python爬虫入门
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫入门相关的知识,希望对你有一定的参考价值。
python爬虫入门(5)
正则表达式
文章目录
一.正则表达式
与一组字符串是等价关系

1.简介






2.语法

常用操作符

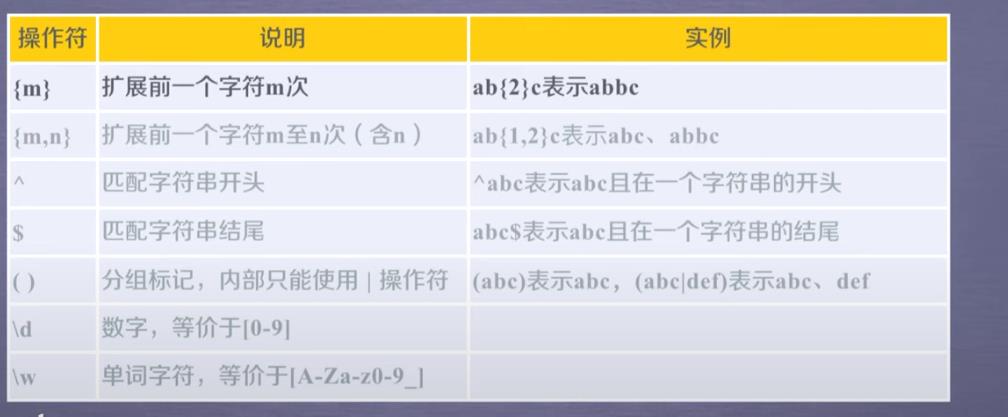
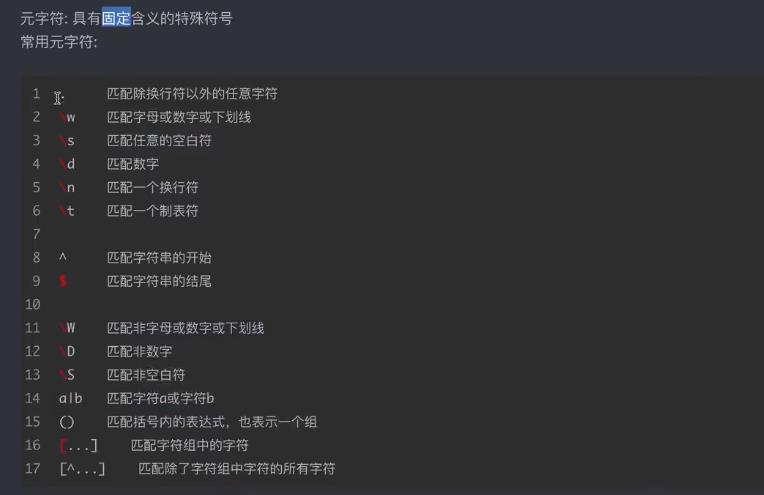
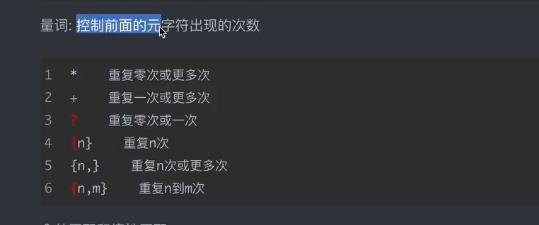
语法实例

经典正则表达式

匹配IP地址的正则表达式
粗略写法

精确写法


二.使用re模块
1.findall
查找所有,返回list
import re
lst=re.findall(r"\\d+","匪警请拨110,火警请拨119,急救中心请拨120")
# 在字符串前加r可防止字符串转义
print(lst)
运行结果
['110', '119', '120']
2.search
进行匹配,但是如果匹配到第一个结果,就会返回这个结果,若匹配不上就会返回None
拿到数据需要.group()
s= re.search(r"\\d+","匪警请拨110,火警请拨119,急救中心请拨120")
print(s.group())
运行结果
110
3.match
从字符串的开头进行匹配
s= re.match(r"\\d+","110匪警,火警请拨119,急救中心请拨120")
print(s.group())
运行结果
110
4.finditer
返回迭代器
# 预加载正则表达式
# 把正则提前加载好,之后直接用,且可以在多个地方使用
obj = re.compile(r"\\d+")
ret=obj.finditer("匪警请拨110,火警请拨119,急救中心请拨120")
for i in ret:
print(i.group())
ret2=obj.findall("s8j2das898")
print(ret2)
运行结果
110
119
120
['8', '2', '898']
5.正则中的内容单独提取
单独获取到正则中的内容可以给分组取名字
#(?P<分组名字>正则表达式) 可以单独从正则匹配到的内容中进一步提取内容
#Python三引号:多用作注释、数据库语句、编写 html 文本
s="""
<div class='u'><span id='00'>猫猫</span></div>
<div class='v'><span id='11'>小猫咪</span></div>
<div class='w'><span id='007'>喵喵</span></div>
<div class='x'><span id='0214'>咪咪</span></div>
"""
obj=re.compile(r"<div class='.*?'><span id='(?P<id>\\d+)'>(?P<cat>.*?)</span></div>",re.S)#re.S让.能匹配换行
result = obj.finditer(s)
for it in result:
# print(it.group()) #会把整个打印出来
print(it.group('id'))
print(it.group('cat'))
运行结果
00
猫猫
11
小猫咪
007
喵喵
0214
咪咪
.*?尽可能少的匹配


三.遇到的问题
1.吃一堑,未长一智
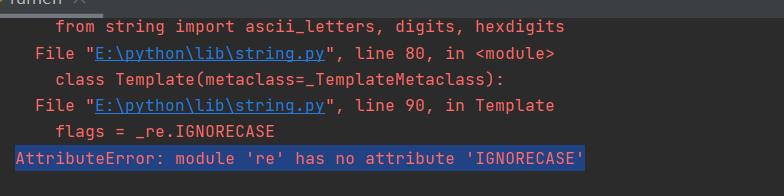
之前bs4犯过了的错误,不能用那些包来命名文件

以上是关于python爬虫入门的主要内容,如果未能解决你的问题,请参考以下文章