Python学习之路——Day11(I/O多路复用)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python学习之路——Day11(I/O多路复用)相关的知识,希望对你有一定的参考价值。
协程
协程,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
协程的好处:
- 无需线程上下文切换的开销
- 无需原子操作锁定及同步的开销
- "原子操作(atomic operation)是不需要synchronized",所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序是不可以被打乱,或者切割掉只执行部分。视作整体是原子性的核心。
- 方便切换控制流,简化编程模型
- 高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
使用yield实现协程操作例子


import time import queue def consumer(name): print("--->starting eating baozi...") while True: new_baozi = yield print("[%s] is eating baozi %s" % (name,new_baozi)) #time.sleep(1) def producer(): r = con.__next__() r = con2.__next__() n = 0 while n < 5: n +=1 con.send(n) con2.send(n) print("\\033[32;1m[producer]\\033[0m is making baozi %s" %n ) if __name__ == ‘__main__‘: con = consumer("c1") con2 = consumer("c2") p = producer()
看楼上的例子,我问你这算不算做是协程呢?你说,我他妈哪知道呀,你前面说了一堆废话,但是并没告诉我协程的标准形态呀,我腚眼一想,觉得你说也对,那好,我们先给协程一个标准定义,即符合什么条件就能称之为协程:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 一个协程遇到IO操作自动切换到其它协程
基于上面这4点定义,我们刚才用yield实现的程并不能算是合格的线程,因为它有一点功能没实现,哪一点呢?
Greenlet
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
# -*- coding:utf-8 -*- from greenlet import greenlet def test1(): print(12) gr2.switch() print(34) gr2.switch() def test2(): print(56) gr1.switch() print(78) gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch()
感觉确实用着比generator还简单了呢,但好像还没有解决一个问题,就是遇到IO操作,自动切换,对不对?
Gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
import gevent
def func1():
print(‘\\033[31;1m李闯在跟海涛搞...\\033[0m‘)
gevent.sleep(2)
print(‘\\033[31;1m李闯又回去跟继续跟海涛搞...\\033[0m‘)
def func2():
print(‘\\033[32;1m李闯切换到了跟海龙搞...\\033[0m‘)
gevent.sleep(1)
print(‘\\033[32;1m李闯搞完了海涛,回来继续跟海龙搞...\\033[0m‘)
gevent.joinall([
gevent.spawn(func1),
gevent.spawn(func2),
#gevent.spawn(func3),
])
输出:
李闯在跟海涛搞...
李闯切换到了跟海龙搞...
李闯搞完了海涛,回来继续跟海龙搞...
李闯又回去跟继续跟海涛搞...
同步与异步的性能区别
import gevent def task(pid): """ Some non-deterministic task """ gevent.sleep(0.5) print(‘Task %s done‘ % pid) def synchronous(): for i in range(1,10): task(i) def asynchronous(): threads = [gevent.spawn(task, i) for i in range(10)] gevent.joinall(threads) print(‘Synchronous:‘) synchronous() print(‘Asynchronous:‘) asynchronous()
上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
遇到IO阻塞时会自动切换任务
from gevent import monkey; monkey.patch_all() import gevent from urllib.request import urlopen def f(url): print(‘GET: %s‘ % url) resp = urlopen(url) data = resp.read() print(‘%d bytes received from %s.‘ % (len(data), url)) gevent.joinall([ gevent.spawn(f, ‘https://www.python.org/‘), gevent.spawn(f, ‘https://www.yahoo.com/‘), gevent.spawn(f, ‘https://github.com/‘), ])
通过gevent实现单线程下的多socket并发
server side
import sys import socket import time import gevent from gevent import socket,monkey monkey.patch_all() def server(port): s = socket.socket() s.bind((‘0.0.0.0‘, port)) s.listen(500) while True: cli, addr = s.accept() gevent.spawn(handle_request, cli) def handle_request(conn): try: while True: data = conn.recv(1024) print("recv:", data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) except Exception as ex: print(ex) finally: conn.close() if __name__ == ‘__main__‘: server(8001)
client side
import socket HOST = ‘localhost‘ # The remote host PORT = 8001 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"),encoding="utf8") s.sendall(msg) data = s.recv(1024) #print(data) print(‘Received‘, repr(data)) s.close()
import socket import threading def sock_conn(): client = socket.socket() client.connect(("localhost",8001)) count = 0 while True: #msg = input(">>:").strip() #if len(msg) == 0:continue client.send( ("hello %s" %count).encode("utf-8")) data = client.recv(1024) print("[%s]recv from server:" % threading.get_ident(),data.decode()) #结果 count +=1 client.close() for i in range(100): t = threading.Thread(target=sock_conn) t.start()
论事件驱动与异步IO
看图说话讲事件驱动模型
在UI编程中,常常要对鼠标点击进行相应,首先如何获得鼠标点击呢?
