爬虫前提——正则表达式语法以及在Python中的使用
Posted Jian_99
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫前提——正则表达式语法以及在Python中的使用相关的知识,希望对你有一定的参考价值。
正则表达式是用来处理字符串的强大工具,他并不是某种编程云。
正则表达式拥有独立的承受力引擎,不管什么编程语言,正则表达式的语法都是一样的。
正则表达式的匹配过程
1.一次拿出表达式和文本中的字符比较。
2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有两次或便捷,这个过程会稍微有一些不同。
下面举例一些符号
[....]
字符集(字符类)。对应的位置可以是字符集中任意字符。字符集中的字符可以猪哥列出,也可以给出范围,如[abc]或[a-c]。第一个字符如果是^则表示取反,如果[^abc]表示不是abc的其他字符。所有的特殊字符在字符集中都是去某原有的特殊含义。在字符集中如果是用]、-或^,可以在前面加上转移字符反斜杠\\,或把]、-放在第一个字符,把^放在非第一个字符。
预定义字符集(可以写在字符集[....]中):
\\d 数字:[0-9]
\\D 非数字:[^\\d]
\\s 空白符:[<空格>\\t\\r\\n\\f\\v]
\\S 非空白符:[^\\s]
\\w 单词字符:[A-Za-z0-9_]
\\W 飞单词字符:[^\\w]
数量词(用在字符或(...)之后)
* 匹配前一个字符0或无限次
+ 匹配前一个次1次或无限次
? 匹配前一个次0次或1次
{m} 匹配前一个字符m次
{m,n} 匹配前一个字符m至n次(多于n次则失败)
m和n可以省略:若省略m,则匹配0至n次;若省略n,则匹配m至无限次
边界匹配(不消耗待匹配字符串中的字符)
^ 匹配字符串开头。在多行模式中匹配每一行的开头。
$ 匹配字符串末尾。在多行模时匹配每一行的末尾。
\\A 仅匹配字符串开头。
\\Z 仅匹配字符串末尾。
\\b 匹配\\w和\\W之间
\\B [^\\B]
逻辑、分组:
| 代表左右表达式任意匹配一个。(类比于C语言的或语句,它总是先匹配左边的表达式,一旦成功匹配则跳过匹配右边的表达式。如果|没有被包括在()中,则它的范围是整个正则表达式。)
(...) 被括起来的表达式将作为分组,从表达式左边开始没遇到一个分组的左括号\'(\',编号+1.另外,分数表达式作为一个整体,可以后街数量词。表达式中仅在该组中有效。
(?P<name>...) 分组,除了原有的编号外再指定一个额外的别名。
\\<number> 引用编号为<number>分组匹配到的字符串。
(?P=name) 引用别名为<name>的分组匹配到的字符串。
特殊构造(不作为分组):
(?:...) (...)的不分组版本,用于食用\'|\'或后接数量词。
(?iLmsux) iLmsux的每个字符代表一个匹配模式,只能用在正则表达式的开头,可选多个。
(?#...) #后的内容将作为注释被忽略。
(?=...) 之后的字符串内容需要匹配表达式才能成功匹配。不消耗字符串内容。
(?!...) 之后的字符串内容需要不匹配表达式才能成功匹配。不消耗字符串。
(?<=...) 之前的字符串内容需要匹配表达式才能成功匹配。不消耗字符串内容。
(?<!...) 之前的字符串内容需要不匹配表达式才能成功匹配。不消耗字符串内容。
(?(id/name)yes-pattern|no-pattern) 如果编号为id/别名为name的组匹配到字符串,则需要匹配yes-pattern,否则需要匹配no-=attern。[no-pattern]可省略。
数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。
贪婪模式:总是尝试撇皮尽可能多的字符;(Python里数量词默认是贪婪的)
非贪婪模式:总是尝试匹配尽可能少的字符。(在贪婪模式的*或+后加上?,就变成了非贪婪模式)
python中如何使用正则表达式
python中是通过一个叫"re"的包来支持正则表达式。
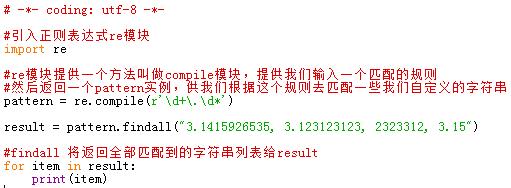
结果如下:

我们来分析一下pattern = re.compile(r\'\\d+\\.\\d*\') 这个语句:
\\d表示数字[0-9]
+表示重复出现上一次匹配的1次或n次
\\.表示字符‘.’
*表示重复出现上一次匹配的0次或n次
r实际上是python告诉编译器这个字符串中的全部转义字符失效,按照原始字符串处理。
所以\\d+.\\d*实际上是表示匹配一些小数的规则。然而这个表达式并不能正确匹配所有的小数,比如\'0.\'这样的字符也会被匹配,举这个例子纯粹是为了多讲几个符号。
由于我们已经建立好了一个能够匹配\'\\d+.\\d*\'规则的pattern对象。
通过pattern的findall方法就能够匹配到我们想要的字符串。
返回的是一个字符串列表[]。
以上是关于爬虫前提——正则表达式语法以及在Python中的使用的主要内容,如果未能解决你的问题,请参考以下文章