如何进行SQL性能优化
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何进行SQL性能优化相关的知识,希望对你有一定的参考价值。
进行SQL性能优化的方法:
1、SQL语句不要写的太复杂。一个SQL语句要尽量简单,不要嵌套太多层。
2、使用『临时表』缓存中间结果。简化SQL语句的重要方法就是采用临时表暂存中间结果,这样可以避免程序中多次扫描主表,也大大减少了阻塞,提高了并发性能。
3、使用like的时候要注意是否会导致全表扫,有的时候会需要进行一些模糊查询例如:select id from table where username like ‘%hollis%’关键词%hollis%,由于hollis前面用到了“%”,因此该查询会使用全表扫描,除非必要,否则不要在关键词前加%。
4、尽量避免使用!=或<>操作符。在where语句中使用!=或<>,引擎将放弃使用索引而进行全表扫描。
5、尽量避免使用 or 来连接条件;在 where 子句中使用 or 来连接条件,引擎将放弃使用索引而进行全表扫描。可以使用
select id from t where num=10
union all
select id from t where num=20
替代
select id from t where num=10 or num=20
6、尽量避免使用in和not in:在 where 子句中使用 in和not in,引擎将放弃使用索引而进行全表扫描。可以使用
select id from t where num between 10 and 20
替代
select id from t where num in (10,20)
7、可以考虑强制查询使用索引
select * from table force index(PRI) limit 2;(强制使用主键)
select * from table force index(hollis_index) limit 2;(强制使用索引"hollis_index")
select * from table force index(PRI,hollis_index) limit 2;(强制使用索引"PRI和hollis_index")
8、尽量避免使用表达式、函数等操作作为查询条件;尽量避免大事务操作,提高系统并发能力。尽量避免使用游标;任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
9、尽可能的使用 varchar/nvarchar 代替 char/nchar。尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
10、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率、并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引。
参考技术A1、模糊查询like。
使用like进行模糊查询时应该特别注意,这个很基本,基本上大家都知道。
select * from contact where username like ‘%yue%’
关键词%yue%,由于yue前面用到了“%”,因此该查询必然走全表扫描,除非必要,否则不要在关键词前加%。
2、where条件查询
尽量避免使用in,not in,having,可以使用 exist 和not exist代替 in和not in。不要以字符格式声明数字,要以数字格式声明字符值。
3、前面提到的from子句中有多个表进行关联查询时
在from子句中包含多个表的情况下,选择记录条数最少的表作为基础表,在某种程度上将会极大的提高其性能。如果有3个以上的表,则选择交叉表作为基础表
4、select *查询
尽量不要使用
select * from tablename
取而代之的则是:
select columnname1,columnname2 from tablename
5、排序操作
避免使用耗费资源的操作,带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎 执行,耗费资源的排序(SORT)功能. DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序。
6、索引表操作
对于此处,个人还没有弄明白,首先对于索引还不明白,那么性能优化更谈不上了。反正很多大牛都是操作索引表,需要特别注意。以后明白了再补充吧。
...