方式一:创建一个线程,该线程一直循环检测是否有鼠标点击,那么这个方式有以下几个缺点:
1. CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
2. 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
3. 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
方式二:就是事件驱动模型
目前大部分的UI编程都是事件驱动模型,如很多UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;
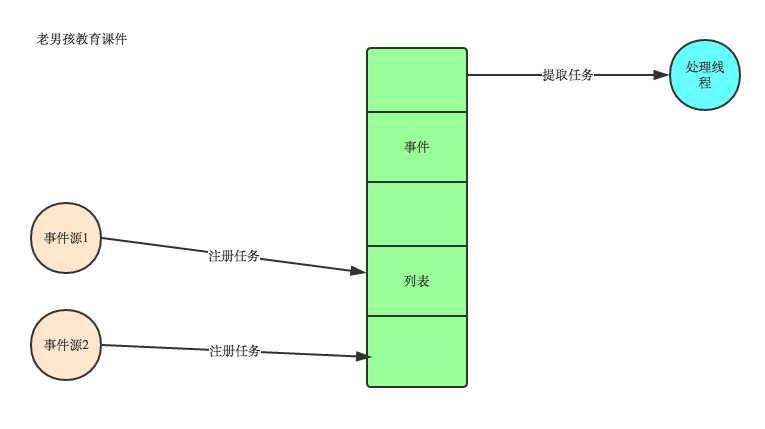
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外两种常见的编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。
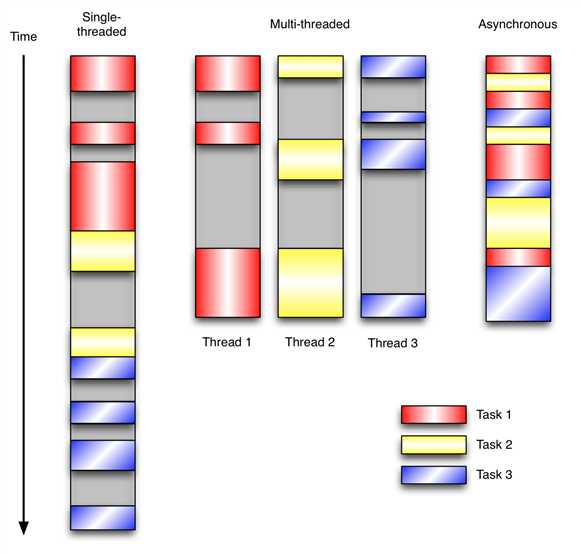
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务,而且…
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)而且…
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
此处要提出一个问题,就是,上面的事件驱动模型中,只要一遇到IO就注册一个事件,然后主程序就可以继续干其它的事情了,只到io处理完毕后,继续恢复之前中断的任务,这本质上是怎么实现的呢?哈哈,下面我们就来一起揭开这神秘的面纱。。。。
Select\\Poll\\Epoll异步IO
http://www.cnblogs.com/alex3714/p/4372426.html
番外篇 http://www.cnblogs.com/alex3714/articles/5876749.html
select 多并发socket 例子
#_*_coding:utf-8_*_ __author__ = ‘Alex Li‘ import select import socket import sys import queue server = socket.socket() server.setblocking(0) server_addr = (‘localhost‘,10000) print(‘starting up on %s port %s‘ % server_addr) server.bind(server_addr) server.listen(5) inputs = [server, ] #自己也要监测呀,因为server本身也是个fd outputs = [] message_queues = {} while True: print("waiting for next event...") readable, writeable, exeptional = select.select(inputs,outputs,inputs) #如果没有任何fd就绪,那程序就会一直阻塞在这里 for s in readable: #每个s就是一个socket if s is server: #别忘记,上面我们server自己也当做一个fd放在了inputs列表里,传给了select,如果这个s是server,代表server这个fd就绪了, #就是有活动了, 什么情况下它才有活动? 当然 是有新连接进来的时候 呀 #新连接进来了,接受这个连接 conn, client_addr = s.accept() print("new connection from",client_addr) conn.setblocking(0) inputs.append(conn) #为了不阻塞整个程序,我们不会立刻在这里开始接收客户端发来的数据, 把它放到inputs里, 下一次loop时,这个新连接 #就会被交给select去监听,如果这个连接的客户端发来了数据 ,那这个连接的fd在server端就会变成就续的,select就会把这个连接返回,返回到 #readable 列表里,然后你就可以loop readable列表,取出这个连接,开始接收数据了, 下面就是这么干 的 message_queues[conn] = queue.Queue() #接收到客户端的数据后,不立刻返回 ,暂存在队列里,以后发送 else: #s不是server的话,那就只能是一个 与客户端建立的连接的fd了 #客户端的数据过来了,在这接收 data = s.recv(1024) if data: print("收到来自[%s]的数据:" % s.getpeername()[0], data) message_queues[s].put(data) #收到的数据先放到queue里,一会返回给客户端 if s not in outputs: outputs.append(s) #为了不影响处理与其它客户端的连接 , 这里不立刻返回数据给客户端 else:#如果收不到data代表什么呢? 