深度学习--PyTorch维度变换自动拓展合并与分割
Posted ssl-study
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习--PyTorch维度变换自动拓展合并与分割相关的知识,希望对你有一定的参考价值。
深度学习--PyTorch维度变换、自动拓展、合并与分割
一、维度变换
1.1 view/reshape 变换
这两个方法用法相同,就是变换变量的shape,变换前后的数据量相等。
a=torch.rand(4,1,28,28)
a.view(4,28*28)
#tensor([[0.9787, 0.6729, 0.4877, ..., 0.8975, 0.3361, 0.9341],
# [0.4316, 0.8875, 0.2974, ..., 0.3385, 0.5543, 0.5648],
# [0.3156, 0.1170, 0.7126, ..., 0.4445, 0.7357, 0.4900],
# [0.7127, 0.9316, 0.7615, ..., 0.7660, 0.5437, 0.1383]])
a.reshape(4,28*28)
#tensor([[0.9787, 0.6729, 0.4877, ..., 0.8975, 0.3361, 0.9341],
# [0.4316, 0.8875, 0.2974, ..., 0.3385, 0.5543, 0.5648],
# [0.3156, 0.1170, 0.7126, ..., 0.4445, 0.7357, 0.4900],
# [0.7127, 0.9316, 0.7615, ..., 0.7660, 0.5437, 0.1383]])
1.2 squeeze/unsqueeze 挤压/拉伸 维度删除/维度添加
a.shape
#torch.Size([4, 1, 28, 28])
#a.unsqueeze(x) 在x位置之后插入
a.unsqueeze(1).shape
#torch.Size([4, 1, 1, 28, 28])
#a.squeeze(x) 删除x维度
a.squeeze(1).shape
#torch.Size([4, 28, 28])
a.squeeze(0).shape
#torch.Size([4, 1, 28, 28]) 当前维度非0,不会进行压缩
1.3 expand/reapeat 扩展/重复 对一个维度内部的大小进行扩展,增加数据
#b.expand(4,32,14,14) 对维度内进行拓展,用-1表示不对当前层进行操作
a=torch.rand(4,32,14,14)
b=torch.rand(1,32,1,1)
b.shape
#torch.Size([1, 32, 1, 1])
b.expand(4,32,14,14).shape
#torch.Size([4, 32, 14, 14])
#b.repeat(次数) 中间表示当前层拷贝的次数
b.repeat(4,1,14,14).shape
#torch.Size([4, 32, 14, 14])
1.4 转置操作 t/transpose/permute
#t() 只能对2D进行操作
a=torch.randn(3,4)
a.t().shape