7、LEFT JOIN 和 inner join的区别,是否真的需要left join,否则选用inner join 来减少不必要的数据返回。
个人因为编程习惯问题,总喜欢写left join,看来以后要用大脑思考思考了。
同时,SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
8、统一规范sql语句
编写规范的sql语句,这一点是最重要的一点,不管对于系统还是个人来说,都是相当的重要。

扩展资料:
使用like进行模糊查询时应该特别注意
select * from contact where username like ‘%yue%’
关键词%yue%,由于yue前面用到了“%”,因此该查询必然走全表扫描,除非必要,否则不要在关键词前加%。
尽量避免使用in,not in,having,可以使用 exist 和not exist代替 in和not in。不要以字符格式声明数字,要以数字格式声明字符值。
索引
加索引,本地模拟现场的业务场景,插入了大量的测试数据,在sql的where条件查询字段下加了索引,查询时间进入到秒级,完全满足项目要求。现场提供的视图,而且视图的厂家没有人维护了,不可能创建其它东西的,所以虽然索引有效但是无法使用。
参数
现场系统可以通过配置参数来对业务进行调整,执行的sql语句中加入了@参数Name=@Name or @Name = '',上网经过搜索,发现参数不会对sql执行造成影响,但是如果你的where条件中的@参数正好加入了索引,那么影响就相当显著了。加入强制执行索引:
with(index(IX_Name)),效率有显示提升,奈何现场的视图已无参加维护。
Join
查询数据源采用了left join联表查询,问题来了,主表2w多行的数据,副表也是3w多行的数据,比较奇葩的使用了两个视图联表查询,还是那句没有厂家维护。联表查询n*m,那么减少基础表的记录数目可以有效的提高效率。那么把条件搜索放入到基础表先进性过滤,然后再进行联合查询。
select top 500 * from(select * from [dbo].[table1] where (ss between @a1 and @a2)) a
LEFT JOIN dbo.[table2] ON a.m = dbo.[table2].n
结构化查询语言(Structured Query Language)简称SQL(发音:/ˈes kjuː ˈel/ "S-Q-L"),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。
1986年10月,美国国家标准协会对SQL进行规范后,以此作为关系式数据库管理系统的标准语言(ANSI X3. 135-1986),1987年得到国际标准组织的支持下成为国际标准。不过各种通行的数据库系统在其实践过程中都对SQL规范作了某些编改和扩充。所以,实际上不同数据库系统之间的SQL不能完全相互通用。
参考资料:
sql优化-百度百科
1.查询的模糊匹配
尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用。
解决办法:
其实只需要对该脚本略做改进,查询速度便会提高近百倍。改进方法如下:
a、修改前台程序——把查询条件的供应商名称一栏由原来的文本输入改为下拉列表,用户模糊输入供应商名称时,直接在前台就帮忙定位到具体的供应商,这样在调用后台程序时,这列就可以直接用等于来关联了。
b、直接修改后台——根据输入条件,先查出符合条件的供应商,并把相关记录保存在一个临时表里头,然后再用临时表去做复杂关联。
2.索引问题
在做性能跟踪分析过程中,经常发现有不少后台程序的性能问题是因为缺少合适索引造成的,有些表甚至一个索引都没有。这种情况往往都是因为在设计表时,没去定义索引,而开发初期,由于表记录很少,索引创建与否,可能对性能没啥影响,开发人员因此也未多加重视。然一旦程序发布到生产环境,随着时间的推移,表记录越来越多。这时缺少索引,对性能的影响便会越来越大了。
法则:不要在建立的索引的数据列上进行下列操作:
避免对索引字段进行计算操作
避免在索引字段上使用not,<>,!=
避免在索引列上使用IS NULL和IS NOT NULL
避免在索引列上出现数据类型转换
避免在索引字段上使用函数
避免建立索引的列中使用空值
3.复杂操作
部分UPDATE、SELECT 语句 写得很复杂(经常嵌套多级子查询)——可以考虑适当拆成几步,先生成一些临时数据表,再进行关联操作。
4.update
同一个表的修改在一个过程里出现好几十次,如:
update table1 set col1=... where col2=...; update table1 set col1=... where col2=... ...
