11.python并发入门(part14阻塞I/O与非阻塞I/O,以及引入I/O多路复用)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了11.python并发入门(part14阻塞I/O与非阻塞I/O,以及引入I/O多路复用)相关的知识,希望对你有一定的参考价值。
一、初步了解什么是I/O模型。
1.回顾,用户态与内核态。
操作系统位于应用程序和硬件之间,本质上是一个软件,它由内核以及系统调用组成。
内核:用于运行于内核态,主要作用是管理硬件资源。
系统调用:运行与用户态,为应用程序提供系统调用的接口。
操作系统的核心,就是内核,内核具有访问底层硬件设备的权限,为了保证用户无法直接对内核进行操作,并且保证内核的安全,所以就划分了用户空间和内核空间。
2.回顾进程切换。
如果说要实现进程之间的切换,那么进程需要有能力挂起,有能力回复,这样才叫切换。
进程与进程之间的切换是由操作系统来完成的!
假如说有多个进程,其中有个进程正在cpu上运行,现在需要切换到另一个线程,之间都发生了什么?
第一步:保存cpu上下文,程序计数器,以及寄存器。
第二步:更新PCB信息,把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列,选择另一个进程执行,并更新其PCB。
第三步:更新内存管理的数据结构。
第四步:恢复处理器的上下文
#这几步理解不了无所谓....其实主要就是想说明,进程和进程之间进行切换真的很耗资源!!!
3.回顾进程阻塞。
正在执行的进程,这个进程在等待数据,或者说,请求资源失败,或者,等待的某种事物没有发生。
系统就会将这个进程的状态改为阻塞(block)状态。
阻塞,也可以说是进程自己的一种主动行为。
只有进程处于运行状态的时候,才会获得cpu资源,如果当一个进程变为了阻塞状态,是不会对cpu资源造成占用的。(阻塞完全不占用cpu资源。)
4.回顾文件描述符。
个人觉得文件描述符这种东西,只有在unix,linux(各种类unix系统)上才会存在。
是一个用来引用文件的一个很抽象的概念。
文件描述符的表达形式,是一个非负数的整数。
我一直把文件描述符理解为一个索引,这个索引指向了每个进程打开的每个文件的一个记录表。
当一个应用程序或者一个进程,打开或者创建一个文件的时候,内核就会返回一个文件描述符。
linux的文件描述符一旦被耗尽,会导致一些应用程序无法正常运行,无法创建socket文件等....
5.缓存I/O。(数据在内核态和用户态之间来回复制)
拿socket通信来举例吧,两台机器之间通过socket来进行通信,当计算机A给计算机B发送一个数据的时候,是直接发送给计算机B的吗?其实并不是,计算机A在发送数据时,首先会从用户态转换为内核态,然后把数据交给自己的网卡,再对外进行发送。
接收端在接收数据的时候,由内核态转交给用户态。
数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。用户空间没法直接访问内核空间的。(可以理解为数据从内核态被复制到了用户态)
通过上面的例子,说明了缓存I/O是由缺点的,数据在传输的过程中,数据需要在应用程序地址空间(用户态),和内核空间(内核态)中进行来回的数据拷贝操作!对CPU和内存的开销都是非常大的!
6.I/O模型简单介绍。
I/O模型到底是什么?不同的I/O模型到底有什么区别?
就拿socket网路通信来举例吧,socket通信属于网络I/O,执行accept(等待连接)和recv(等待数据接收)时,会涉及到两个系统对象,一个是调用这个I/O操作的线程或者进程,另外就是系统内核。
等待数据的准备。
然后将数据从内核空间拷贝到进程中
下面总结了四种比较常用的I/O模型:
(1).blocking IO(阻塞IO)(unix/linux默认的一中I/O模型)
在linux和类unix系统下,所有的socket对象都是blocking I/O模型,下面是一个阻塞I/O模型的运行流程。
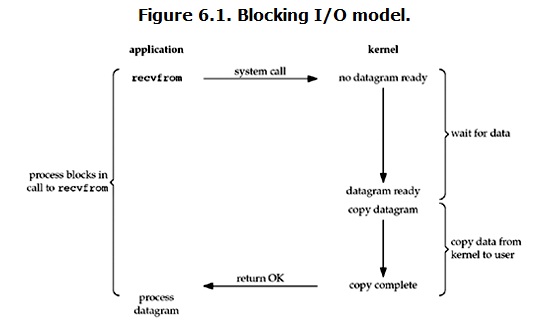
假设现在有两台主机,主机A和主机B要通过socket去通信,主机A现在执行了一个accept()要去等待主机B来连接,这个时候程序中的accepet(这个过程是在向操作系统索要数据!),就会发起一个系统调用“recvfrom”给内核,在主机A执行accept的时候,主机B有去连接主机A吗?主机B什么时候会去连接主机A?这些是未知的,这个时候,就出现了一个等待数据的现象,这个等待现象是操作系统的内核造成的,内核会去等待数据,这个等待的过程就是阻塞的!!主机A的代码就会一直卡在accept的位置,无法继续执行后面的内容(一直等在这)。
这个时候,主机B执行了connect,连接到了主机A,此时内核拿到了数据!(需要注意!此时拿到数据的是内核!)程序无法直接拿到放在内核空间的数据,所以接下来内核会把数据拷贝一份给用户地址空间。此时此刻!!我们的程序才会真正拿到这个数据!