代表客户端断开了呀 print("客户端断开了",s) if s in outputs: outputs.remove(s) #清理已断开的连接 inputs.remove(s) #清理已断开的连接 del message_queues[s] ##清理已断开的连接 for s in writeable: try : next_msg = message_queues[s].get_nowait() except queue.Empty: print("client [%s]" %s.getpeername()[0], "queue is empty..") outputs.remove(s) else: print("sending msg to [%s]"%s.getpeername()[0], next_msg) s.send(next_msg.upper()) for s in exeptional: print("handling exception for ",s.getpeername()) inputs.remove(s) if s in outputs: outputs.remove(s) s.close() del message_queues[s]
#_*_coding:utf-8_*_ __author__ = ‘Alex Li‘ import socket import sys messages = [ b‘This is the message. ‘, b‘It will be sent ‘, b‘in parts.‘, ] server_address = (‘localhost‘, 10000) # Create a TCP/IP socket socks = [ socket.socket(socket.AF_INET, socket.SOCK_STREAM), socket.socket(socket.AF_INET, socket.SOCK_STREAM), ] # Connect the socket to the port where the server is listening print(‘connecting to %s port %s‘ % server_address) for s in socks: s.connect(server_address) for message in messages: # Send messages on both sockets for s in socks: print(‘%s: sending "%s"‘ % (s.getsockname(), message) ) s.send(message) # Read responses on both sockets for s in socks: data = s.recv(1024) print( ‘%s: received "%s"‘ % (s.getsockname(), data) ) if not data: print(sys.stderr, ‘closing socket‘, s.getsockname() )
selectors模块
This module allows high-level and efficient I/O multiplexing, built upon the select module primitives. Users are encouraged to use this module instead, unless they want precise control over the OS-level primitives used.
import selectors
import socket
sel = selectors.DefaultSelector()
def accept(sock, mask):
conn, addr = sock.accept() # Should be ready
print(‘accepted‘, conn, ‘from‘, addr)
conn.setblocking(False)
sel.register(conn, selectors.EVENT_READ, read)
def read(conn, mask):
data = conn.recv(1000) # Should be ready
if data:
print(‘echoing‘, repr(data), ‘to‘, conn)
conn.send(data) # Hope it won‘t block
else:
print(‘closing‘, conn)
sel.unregister(conn)
conn.close()
sock = socket.socket()
sock.bind((‘localhost‘, 10000))
sock.listen(100)
sock.setblocking(False)
sel.register(sock, selectors.EVENT_READ, accept)
while True:
events = sel.select()
for key, mask in events:
callback = key.data
callback(key.fileobj, mask)
参考:http://www.cnblogs.com/alex3714/articles/5248247.html
以上是关于Python学习之路——Day11(I/O多路复用)的主要内容,如果未能解决你的问题,请参考以下文章
11.python并发入门(part14阻塞I/O与非阻塞I/O,以及引入I/O多路复用)