这类脚本其实可以很简单就整合在一个UPDATE语句来完成(前些时候在协助xxx项目做性能问题分析时就发现存在这种情况)
5.在可以使用UNION ALL的语句里,使用了UNION
UNION 因为会将各查询子集的记录做比较,故比起UNION ALL ,通常速度都会慢上许多。一般来说,如果使用UNION ALL能满足要求的话,务必使用UNION ALL。还有一种情况大家可能会忽略掉,就是虽然要求几个子集的并集需要过滤掉重复记录,但由于脚本的特殊性,不可能存在重复记录,这时便应该使用 UNION ALL,如xx模块的某个查询程序就曾经存在这种情况,见,由于语句的特殊性,在这个脚本中几个子集的记录绝对不可能重复,故可以改用UNION ALL)。
6.在WHERE 语句中,尽量避免对索引字段进行计算操作
这个常识相信绝大部分开发人员都应该知道,但仍有不少人这么使用,我想其中一个最主要的原因可能是为了编写写简单而损害了性能,那就不可取了。9月份在对XX系统做性能分析时发现,有大量的后台程序存在类似用法,如:where trunc(create_date)=trunc(:date1),虽然已对create_date 字段建了索引,但由于加了TRUNC,使得索引无法用上。此处正确的写法应该是where create_date>=trunc(:date1) and create_date< pre=""><>或者是where create_date between trunc(:date1) and trunc(:date1)+1-1/(24*60*60)。
注意:因between 的范围是个闭区间(greater than or equal to low value and less than or equal to high value.),故严格意义上应该再减去一个趋于0的小数,这里暂且设置成减去1秒(1/(24*60*60)),如果不要求这么精确的话,可以略掉这步。
7.对Where 语句的法则
7.1 避免在WHERE子句中使用in,not in,or 或者having。
可以使用 exist 和not exist代替in和not in。
可以使用表链接代替 exist。Having可以用where代替,如果无法代替可以分两步处理。
例子
SELECT * FROM ORDERS WHERE CUSTOMER_NAME NOT IN (SELECT CUSTOMER_NAME FROM CUSTOMER)
优化
SELECT * FROM ORDERS WHERE CUSTOMER_NAME not exist (SELECT CUSTOMER_NAME FROM CUSTOMER)
7.2 不要以字符格式声明数字,要以数字格式声明字符值。(日期同样)否则会使索引无效,产生全表扫描。
例子使用:
SELECT emp.ename, emp.job FROM emp WHERE emp.empno = 7369;
--不要使用:
SELECT emp.ename, emp.job FROM emp WHERE emp.empno = '7369'
8.对Select语句的法则
在应用程序、包和过程中限制使用select * from table这种方式。看下面例子
--使用
SELECT empno,ename,category FROM emp WHERE empno = '7369'
--而不要使用
SELECT * FROM emp WHERE empno = '7369'
9. 排序
避免使用耗费资源的操作,带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎 执行,耗费资源的排序(SORT)功能. DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序。
10.临时表
慎重使用临时表可以极大的提高系统性能。
关于SQL性能优化的知识就介绍到这里了,希望本次的介绍能够带给您一些收获,谢谢!本回答被提问者和网友采纳 参考技术C
这里分享下mysql优化的几种方法。
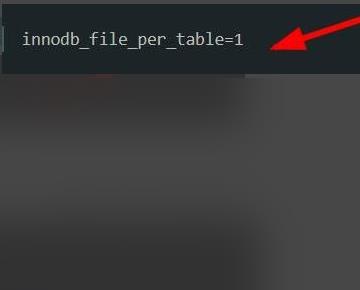
1、首先在打开的软件中,需要分别为每一个表创建 InnoDB FILE的文件。
2、这样能保证从内存中读取数据不会太大,如果太大就达不到优化效果。
3、此时,可以利用语句iostat -d -x -k 1 命令,直接查看硬盘的操作,如下图所示。
4、如果成立就对mysql的数据进行拷贝,这样就达到了mysql优化的功能了,如下图所示就完成了。
分析oracle的执行计划(explain plan)并对对sql进行优化实践
基于oracle的应用系统很多性能问题,是由应用系统sql性能低劣引起的,所以,sql的性能优化很重要,分析与优化sql的性能我们一般通过查看该sql的执行计划,本文就如何看懂执行计划,以及如何通过分析执行计划对sql进行优化做相应说明。
一、什么是执行计划(explain plan)
执行计划:一条查询语句在oracle中的执行过程或访问路径的描述。
二、如何查看执行计划
1.set autotrace on
2.explain plan for sql语句;
select plan_table_output from table(dbms_xplan.display());
3.通过第3方工具,如plsql developer(f5查看执行计划)、toad等;
三、看懂执行计划
1.执行计划中字段解释
- SQL> select * from scott.emp a,scott.emp b where a.empno=b.mgr;
- 已选择13行。
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 992080948
- ---------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ---------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 13 | 988 | 6 (17)| 00:00:01 |