#torch.Size([4, 3])
#transpose(d1,d2) 不当的操作可能对信息进行破坏
a=torch.randn(4,3,32,32)
a1=a.transpose(1,3).contiguous().view(4,3*32*32).view(4,32,32,3)
a1.shape
#torch.Size([4, 32, 32, 3])
#permute(d,d,d,d) 对维度下标进行操作
a.permute(3,2,1,0).shape
#torch.Size([32, 32, 3, 4])
二、Broadcast自动扩展
步骤为:
- 在前面插入一个维度dim
- 对新加入的维度进行扩张,扩张成对应的size
符合扩展规则才能用。
三、合并与分割
3.1合并
- cat
#torch.cat([变量,变量],dim) 在当前维度上进行操作
a=torch.rand(4,32,8)
b=torch.rand(5,32,8)
torch.cat([a,b],dim=0).shape
#torch.Size([9, 32, 8])
- stack
#torch.stack([变量,变量],dim) 创建一个新的维度
a=torch.rand(4,3,32,32)
b=torch.rand(4,3,32,32)
torch.stack([a,b],dim=2).shape
#torch.Size([4, 3, 2, 32, 32])
3.2拆分
- split:按照长度拆分
#a.split([b1,b2,b3...],dim=0) 对dim进行拆分
a=torch.rand(2,4,3,32,32)
a1,a2=a.split(1,dim=0)
print(a1.shape)
print(a2.shape)
#torch.Size([1, 4, 3, 32, 32])
#torch.Size([1, 4, 3, 32, 32])
- chunk:按数量进行拆分
#a.chunk(num,dim=0) 对当前dim的size/num进行拆分
a=torch.rand(4,4,3,32,32)
a1,a2=a.chunk(2,dim=0)
print(a1.shape)
print(a2.shape)
#torch.Size([2, 4, 3, 32, 32])
#torch.Size([2, 4, 3, 32, 32])
论文泛读 ResNeXt:深度神经网络的聚合残差变换(ResNet的改进,提出了一种新的维度)
【论文泛读】 ResNeXt:深度神经网络的聚合残差变换
文章目录
2022.3.28-2022.3.29
论文链接: Aggregated Residual Transformations for Deep Neural Networks)
主要思想
简单来说呢,随着很多SOTA模型的出现,从一开始的“特征工程”慢慢地转入了一些“网络工程”,引入了一些新的结构和方法。
在前面说过的网络中呢,VGG作为一种经典的模型,他提出了堆叠相同块(stacking block)的策略,在VGG中是3x3卷积核不断堆叠,并且也通过增加深度提高了准确率。