这就是阻塞IO的一个运行流程。
如果说的再简单点儿:
对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
(整个过程中只发起了一次系统调用)
(阻塞IO是同步的,)
(这种I/O模型效率偏低,但是数据可以得到及时的处理。)
(2).nonbloking IO (非阻塞IO)
其他的系统不太清楚,但是在linux系统下,可以通过设置socket(setblocking方法),可以改变socket的阻塞模型为非阻塞模型,非阻塞模型的运行流程如下:
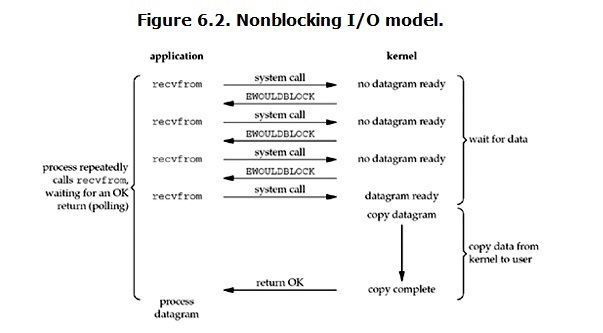
还拿前面说的主机A和主机B通信的例子来说,主机A和主机B要通过socket去通信,主机A现在执行了一个accept()要去等待主机B来连接,这时会发起一个recvfrom的系统调用,此时如果kernel中还没有收到主机B的连接,或者说数据还没有准备好,这时不会去阻塞这个进程,而是返回一个error(IO阻塞异常)(主机A这端的程序不会一直等待,而是会直接返回结果)。此时用户的程序去做一个判断,判断这次recvfrom系统调用的结果是不是error,如果是error(I/O阻塞异常)则说明了数据还没有准备好,但是这个程序不会被阻塞,还可以去做点其他事情,也可以再次accept或者recv(发起recvfrom系统调用),一旦内核中的数据准备好了,并且再次收到了程序的系统调用,那么,马上就会把数据从内核的内存空间直接拷贝到用户的内存空间。
所以,使用非阻塞IO模型的情况下,用户的进程需要不停的询问内核,是否有把数据准备好。
在网络I/O中,使用非阻塞I/O模型,发起recvfrom这个系统调用后,进程没有被阻塞,内核直接返回结果给进程,如果数据没准备好会返回一个错误,进程在返回之后,可以干点别的事情,然后再发起recvform系统调用,一直重复上面的过程。
循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。
最后还有一点要注意!!!!非阻塞I/O模型,并不是全程无阻塞的,内核要给用户控件拷贝数据的时候,这个时候时间虽然非常短!!但这个过程一定是阻塞的!!!!
下面是个非阻塞模型的网络I/O示例:
服务端:
import time
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sk.setsockopt
sk.bind((‘127.0.0.1‘,6667))
sk.listen(5)
sk.setblocking(False) #设置非阻塞I/O模型
while True:
try:
print (‘waiting client connection .......‘)
connection,address = sk.accept() # 进程主动轮询
print("+++",address)
client_messge = connection.recv(1024)
print(str(client_messge,‘utf8‘))
connection.close()
except Exception as e:
print (e)
time.sleep(4)
客户端:
import time
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
while True:
sk.connect((‘127.0.0.1‘,6667))
print("hello")
sk.sendall(bytes("hello","utf8"))
time.sleep(2)
break
其实这种非阻塞I/O模型看起来效率很高,但是也有缺点:
首先,这种非阻塞的I/O模型会发送很多的系统调用。
其次,数据无法及时的被处理,先来看看上面那个例子,每次轮询内核数据的时候,如果发现内核没有准备好数据,需要sleep 4秒,在sleep的这4秒钟,刚sleep两秒,内核中的数据准备好了,但是这时sleep才刚执行了2秒,还有2秒没有sleep完,需要再等待两秒,才会从新去轮询检查一次内核的数据(也就是说,想拿到数据,还要再过两秒),所以说,数据没有办法及时得到处理。
(3).IO multiplexing(I/O多路复用)
I/O多路复用的好处就在于单个进程,可以同时处理多个网络连接的I/O,其实就是又select/epoll这两个函数去不断的轮询所有的socket,一旦有socket的状态发生变化,就会去通知用户进程(程序)。
I/O多路复用的基本运行流程图如下:
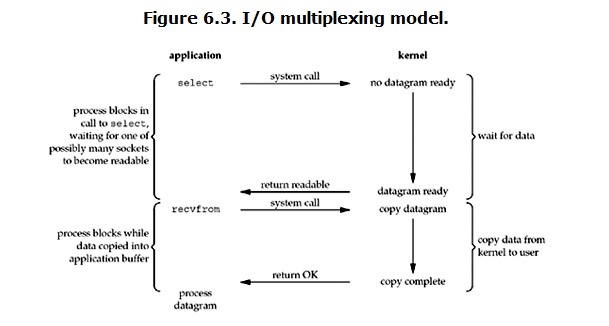
