python学习 day5
Posted 2625377029wwj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习 day5相关的知识,希望对你有一定的参考价值。
模块
1.定义:
模块本质上就是以.py结尾的python文件,用来从逻辑上组织python代码(变量,函数,类),从而实现其功能。
包本质上是一个目录(必须包含一个_init_.py文件),用来从逻辑上组织模块。
2.导入方法:
import module_name
import module_name1,module_name2
from module_name import *
from module_name import name1,name2
from module_name import name as name2
3.import本质:
导入模块的本质就是把python文件解释一遍。
导入包的本质是执行该包下的_init_.py文件。
4.导入优化:
import module ------>module.name()
from module import name-------->name()
在多次使用name函数的情况下,后者可以省略重复的在module中寻找name函数的过程。
5.模块的分类:
a.标准模块(内置模块)
b.开源模块(第三方模块)
c.自定义模块
一,标准模块
1 time与datetime模块
time模块:
时间的表现形式 :(1)time.time()时间戳,从1970年至今的秒数。(2)格式化的时间字符串。(3)元组形式,九要素,年月日,时分秒,一周中的第几天,一年中的第几天,是否为夏令时。
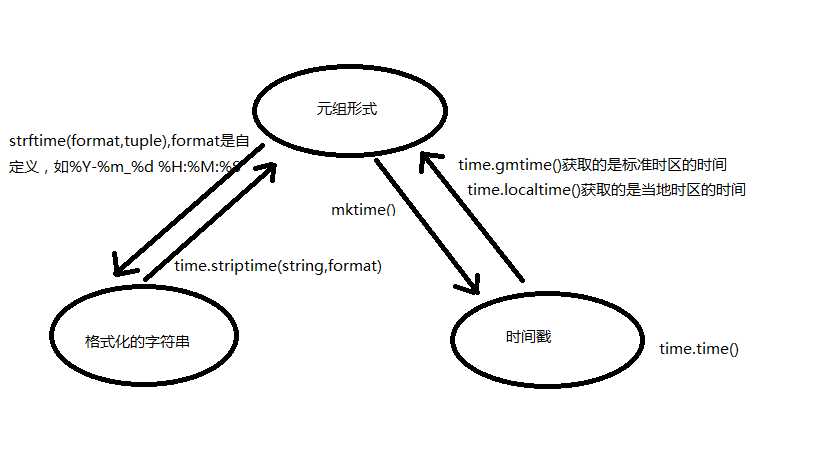
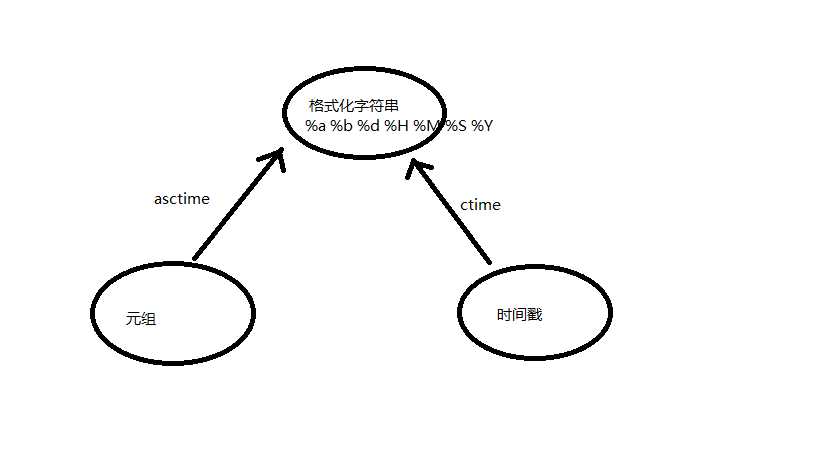
datetime模块:
获取当前时间 datetime.datetime.now() 时间加减: datetime.datetime.now()+datetime.timedelta(3) 当前时间向后3天 datetime.datetime.now()+datetime.timedelta(-3) 当前时间向前3天 datetime.datetime.now()+datetime.timedelta(hours=-3) 当前时间向前3小时 datetime.datetime.now()+datetime.timedelta(minutes=3) 当前时间向后3分钟
2 random模块
import random #随机整数 print(random.randint(0,99)) #----->10 #随机选取0到100间的偶数 print(random.randrange(0,101,2)) #----->20 #随机浮点数 print(random.random()) # 默认0到1,----->0.8341288849661739 print(random.uniform(1,10)) #----->1.412662519468776 #随机字符 print(random.choice("abnckfhxhu")) #----->h #随机选取字符串 print(random.choice(["apple","pear","banana"])) # 注意,要用列表形式表现----->apple #多个字符串中选取随机数量的字符 print(random.sample("abcdefghijk",3)) #----->[‘h‘, ‘j‘, ‘g‘] #洗牌 items=[1,2,3,4,5,6] print(items) #----->[1, 2, 3, 4, 5, 6] random.shuffle(items) print(items) # 注意,如果直接print上一步,输出为None----->[6, 4, 3, 2, 5, 1]
#简易的4位验证码功能 import random check_code="" for i in range(4): current=random.randint(1,9) if current==i: a=chr(random.randint(65,90)) #chr()将数字转换为ASCII码中对应的对象 else: a=current check_code+=str(a) print(check_code)