除此之外,Inception系列网络提出了split-transform-merge的策略,通过多分支卷积实现在低计算开销的前提下去接近大型密集层的表达能力。而这篇文章则是合了stacking block和split-transform-merge的策略,在ResNet的基础上提出了ResNeXt网络架构。
摘要
这里还是简单讲一下摘要,作者提出了一种简单、高度模块化的图像分类网络体系结构。我们的网络是通过重复一个构建块来构建的,该构建块聚合了一组具有相同拓扑的变换。我们的简单设计导致了一个同构的、多分支的体系结构,只需要设置几个超参数。这一策略体现了一个新的维度,我们称之为“Cardinality”(转换集的大小),作为深度和宽度维度之外的一个基本因素。在ImageNet-1K数据集上的实验表明,即使在保持复杂度的限制条件下,增加基数也能够提高分类精度。而且,当我们增加容量时,增加基数比深入或扩大更有效。我们的模型ResNeXt是我们进入ILSVRC2016分类任务的基础,我们获得了第二名。我们进一步研究了ImageNet-5K集合和COCO检测集合上的ResNeXt,也显示了比ResNet对应的更好的结果。
简单来说呢,就是ResNeXt采用 VGGs/ResNets 的网络的 depth 加深方式,同时利用 split-transform-merge 策略.
模型结构
Inception模块
首先我们可以讲一下Inception模块,Inception模块提出了split-transform-merge的策略,但是存在一个问题**网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。**所以说,如果我们要用到自己的数据集,就要重新设置一下我们的众多的超参数
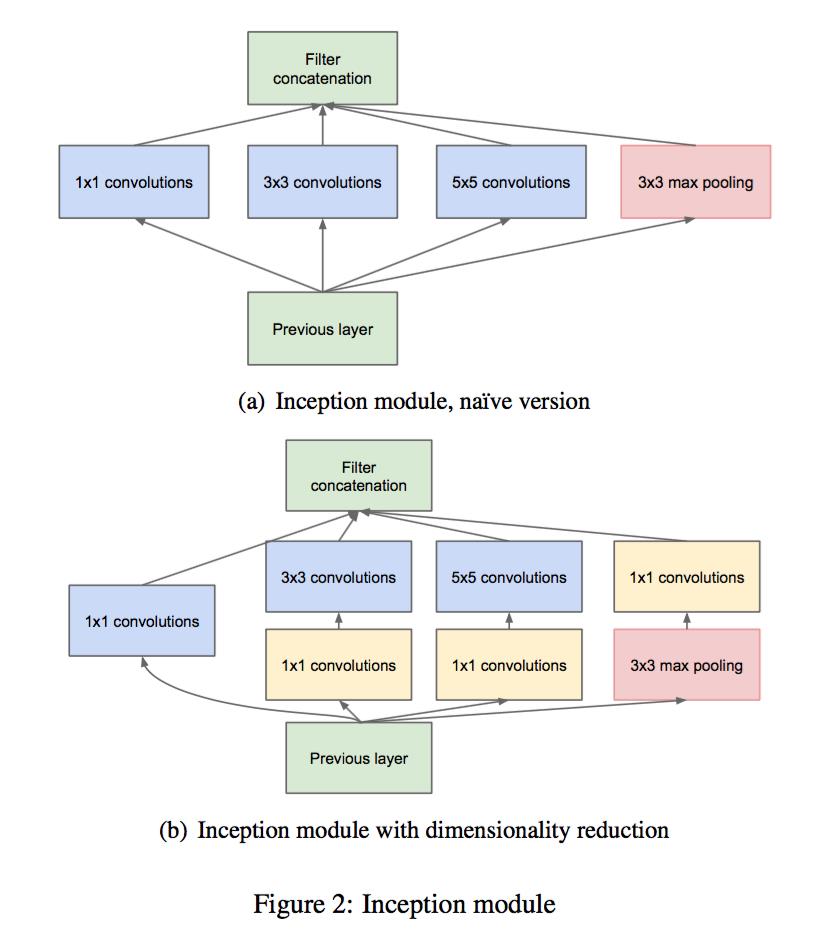
split-transform-merge
作者提出了ResNeXt,同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,论文中也给了一个架构图,X到xi实际上就是一个split的过程,wx就是一个transfrom的过程,最后相加就是一个merge的过程。
- Splitting,X分解为多个低维向量Xi;
- Transforming,每个Xi对应一个Wi以进行变换;
- Aggregating/Merge,每个Xi变换后进行累加;
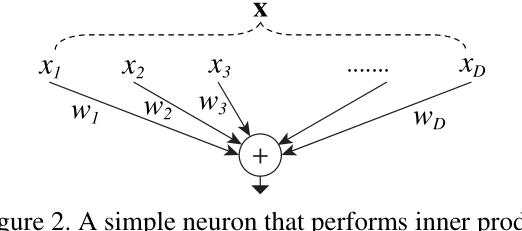
其中将Wi替换为更复杂的函数T(Xi)。在ResNeXt网络中,变换函数使用ResNet中的Bottleneck形式来替代。
分组卷积
分组卷积的思想呢,实际上在很早的AlexNet中就有出现了,在AlexNet的时候,由受限于当时硬件的限制,作者不得不将卷积操作拆分到两台GPU上运行,这两台GPU的参数是不共享的。而我们的分组卷积也是如此,如果我们组数与我们的通道数相同的话,也就是每一个通道利用一个卷积核,这就会变成我们的MobileNet的DW卷积结构了,也就是深度可分离卷积。
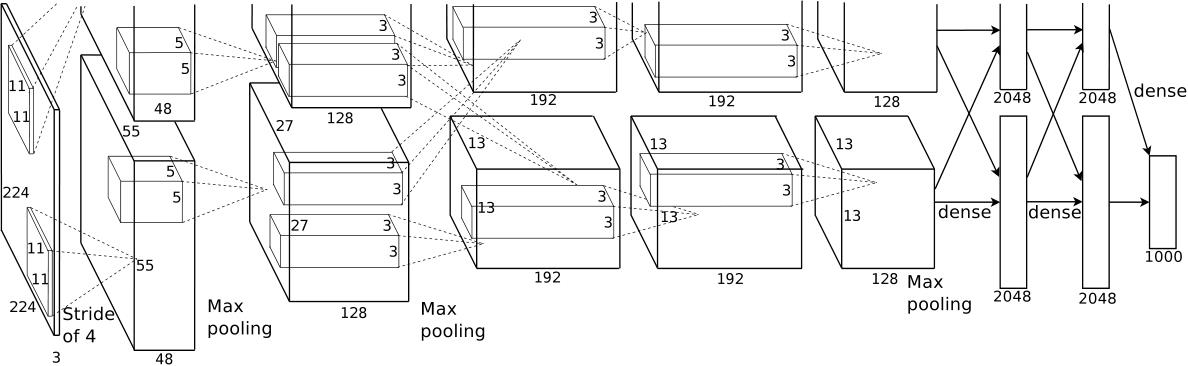
简单来说:Grouped Convolutions:group conv 层中,输入和输出的 channels 被分为 CC 个 groups,分别对每个 group 进行 conv.