首先由select函数发起一个系统调用,这个系统调用也叫select,一但调用了这个select,整个进程就会进入阻塞状态,此时,内核回去检测,所有select负责的socket,当select负责的这些socket中,其中只要有一个socket的状态发生了改变,那么select就会立刻返回。用户就可以收到来自这个socket发来的数据。
其实select这个图和阻塞I/O很像,貌似没什么区别,但是,使用select是由优势的,select可以同时处理多个连接。
如果处理的并发连接数不是很高的情况下,使用这种IO多路复用,可能还没有多线程+IO阻塞的性能好,甚至可能会加大延迟。
注意!!IO多路复用select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
在I/O多路复用的模式中,每一个socket,一般都设置为非阻塞,但是整个用户的进程其实是一直被阻塞的!和默认的I/O阻塞不同,这个阻塞是因为进程被select函Lock导致的,和I/O造成的阻塞其实不是一回事。
一旦select函数返回的结果中有内容可以拿了,那么进程就可以调用accpet或者recv将位于内核空间的数据copy到用户空间中。
只有在处理特别多的连接数时,才需要考虑使用select函数,如果只处理单个连接,无法体现出select的优势!
下面是select函数基本用法的一个示例:
服务端:
#!/usr/local/bin/python2.7
# -*- coding:utf-8 -*-
import socket
import select
socket_obj = socket.socket()
socket_obj.bind(("127.0.0.1",8889))
socket_obj.listen(5)
while True:
r,w,e = select.select([socket_obj,],[],[],5) #用来检测socket_obj这个socket对象是否产生了变化,如果有变化,返回给变量r,(5代表5秒后,即使socket没有任何变化,代码也会向下执行!)
#一旦这个socket产生了变化之后,变量r就有内容了。
for i in r:
print "conn ok!"
print (‘wait.....‘)
客户端:
#!/usr/local/bin/python2.7
# -*- coding:utf-8 -*-
import socket
socket_client = socket.socket()
socket_client.connect(("127.0.0.1",8889))
while True:
inpt = raw_input(">>>").strip()
socket_client.send(inpt.encode("utf-8"))
data = socket_client.recv(1024)
print data.decode("utf8")
(也许有人很好奇,select检测socket对象的机制是什么样的,其实select使用的是一种名为“水平触发”的检测机制。关于边缘触发和水平触发,后面会有详细介绍。)
(4).asynchronous IO (异步I/O)
也是一个用的不太多的I/O模型,下面是运行流程图。
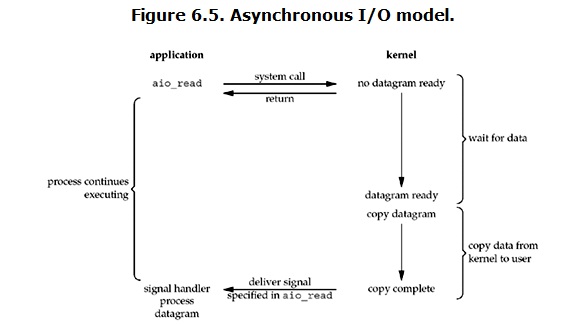
用户程序首先发起一个aio_read系统调用,发起系统调用后,用户程序就会继续做其他的事情,当内核接收到了aio_read这个系统调用后,会像非阻塞IO一样,立刻返回一个结果,此时内核会等待数据准备完成, 然后将数据拷贝到内存空间,拷贝结束后,内核会给用户进程发送一个信号,告诉用户的进程,数据拷贝结束。
注意!!!
说道这里,有人可能会把异步I/O模型和非阻塞I/O模型的概念混淆,其实这两个I/O模型的区别还是很大的。
在使用非阻塞I/O模型的时候,进程的大部分时间都不会被Block,但是进程要主动去检查内核中的数据是否准备好,如果数据准备好了,还需要进程去发起一个recvfrom来将数据从内核空间拷贝到用户空间。
异步I/O模型则完全不同,感觉更像是用户进程把I/O操作直接交给了内核,等内核做完I/O操作,再去通知用户进程,在这个过程中,用户不需要去检查内核是否有将数据准备好,并且也不需要主动去将内核空间的数据拷贝到用户空间。
本文出自 “reBiRTH” 博客,请务必保留此出处http://suhaozhi.blog.51cto.com/7272298/1927374
以上是关于11.python并发入门(part14阻塞I/O与非阻塞I/O,以及引入I/O多路复用)的主要内容,如果未能解决你的问题,请参考以下文章
11.python并发入门(part1 初识进程与线程,并发,并行,同步,异步)
11.python并发入门(part6 Semaphore信号量)