- | 1 | MERGE JOIN | | 13 | 988 | 6 (17)| 00:00:01 |
- | 2 | TABLE ACCESS BY INDEX ROWID| EMP | 14 | 532 | 2 (0)| 00:00:01 |
- | 3 | INDEX FULL SCAN | PK_EMP | 14 | | 1 (0)| 00:00:01 |
- |* 4 | SORT JOIN | | 13 | 494 | 4 (25)| 00:00:01 |
- |* 5 | TABLE ACCESS FULL | EMP | 13 | 494 | 3 (0)| 00:00:01 |
- ---------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 4 - access("A"."EMPNO"="B"."MGR")
- filter("A"."EMPNO"="B"."MGR")
- 5 - filter("B"."MGR" IS NOT NULL)
- 统计信息
- ----------------------------------------------------------
- 0 recursive calls
- 0 db block gets
- 11 consistent gets
- 0 physical reads
- 0 redo size
- 2091 bytes sent via SQL*Net to client
- 416 bytes received via SQL*Net from client
- 2 SQL*Net roundtrips to/from client
- 1 sorts (memory)
- 0 sorts (disk)
- 13 rows processed
- SQL>
对上面执行计划列字段的解释:
Id: 执行序列,但不是执行的先后顺序。执行的先后根据Operation缩进来判断(采用最右最上最先执行的原则看层次关系,在同一级如果某个动作没有子ID就最先执行。 一般按缩进长度来判断,缩进最大的最先执行,如果有2行缩进一样,那么就先执行上面的。)
如:上面执行计划的执行顺序为:3--》2--》5--》4--》1
Operation: 当前操作的内容。
Name:操作对象
Rows:也就是10g版本以前的Cardinality(基数),Oracle估计当前操作的返回结果集行数。
Bytes:表示执行该步骤后返回的字节数。
Cost(CPU):表示执行到该步骤的一个执行成本,用于说明SQL执行的代价。
Time:Oracle 估计当前操作的时间。
2.谓词说明:
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("A"."EMPNO"="B"."MGR")
filter("A"."EMPNO"="B"."MGR")
5 - filter("B"."MGR" IS NOT NULL)
Access: 表示这个谓词条件的值将会影响数据的访问路劲(全表扫描还是索引)。
Filter:表示谓词条件的值不会影响数据的访问路劲,只起过滤的作用。
在谓词中主要注意access,要考虑谓词的条件,使用的访问路径是否正确。
四、 动态分析
如果在执行计划中有如下提示:
Note
------------
-dynamic sampling used for the statement
这提示用户CBO当前使用的技术,需要用户在分析计划时考虑到这些因素。 当出现这个提示,说明当前表使用了动态采样。 我们从而推断这个表可能没有做过分析。
这里会出现两种情况:
(1) 如果表没有做过分析,那么CBO可以通过动态采样的方式来获取分析数据,也可以或者正确的执行计划。
(2) 如果表分析过,但是分析信息过旧,这时CBO就不会在使用动态采样,而是使用这些旧的分析数据,从而可能导致错误的执行计划。
五、表访问方式
1.Full Table Scan (FTS) 全表扫描
2.Index Lookup 索引扫描
There are 5 methods of index lookup:
index unique scan --索引唯一扫描
Method for looking up a single key value via a unique index. always returns a single value, You must supply AT LEAST the leading column of the index to access data via the index.
index range scan --索引局部扫描
Index range scan is a method for accessing a range values of a particular column. AT LEAST the leading column of the index must be supplied to access data via the index. Can be used for range operations (e.g. > < <> >= <= between) .
index full scan --索引全局扫描
Full index scans are only available in the CBO as otherwise we are unable to determine whether a full scan would be a good idea or not. We choose an index Full Scan when we have statistics that indicate that it is going to be more efficient than a Full table scan and a sort. For example we may do a Full index scan when we do an unbounded scan of an index and want the data to be ordered in the index order.