比如这个就是深度可分离卷积,每一个通道对应这一个卷积
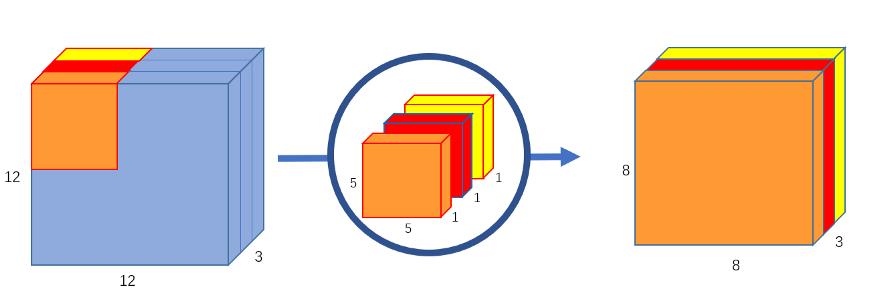
ResNeXt模型结构

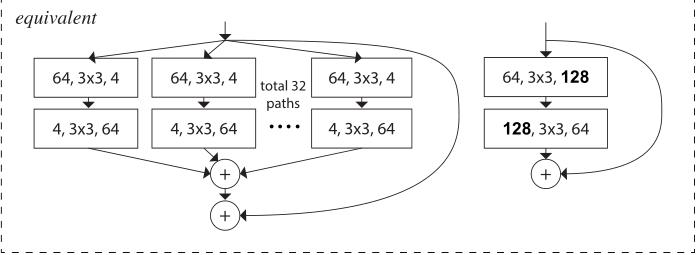
ResNeXt对ResNet进行了改进,采用了多分支的策略,在论文中作者提出了三种等价的模型结构,最后的ResNeXt用了©的结构来构建我们的ResNeXt、这里面和我们的Inception是不同的,在Inception中,每一部分的拓扑结构是不同的,比如一部分是1x1卷积,3x3卷积还有5x5卷积,而我们ResNeXt是用相同的拓扑结构,并在保持参数量的情况下提高了准确率。
这三个结构实际上是等价的,对于选c的原因,其实是因为c结构比较简洁而且速度更快。

这个构建基于两个准则
- 同stage中的block使用相同的width和filter size;
- spatial size减小时,增加channel的数量。
除此之外,作者还提出了一个新的维度,也就是基数(Cardinality)也就是转换集的大小,原文解释是the size of the set of transformations,并且论文中说,这是比深度和宽度更有效的一个维度
除此之外,ResNeXt 只能在 block 的 depth>3时使用. 如果 block 的 depth=2,则会得到宽而密集的模块,所以这也是为什么不在ResNet18和34进行修改的原因
ResNeXt模型评估及结论
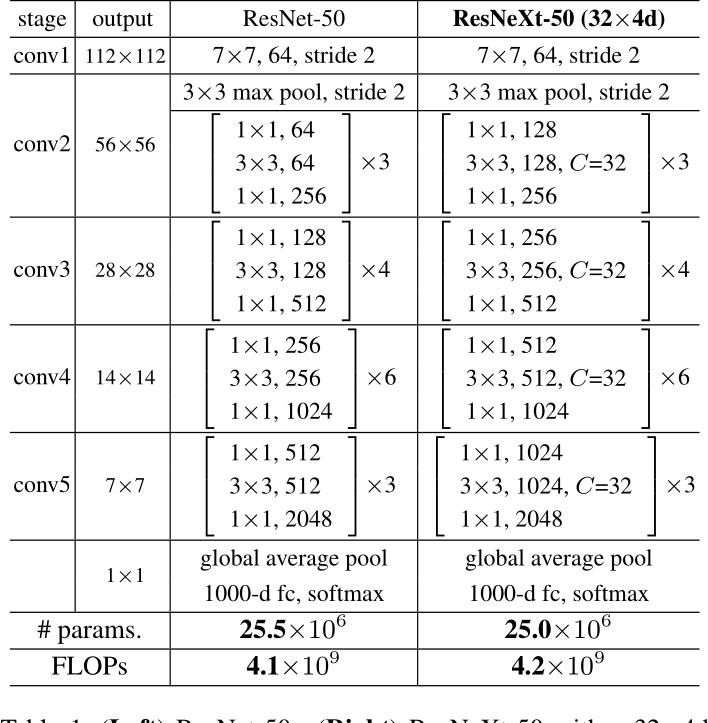
基于上述准则,文章在ResNet-50模型的基础上,提出了ResNeXt-50模型。
我们可以看到,这两者模型的参数是差不多的,复杂度也是差不多的,但是最后在经典数据集ImageNet1k中得到的准确率,ResNeXt更胜一筹。
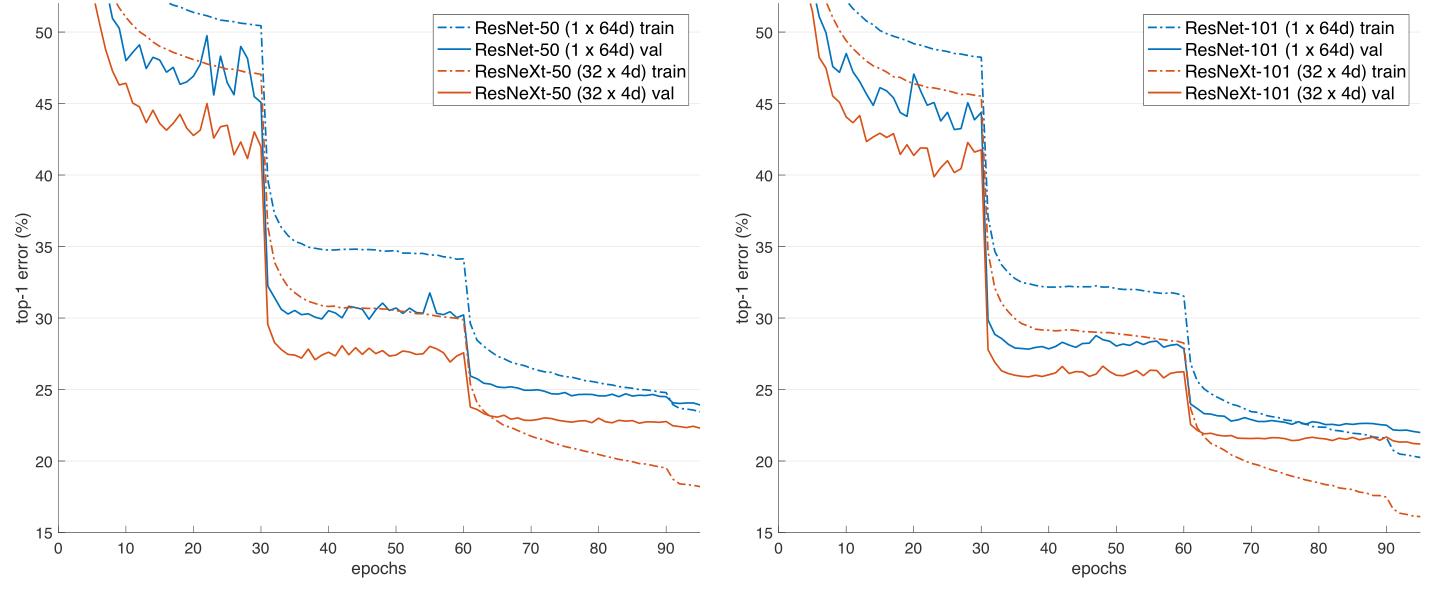
探究Cardinality
这个表主要列举了一些参数,来探究我们的Cardiality,也用来说明模型的结构和参数也是差不多的,第二行的d表示每个path的中间channels数量,最后一行则表示整个block的宽度,是第一行C和第二行d的乘积。

以下就是我们的实验结果,可以看到ResNeXt-50是优于ResNet50的
主要说明增加Cardinality和增加深度或宽度的区别,增加宽度就是简单地增加filter channels。第一个是基准模型,增加深度和宽度的分别是第三和第四个,可以看到误差分别降低了0.3%和0.7%。但是第五个加倍了Cardinality,则降低了1.3%,第六个Cardinality加到64,则降低了1.6%。显然增加Cardianlity比增加深度或宽度更有效。结果表明,增加基数可以提高模型的性能,且要比增加宽度和深度更有效。
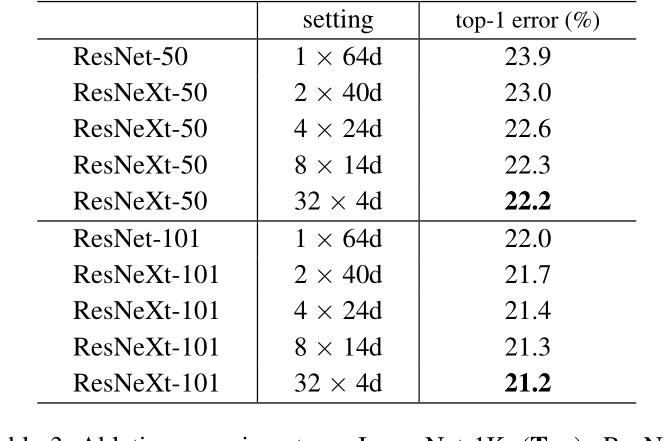
此外,模型还对基数(分支数)进行了对比试验。
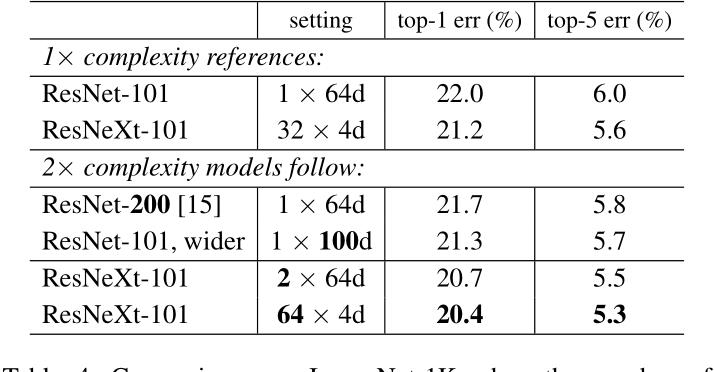