3 os模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: (‘.‘) os.pardir 获取当前目录的父目录字符串名:(‘..‘) os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat(‘path/filename‘) 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\\t\\n",Linux下为"\\n" os.pathsep 输出用于分割文件路径的字符串 os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
4 shutil模块
高级的 文件、文件夹、压缩包 处理模块(copy,压缩)
参考http://www.cnblogs.com/wupeiqi/articles/4963027.html
5 json与pickle模块
序列化与反序列化,load,loads,dump,dumps
6 shelve模块
比json、pickle更简便的备份
import shelve import datetime f=shelve.open("shelve_file") name=["alex","alice","wang"] info={"age":22,"sex":"female"} # 备份 # f["name"]=name # f["info"]=info # f["datetime"]=datetime.datetime.now() #读取 print(f.get("name")) f.close()
7 xml模块
参考http://www.cnblogs.com/alex3714/articles/5161349.html
8 正则表达 re模块(模糊匹配)
常用正则表达匹配符号
‘.‘ 默认匹配除\\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 ‘^‘ 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\\nabc\\neee",flags=re.MULTILINE) ‘$‘ 匹配字符结尾,或e.search("foo$","bfoo\\nsdfsf",flags=re.MULTILINE).group()也可以 ‘*‘ 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为[‘abb‘, ‘ab‘, ‘a‘] ‘+‘ 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果[‘ab‘, ‘abb‘] ‘?‘ 匹配前一个字符1次或0次 ‘{m}‘ 匹配前一个字符m次 ‘{n,m}‘ 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果‘abb‘, ‘ab‘, ‘abb‘] ‘|‘ 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果‘ABC‘ ‘(...)‘ 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c ‘\\A‘ 只从字符开头匹配,re.search("\\Aabc","alexabc") 是匹配不到的 ‘\\Z‘ 匹配字符结尾,同$ ‘\\d‘ 匹配数字0-9 ‘\\D‘ 匹配非数字 ‘\\w‘ 匹配[A-Za-z0-9] ‘\\W‘ 匹配非[A-Za-z0-9] ‘s‘ 匹配空白字符、\\t、\\n、\\r , re.search("\\s+","ab\\tc1\\n3").group() 结果 ‘\\t‘ ‘(?P<name>...)‘ 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{‘province‘: ‘3714‘, ‘city‘: ‘81‘, ‘birthday‘: ‘1993‘}
常用正则表达匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.split 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
以上是关于python学习 day5的主要内容,如果未能解决你的问题,请参考以下文章