index fast full scan --索引快速全局扫描,不带order by情况下常发生
Scans all the block in the index, Rows are not returned in sorted order, Introduced in 7.3 and requires V733_PLANS_ENABLED=TRUE and CBO, may be hinted using INDEX_FFS hint, uses multiblock i/o, can be executed in parallel, can be used to access second column of concatenated indexes. This is because we are selecting all of the index.
index skip scan --索引跳跃扫描,where条件列是非索引的前导列情况下常发生
Index skip scan finds rows even if the column is not the leading column of a concatenated index. It skips the first column(s) during the search.
3.Rowid 物理ID扫描
This is the quickest access method available.Oracle retrieves the specified block and extracts the rows it is interested in. --Rowid扫描是最快的访问数据方式
六、表连接方式
请参照另一篇文章:Oracle 表连接方式详解
http://www.fengfly.com/plus/view-210420-1.html
七、运算符
1.sort --排序,很消耗资源
There are a number of different operations that promote sorts:
(1)order by clauses (2)group by (3)sort merge join –-这三个会产生排序运算
2.filter --过滤,如not in、min函数等容易产生
Has a number of different meanings, used to indicate partition elimination, may also indicate an actual filter step where one row source is filtering, another, functions such as min may introduce filter steps into query plans.
3.view --视图,大都由内联视图产生(可能深入到视图基表)
When a view cannot be merged into the main query you will often see a projection view operation. This indicates that the ‘view‘ will be selected from directly as opposed to being broken down into joins on the base tables. A number of constructs make a view non mergeable. Inline views are also non mergeable.
4.partition view --分区视图
Partition views are a legacy technology that were superceded by the partitioning option. This section of the article is provided as reference for such legacy systems.
附:oracle优化器(Optimizer)
Oracle 数据库中优化器(Optimizer)是SQL分析和执行的优化工具,它负责指定SQL的执行计划,也就是它负责保证SQL执行的效率最高,比如优化器决定Oracle 以什么样的方式来访问数据,是全表扫描(Full Table Scan),索引范围扫描(Index Range Scan)还是全索引快速扫描(INDEX Fast Full Scan:INDEX_FFS);对于表关联查询,它负责确定表之间以一种什么方式来关联,比如HASH_JOHN还是NESTED LOOPS 或者MERGE JOIN。 这些因素直接决定SQL的执行效率,所以优化器是SQL 执行的核心,它做出的执行计划好坏,直接决定着SQL的执行效率。
Oracle 的优化器有两种:
RBO(Rule-Based Optimization): 基于规则的优化器
CBO(Cost-Based Optimization): 基于代价的优化器
从Oracle 10g开始,RBO 已经被弃用,但是我们依然可以通过Hint 方式来使用它。
在Oracle 10g中,CBO 可选的运行模式有2种:
(1) FIRST_ROWS(n)
Oracle 在执行SQL时,优先考虑将结果集中的前n条记录以最快的速度反馈回来,而其他的结果并不需要同时返回。
(2) ALL_ROWS -- 10g中的默认值
Oracle 会用最快的速度将SQL执行完毕,将结果集全部返回,它和FIRST_ROWS(n)的区别在于,ALL_ROWS强调以最快的速度将SQL执行完毕,并将所有的结果集反馈回来,而FIRST_ROWS(n)则侧重于返回前n条记录的执行时间。
修改CBO 模式的三种方法:
(1) SQL 语句:
Sessions级别:
SQL> alter session set optimizer_mode=all_rows;
(2) 修改pfile 参数:
OPTIMIZER_MODE=RULE/CHOOSE/FIRST_ROWS/ALL_ROWS
(3) 语句级别用Hint(/* + ... */)来设定
Select /*+ first_rows(10) */ name from table;
Select /*+ all_rows */ name from table;
以上是关于如何进行SQL性能优化的主要内容,如果未能解决你的问题,请参考以下文章