Selenium2+python自动化43-判断title(title_is)转载
Posted 小曹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium2+python自动化43-判断title(title_is)转载相关的知识,希望对你有一定的参考价值。
前言
获取页面title的方法可以直接用driver.title获取到,然后也可以把获取到的结果用做断言。
本篇介绍另外一种方法去判断页面title是否与期望结果一种,用到上一篇Selenium2+python自动化42-判断元素(expected_conditions)
提到的expected_conditions模块里的title_is和title_contains两种方法
一、源码分析
1.首先看下源码,如下
class title_is(object):
"""An expectation for checking the title of a page.
title is the expected title, which must be an exact match
returns True if the title matches, false otherwise."""
\'\'\'翻译:检查页面的title与期望值是都完全一致,如果完全一致,返回Ture,否则返回Flase\'\'\'
def __init__(self, title):
self.title = title
def __call__(self, driver):
return self.title == driver.title
2.注释翻译:检查页面的title与期望值是都完全一致,如果完全一致,返回True,否则返回Flase
3.title_is()这个是一个class类型,里面有两个方法
4.__init__是初始化内容,参数是title,必填项
5.__call__是把实例变成一个对象,参数是driver,返回的是self.title == driver.title,布尔值
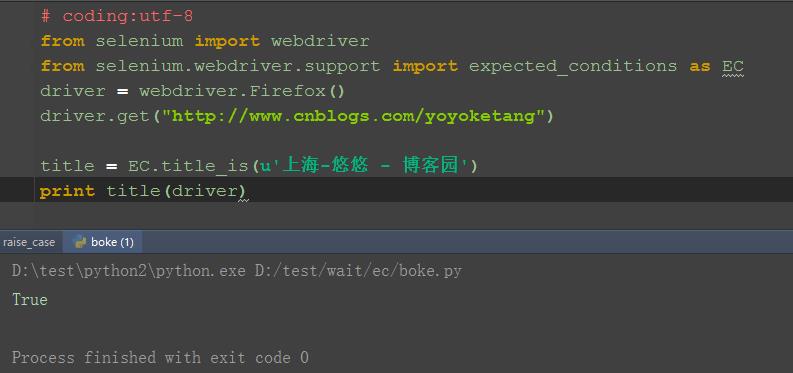
二、判断title:title_is()
1.首先导入expected_conditions模块
2.由于这个模块名称比较长,所以为了后续的调用方便,重新命名为EC了(有点像数据库里面多表查询时候重命名)
3.打开博客首页后判断title,返回结果是True或False
三、判断title包含:title_contains
1.这个类跟上面那个类差不多,只是这个是部分匹配(类似于xpath里面的contains语法)
2.判断title包含\'上海-悠悠\'字符串
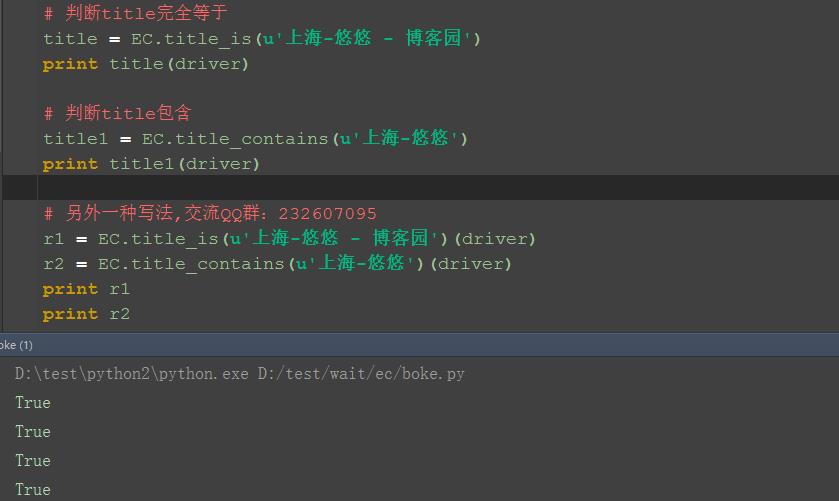
四、参考代码
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang")
# 判断title完全等于
title = EC.title_is(u\'上海-悠悠 - 博客园\')
print title(driver)
# 判断title包含
title1 = EC.title_contains(u\'上海-悠悠\')
print title1(driver)
# 另外一种写法,交流QQ群:232607095
r1 = EC.title_is(u\'上海-悠悠 - 博客园\')(driver)
r2 = EC.title_contains(u\'上海-悠悠\')(driver)
print r1
print r2
以上是关于Selenium2+python自动化43-判断title(title_is)转载的主要内容,如果未能解决你的问题,请参考以下文章
Selenium2+python自动化43-判断title(title_is)转载
Selenium2+python自动化42-判断元素(expected_conditions)