和当前最好的模型的对比
对我们会发现,虽然说ResNeXt与Inception差不多,但是有一个点很重要,计算效率和复杂性是大大高于我们的Inceptionv3的
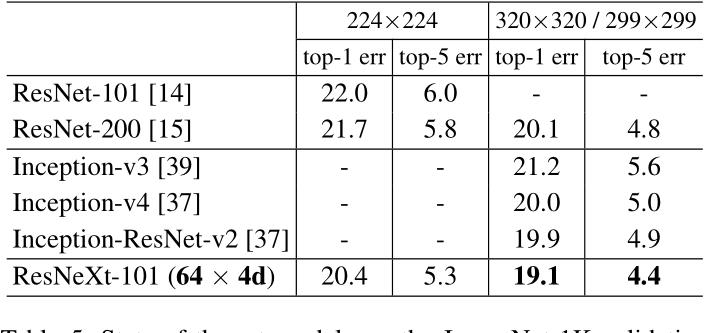
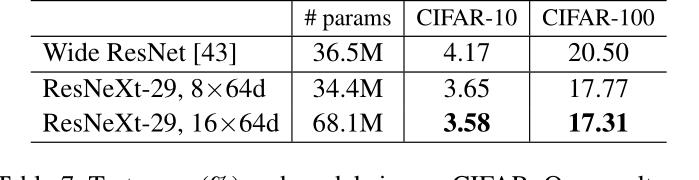
论文还在简单的CIFAR10数据集作了研究,模型还对比验证了残差结构的有效性,实验表明,在深层网络中引入残差结构,可以明显提高模型的性能
总结和感想
在这篇论文中,我觉得比较好的就是,ResNeXt虽然并没有提出一种很奇特的结构,而是在ResNet的基础上增加了分组卷积的方式。并且在保持模型参数变化不大的基础下进行的,最后的ResNeXt50与ResNet50参数相似,但是性能却是更好的。最后也拿了当时2016的ILSVRC的图像分类的第二名。
最后总结来说,作者的核心创新点就在于提出了 aggregrated transformations,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
Pytorch代码实现
最后附一下他的ResNeXt的pytorch实现吧,这是基于ImageNet的,并且是在ResNet上进行修改。
对于CIFAR10的是网络分类的实现,可以到时候关注我们图像分类篇进行一个添加学习
'''
ResNeXt in PyTorch.
See the paper "Aggregated Residual Transformations for Deep Neural Networks" for more details.
这一部分借鉴官方的实现方式,改ResNet进行训练
'''
from numpy import pad
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
# 最基础的Block的压缩为1,在ResNet18,34有效
expansion = 1
# downsample代表:是否进行下采样,或者说我们是否需要一个shortcut,也就是我们的下采样
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
# 首先是一个3x3的卷积层,这里的stride是我们设置的,因为对于我们的第一个卷积层,stride为2
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity # 进行残差连接
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
实验结果证明,这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
# 这里相对于简单的残差网络中多增加了两个参数,一个是groups和width_per_group,分别是组卷积的个数和每个组卷积的通道数
# 默认值就是正常的ResNet
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
# 这里也可以自动计算中间的通道数,也就是3x3卷积后的通道数,如果不改变就是out_channels
# 如果groups=32,with_per_group=4,out_channels就翻倍了
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
# 组卷积的数,需要传入参数
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
# -----------------------------------------
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity # 残差连接
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block, # 表示block的类型
blocks_num, # 表示的是每一层block的个数
num_classes=1000, # 表示类别
include_top=True, # 表示是否含有分类层(可做迁移学习)
groups=1, # 表示组卷积的数
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion # 得到最后的输出
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def ResNet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def ResNet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def ResNet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
# 论文中的ResNeXt50_32x4d
def ResNeXt50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def ResNeXt101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def test():
net = ResNeXt50_32x4d(num_classes=10)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
net = net.to(device)
# x = torch.randn(2,3,32,32).to(device)
# y = net(x)
# print(y.size())
from torchinfo import summary
print(summary(net,(1,3,224,224)))
test()
以上是关于深度学习--PyTorch维度变换自动拓展合并与分割的主要内容,如果未能解决你的问题,请参考以下文章
深度之眼PyTorch训练营第二期 ---2张量操作与线性回归