my_suggest":{ #自定义变量
"text":"广告", #搜索词
"completion":{
"field":"suggest", #搜索字段
"fuzzy":{
"fuzziness":1 #编辑距离
}
}
}
},
"_source":"title"
}
Django逻辑处理文件
from django.shortcuts import render
# Create your views here.
from django.shortcuts import render,HttpResponse
from django.views.generic.base import View
from app1.models import lagouType #导入操作elasticsearch(搜索引擎)类
import json
def indexluoji(request):
print(request.method) # 获取用户请求的路径
return render(request, ‘index.html‘)
def suggestluoji(request): # 搜索自动补全逻辑处理
key_words = request.GET.get(‘s‘, ‘‘) # 获取到请求词
re_datas = []
if key_words:
s = lagouType.search() # 实例化elasticsearch(搜索引擎)类的search查询
s = s.suggest(‘my_suggest‘, key_words, completion={
"field": "suggest", "fuzzy": {
"fuzziness": 2
},
"size": 5
})
suggestions = s.execute_suggest()
for match in suggestions.my_suggest[0].options:
source = match._source
re_datas.append(source["title"])
return HttpResponse(json.dumps(re_datas), content_type="application/json")
以上是关于Python分布式爬虫必学框架scrapy打造搜索引擎???的主要内容,如果未能解决你的问题,请参考以下文章
Python分布式爬虫必学框架Scrapy打造搜索引擎 学习教程
CK21144-Python分布式爬虫必学框架Scrapy打造搜索引擎
Python分布式爬虫必学框架Scrapy打造搜索引擎 学习教程