Selenium2+python自动化34-获取百度输入联想词
Posted jason89
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium2+python自动化34-获取百度输入联想词相关的知识,希望对你有一定的参考价值。
前言
最近有小伙伴问百度输入后,输入框下方的联想词如何定位到,这个其实难度不大,用前面所讲的元素定位完全可以定位到的。
本篇以百度输入框输入关键字匹配后,打印出联想词汇。
一、定位输入框联想词
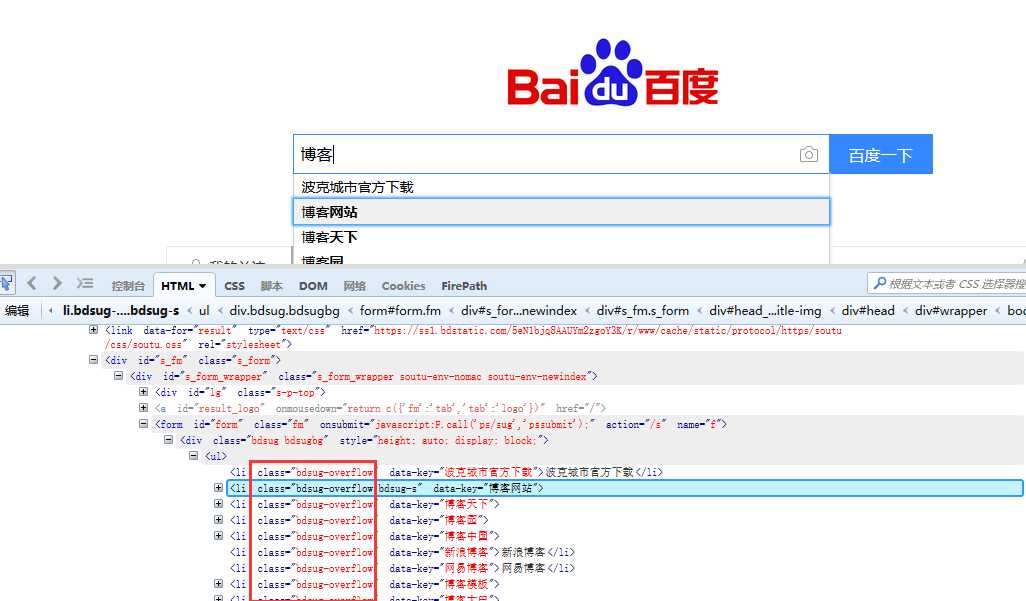
1.首先在百度输入框输入关键词,如:博客,然后输入框下方会自动匹配出关键词。
2.这时候可以用firebug工具定位到联想出来的词,可以看到下方匹配出来的词都有共同的class属性,这时候就可以全部定位到了。
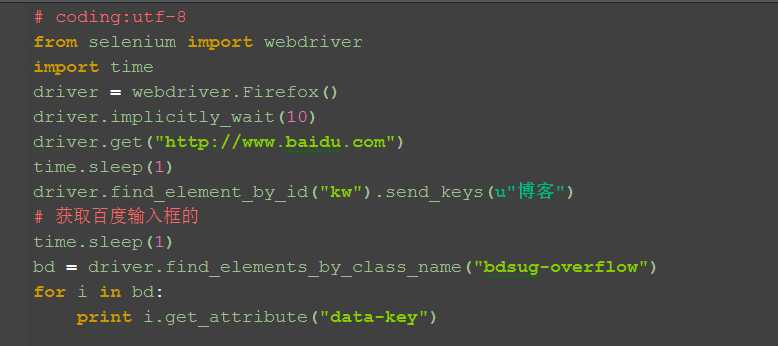
二、打印全部匹配出来的词
1.通过get_attribute()方法获取到文本信息
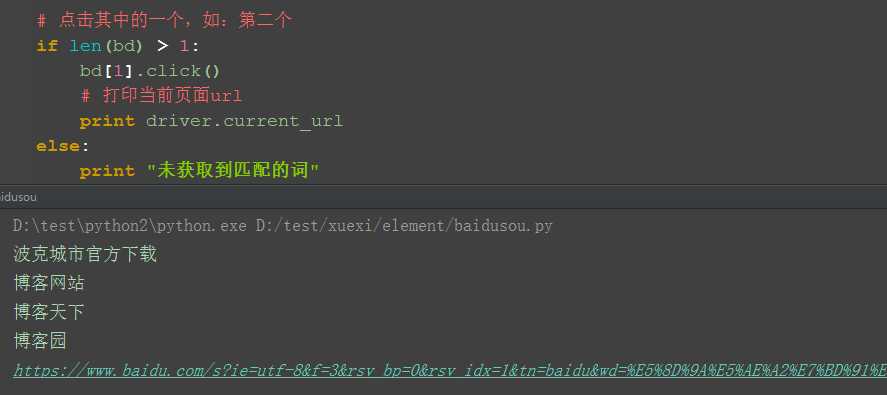
三、点击其中一个
1.点击其中的一个联想词,如:第二个
2.这里可以先加一个判断,如果获取到了就点击,没获取到就不点击了,以免抛异常。
(如果想依次点击,用for循环就可以了)
三、参考代码
# coding:utf-8
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
time.sleep(1)
driver.find_element_by_id("kw").send_keys(u"博客")
# 获取百度输入框的
time.sleep(1)
bd = driver.find_elements_by_class_name("bdsug-overflow")
for i in bd:
print i.get_attribute("data-key")
# 点击其中的一个,如:第二个
if len(bd) > 1:
bd[1].click()
# 打印当前页面url
print driver.current_url
else:
print "未获取到匹配的词"
以上是关于Selenium2+python自动化34-获取百度输入联想词的主要内容,如果未能解决你的问题,请参考以下文章
Selenium2+python自动化13-多窗口句柄(handle)
Selenium2+python自动化43-判断title(title_is)
Selenium2+python自动化43-判断title(title_is)